- The paper introduces EEG-MoCE, a novel framework that adaptively learns hyperbolic embeddings to capture hierarchical structures in cross-modal EEG data.
- It combines modality-specific Euclidean encoders with learnable-curvature hyperbolic experts and a curvature-guided attention mechanism for effective fusion.
- EEG-MoCE achieves significant accuracy improvements in emotion recognition, sleep staging, and cognitive assessments compared to state-of-the-art baselines.
Hyperbolic Mixture-of-Curvature Experts for EEG-Based Multimodal Learning
Introduction and Background
This paper introduces EEG-MoCE, a hyperbolic mixture-of-curvature experts framework specifically designed for cross-subject EEG-based multimodal learning (2604.12579). The central premise is that heterogeneous modalities (e.g., EEG, facial video, speech, peripheral physiological signals) involved in mental state assessment and neurotechnology exhibit hierarchical latent structure, which is inherently challenging to encode in standard (flat) Euclidean space. Hyperbolic embedding spaces, distinguished by their negative curvature and exponential volume growth, provide a geometrically principled means of representing hierarchies with lower distortion.
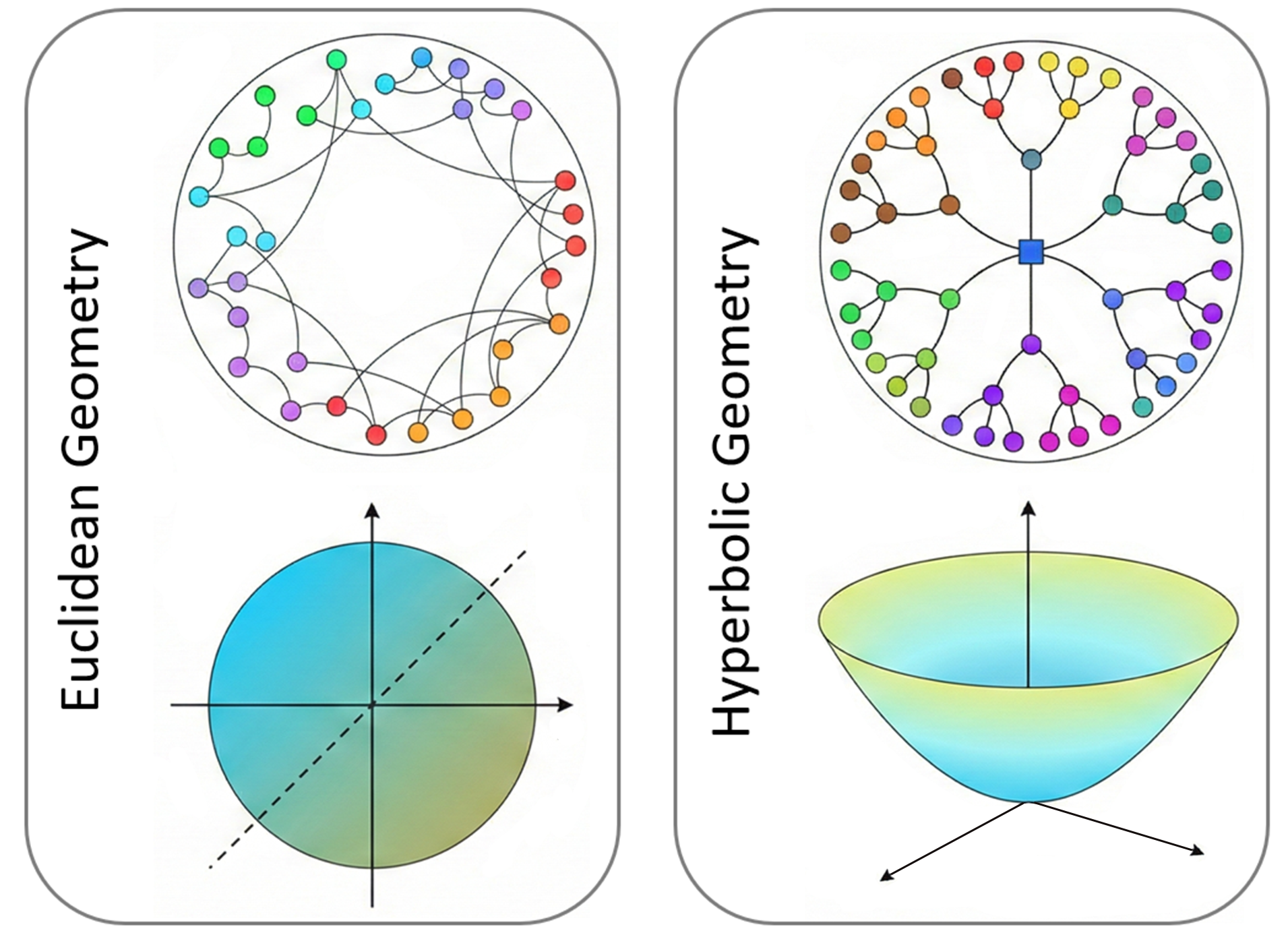
Figure 1: Euclidean vs.\ hyperbolic geometry for hierarchical data: Euclidean space under-represents branching; hyperbolic geometry preserves tree separation and is more suitable for modalities with pronounced hierarchies.
While previous approaches either leveraged standard Euclidean representations or, more recently, applied fixed-curvature hyperbolic mappings to single-modality EEG, there has not yet been a framework that 1) generalizes hyperbolic deep learning to the multimodal regime, 2) learns a separate curvature per modality to adaptively capture differing hierarchical complexity, and 3) fuses modalities in a manner explicitly guided by their learned geometry. EEG-MoCE combines core advances in hyperbolic geometry, Riemannian representation learning, and cross-modal fusion, resulting in impressive performance gains across emotion recognition, sleep staging, and cognitive assessment.
Methodology
Mixture-of-Curvature Expert Architecture
The EEG-MoCE architecture comprises modality-specific Euclidean encoders (e.g., EEGNet, CNNs, Transformers for audio/video), each followed by a learnable-curvature hyperbolic expert. Each expert projects features onto its unique Lorentzian manifold via the exponential map, where the curvature parameter K(m) for modality m is learned end-to-end. Modality-wise Lorentz batch normalization and nonlinearity maintain geometric consistency.
High-level cross-modal fusion is conducted on a shared fusion manifold whose curvature Kf is set as the mean of the per-modality curvatures, ensuring harmonized geometry. Critically, the cross-modal fusion employs a curvature-guided attention mechanism in which modalities with higher-magnitude negative curvature (reflecting increased hierarchical complexity) are weighted more heavily during aggregation. The full pipeline is implemented in PyTorch with careful Riemannian optimization for the manifold parameters.
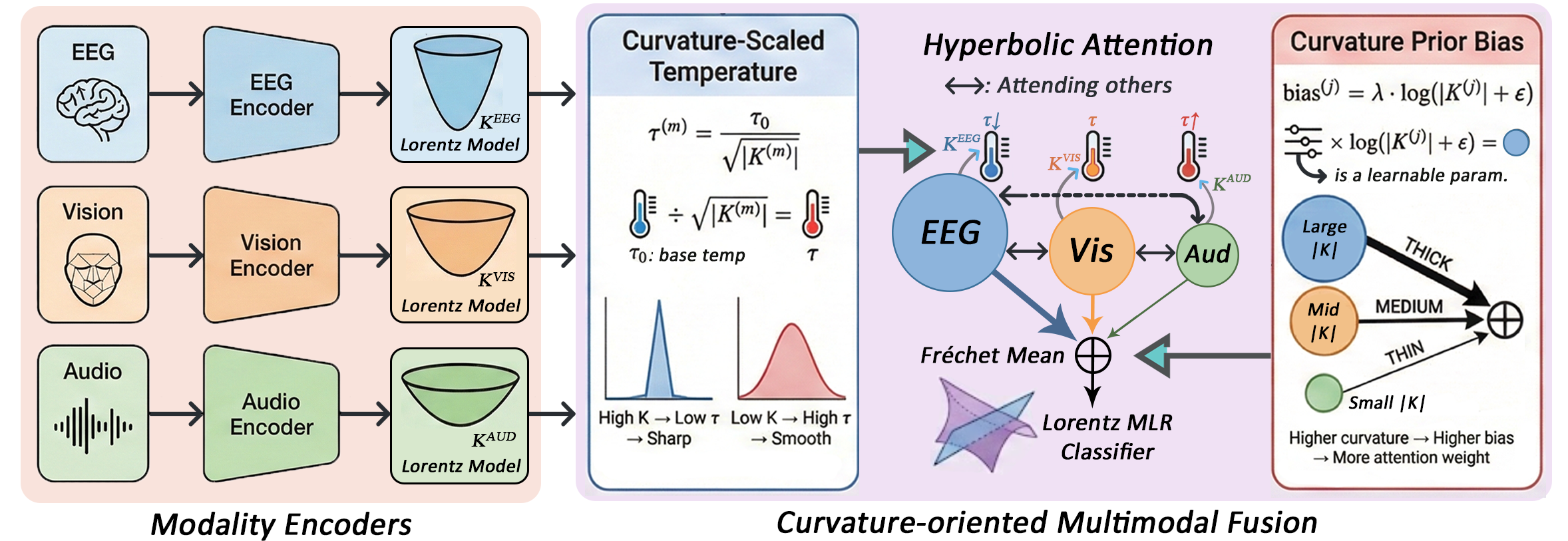
Figure 2: Architecture of EEG-MoCE showing modality-specific hyperbolic experts (with learnable curvature) and curvature-oriented fusion; the fusion mechanism leverages curvature as an indicator of hierarchy and guides attention accordingly.
Curvature-Guided Fusion
Fusion proceeds via multiple cross-modal attention layers, each employing a temperature parameter scaled by inverse curvature, yielding sharper distributions for highly hierarchical modalities. Further, a curvature prior term, parameterized by a learnable λ, introduces explicit preference towards inputs whose geometry suggests richer underlying structure. The attended features are aggregated on the manifold by the weighted Fréchet mean.
Projection between different curvature manifolds exploits log-exp maps with curvature-dependent scaling ensuring geodesic order is preserved. The final representation is passed through a Lorentzian fully connected layer and classified by hyperbolic multinomial logistic regression, where decision boundaries are geodesic hyperplanes in Lorentz space.
Analysis of Hierarchical Structure and Curvature Learning
Rigorous empirical analysis demonstrates that all modalities exhibit nontrivial hierarchical structure as assessed by diameter-normalized δ-hyperbolicity, calculated on both raw and encoded features. EEG, across datasets, consistently displays the lowest δrel, motivating its assignment of highest curvature magnitude during training.
The learned modality curvatures correlate directly with modal importance in fusion: the modality with the largest ∣K∣ receives the highest attention in the fusion stage, validating both the geometric interpretation of learned curvature as a proxy for hierarchy and the design rationale of curvature-guided fusion.
Experimental Results
The EEG-MoCE framework is evaluated on three multimodal benchmarks: EAV (EEG, Audio, Video; emotion recognition), ISRUC (EEG, EMG, EOG; sleep staging), and Cognitive (EEG, EOG, NIRS; working memory). Evaluation is performed in strict cross-subject regimes, with comparison against a comprehensive suite of modern baselines (including strong hyperbolic, multimodal, and domain adaptation methods).
Key numerical results:
- EAV: EEG-MoCE achieves 75.88% accuracy—markedly outperforming the previous best (61.74%; HEEGNet) by +14.14%.
- ISRUC: m0 accuracy, exceeding XSleepFusion (m1).
- Cognitive: m2 accuracy, with the best baseline at m3.
All improvements are statistically significant (m4).
Robustness analyses show low variance across random seeds; computational studies indicate increased but feasible GPU cost for hyperbolic processing.
Ablation Studies
Extensive ablations clarify the contribution of each architectural component:
- The combination of hyperbolic encoder and hyperbolic fusion yields the largest boost; each alone is beneficial, but their combination is strictly superior.
- Learnable (vs. fixed) curvatures provide an additional m5 accuracy gain, confirming the necessity of per-modality geometric adaptation.
- Curvature-oriented fusion outperforms pure hyperbolic attention, demonstrating that fusion informed by learned geometric indicators further enhances aggregation.
Single-modality experiments confirm that the multimodal fusion outperforms any individual expert or signal, and the highest-performing single modality (EEG) coincides with the highest curvature and fusion contribution.
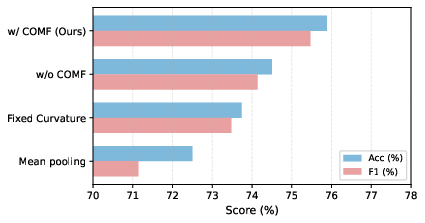
Figure 3: Ablation of hyperbolic components on EAV confirms that both learnable curvatures and curvature-oriented fusion mechanisms are complementary and necessary for best performance.
Geometric and Representational Insights
The proposed mixture-of-curvature design directly addresses the challenge of fusing modalities with heterogeneous and potentially mismatched inductive biases. Curvature serves as a low-dimensional, data-driven summary of hierarchical complexity that can be exploited for dynamic multimodal attention. The pipeline is shown empirically to preserve and even accentuate latent class structure as seen in t-SNE visualizations—hyperbolic processing yields tighter, more separable clusters than Euclidean baselines.
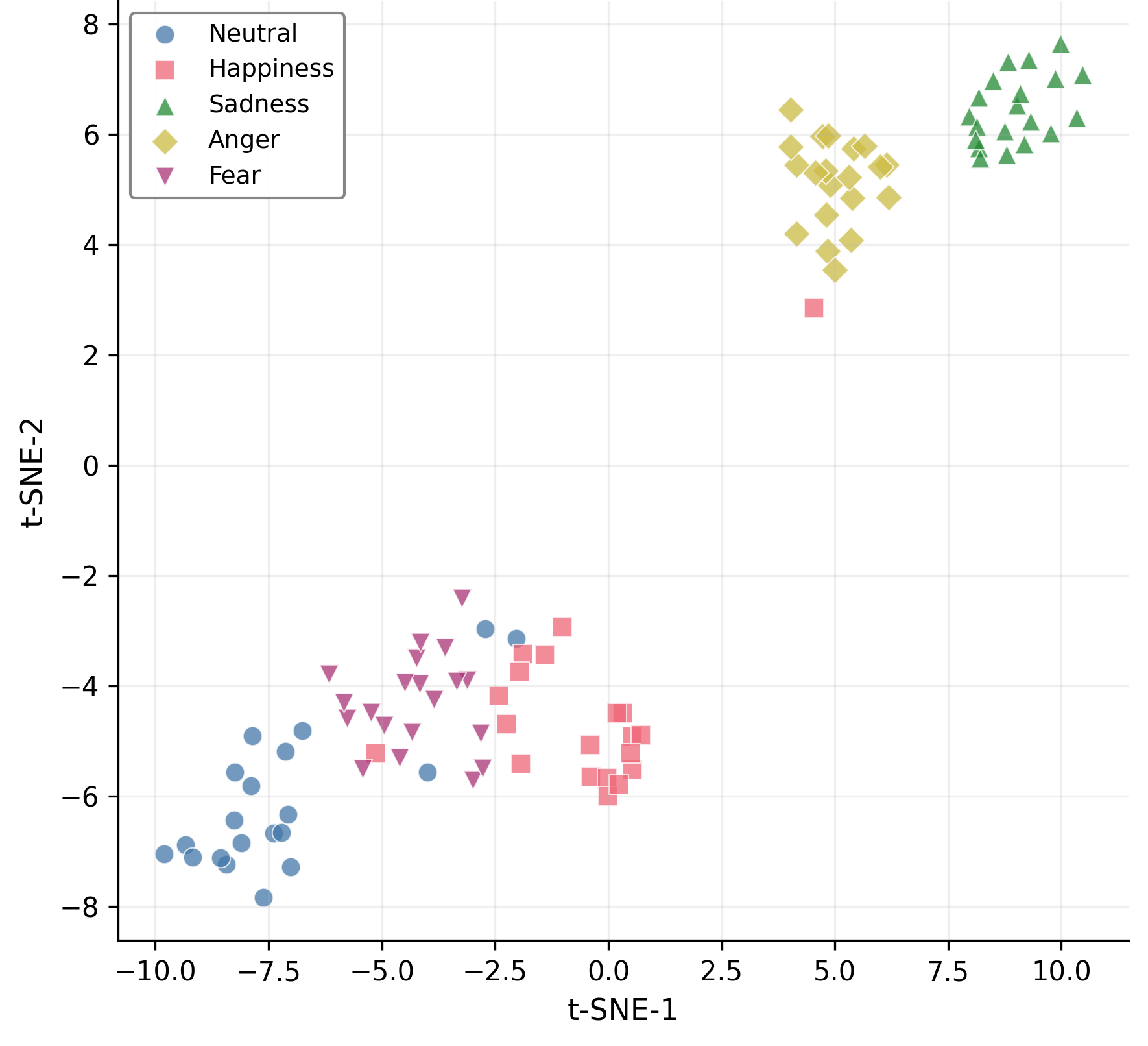
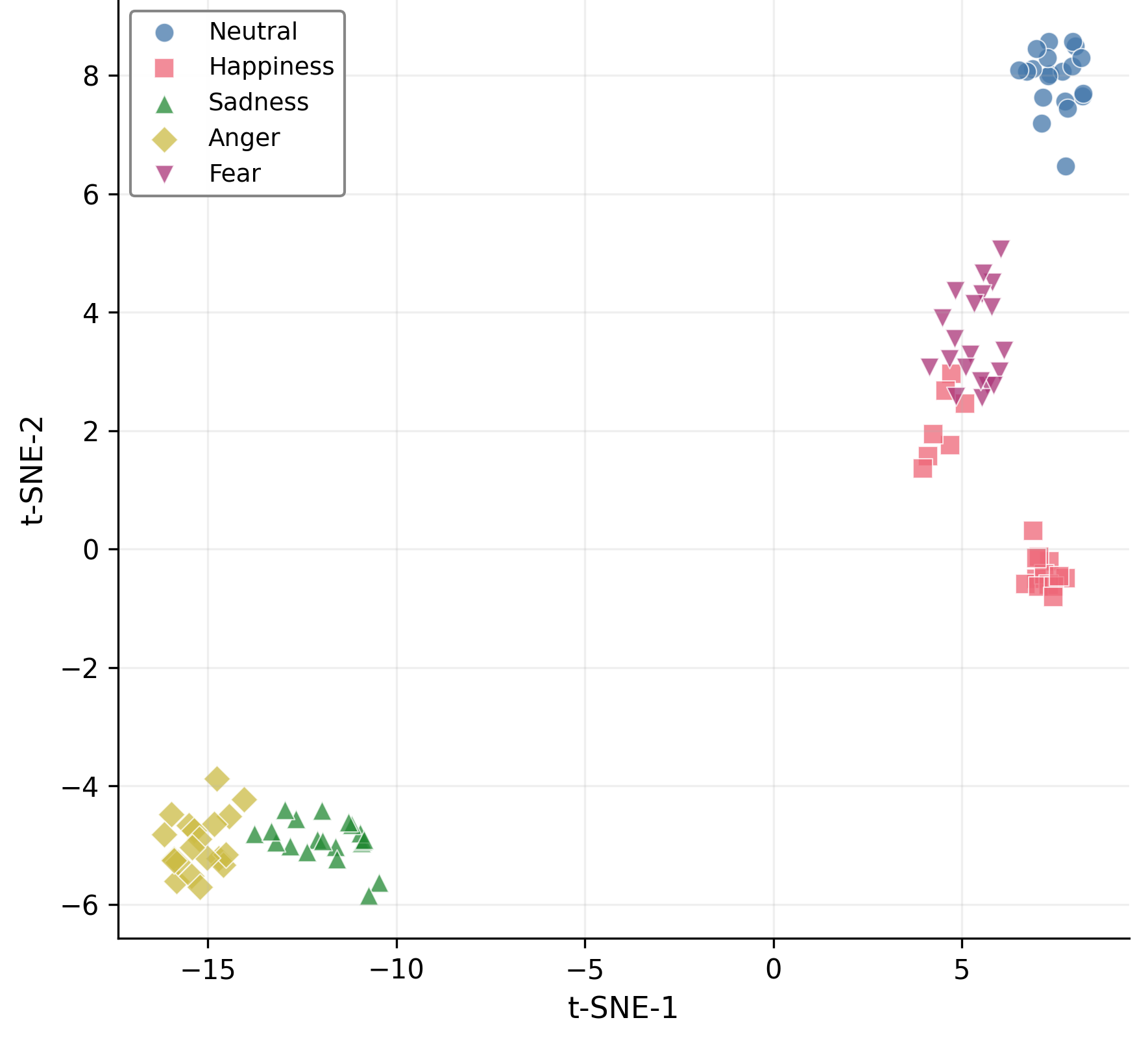
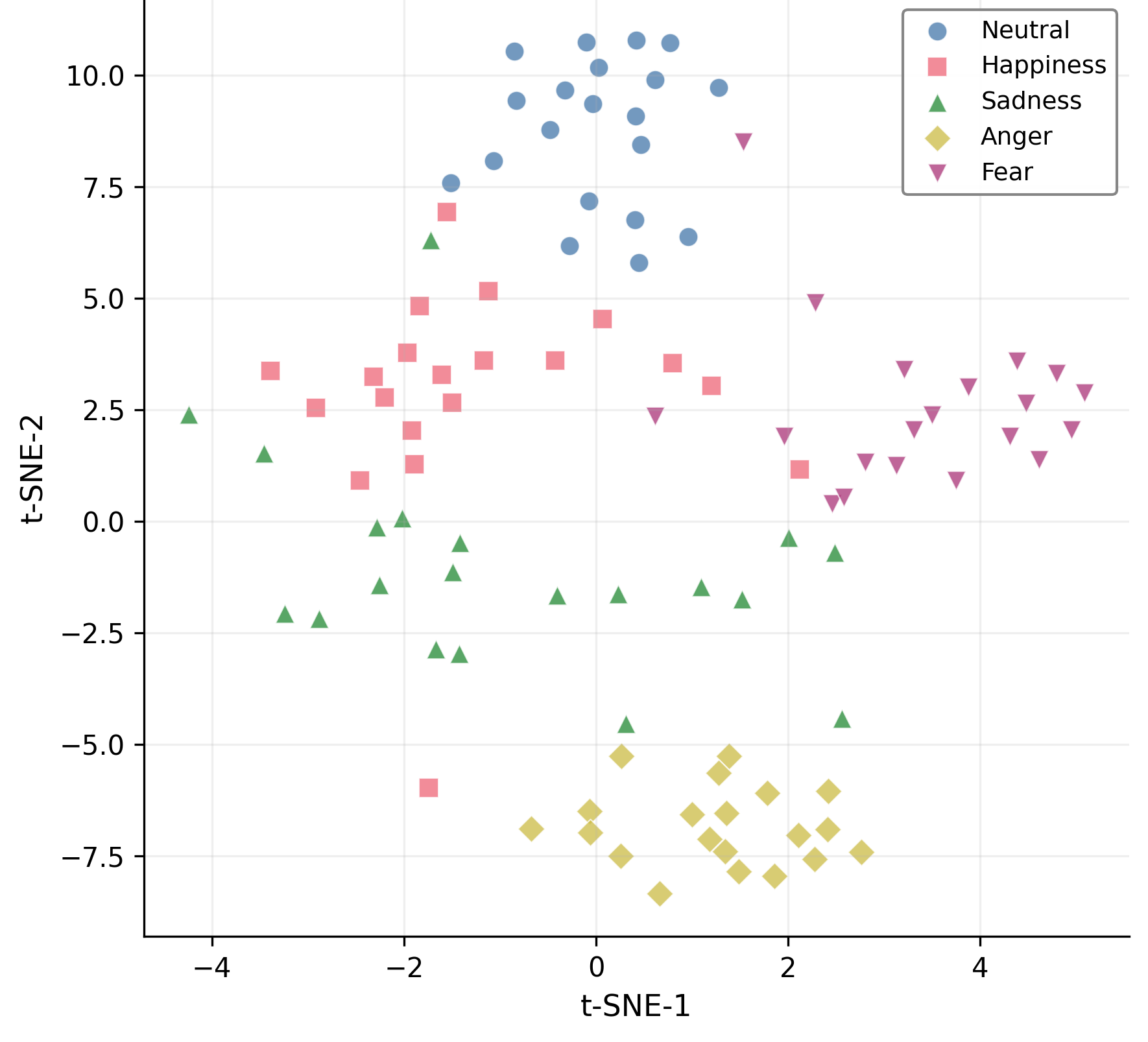
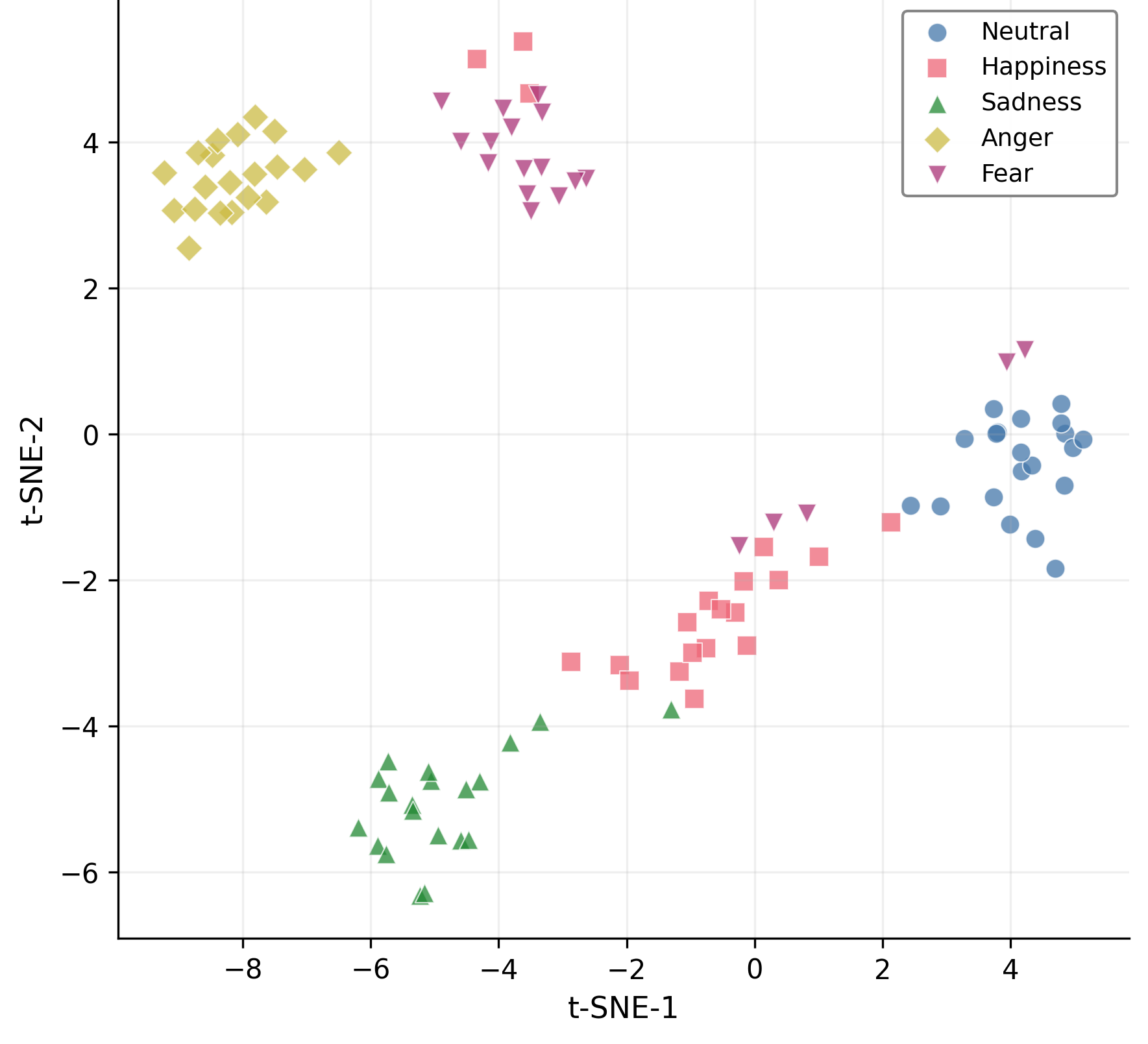
Figure 4: Hyperbolic embedding produces substantially improved separability in t-SNE visualizations compared to Euclidean encodings.
Theoretical and Practical Implications
The principal theoretical insight is that learnable curvature provides an elegant geometric parameterization for both explaining and leveraging inter-modality differences in structure, information content, and fusion requirements. In domains where underlying phenomena are inherently hierarchical (neurocognitive state, affect, behavior), controlling the geometry of encoders and fusers is beneficial.
Practically, EEG-MoCE's advances are significant for robust, deployable EEG-based affective computing, cognitive assessment, and clinical neurotechnology. Real-time latency remains reasonable, and the method generalizes seamlessly across problem settings. Given that curvature-adaptive fusion is modular, future extensions may target additional modalities, more expressive product-manifold fusion, or explicit interpretability pathways for uncovering neurobiological correlates of learned representations.
Conclusion
EEG-MoCE presents a highly robust, geometrically structured framework for EEG-based multimodal learning. By introducing per-modality learnable hyperbolic curvatures and curvature-guided cross-modal fusion, it achieves strong, statistically validated improvements over the state of the art on cross-subject emotion, sleep, and cognition benchmarks. The results illustrate both the value of explicit geometric modeling in deep learning for neurotechnology and the practical benefits of adaptive curvature as a foundation for cross-domain, cross-modality fusion.