- The paper demonstrates that imprecise probabilities improve uncertainty quantification by capturing both first- and second-order uncertainties in LLM outputs.
- The methodology uses probability intervals, credal sets, and possibility functions, validated through synthetic experiments and real-world QA evaluations.
- The approach enhances calibration, cost efficiency, and decision alignment, offering robust mechanisms for ambiguity detection and improved model selection.
Higher-order Uncertainty Quantification for LLMs via Imprecise Probabilities
Motivation and Limitations of Classical Uncertainty Elicitation
The quantification and verbalization of uncertainty in LLMs is central to applications such as hallucination detection, reasoning augmentation, agentic workflow control, and model selection. Empirical results reveal systematic failure modes of traditional uncertainty elicitation techniques, particularly in ambiguous QA, in-context learning, and self-reflection settings. Classical methods typically prompt LLMs for a single confidence estimate, assuming uncertainty can be reduced to a precise probability. In practice, such scores often exhibit poor discrimination between ambiguous and clear questions, fail to track prediction error improvements as more in-context examples are provided, and are misaligned with the model's decision rationale.
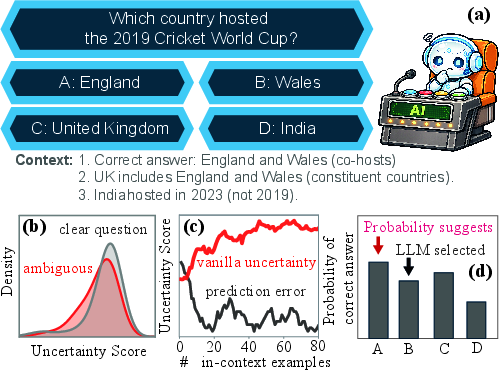
Figure 1: Prior uncertainty scores fail to reliably reflect ambiguity, error reduction, and decision rationales.
Imprecise Probabilities: A Principled Foundation
Imprecise Probabilities (IP) offer a more expressive mechanism for uncertainty quantification by capturing higher-order uncertainty. Within IP, first-order uncertainty models variability intrinsic to the question (e.g., multiple valid answers), while second-order or epistemic uncertainty quantifies indeterminacy in the underlying probability estimates.
Classical approaches produce point estimates, masking the underlying imprecision. IP techniques verbalize probability intervals, credal sets, or possibility functions, directly reflecting ambiguity, tracking predictive error, and aligning answer selection with rational decision-theoretic principles such as the maximin rule.
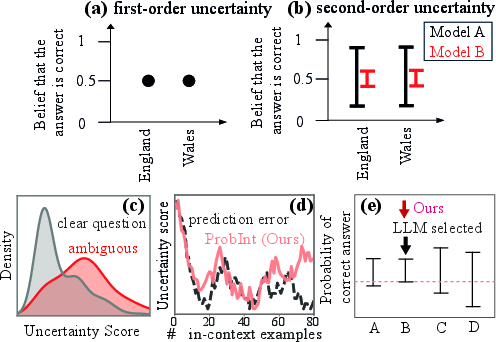
Figure 2: IP-based elicitation produces interval-valued beliefs that coherently reflect ambiguity, error, and decision alignment.
Methodology: Prompting and Post-processing for Higher-order Uncertainty
First-order Uncertainty
First-order uncertainty is elicited by directly prompting the model for betting prices across candidate answers, enforcing coherence with probability axioms via a probability-axiom verifier. This approach is grounded in de Finetti's subjective interpretation, directly operationalizable through prompt and algorithmic verification.
Second-order Uncertainty
Second-order uncertainty is elicited through three principal IP representations:
- Probability Intervals: Models provide lower and upper probabilities for each candidate, with intervals reflecting imprecision.
- Credal Sets: A group of models or multiple seeded runs yield a set of distributions, whose minimum and maximum values over answers define interval bounds.
- Possibility Functions: Plausibility scores for answers, including "none of the above," afford non-additive uncertainty measures robust to miscalibration.
Maximum Mean Imprecision (MMI) is utilized for post-processing, serving as a tractable scalar metric for second-order uncertainty. For an answer y, MMI reduces to the interval width. For sets of answers, task-level MMI aggregates uncertainty efficiently.
Synthetic Experiments: Disentanglement of First- and Second-order Uncertainty
A synthetic QA task with controlled ambiguity noise and varying in-context examples is used to dissect uncertainty disentanglement. Results show that vanilla and de Finetti scores scale linearly with first-order noise, whereas IP methods remain insensitive, confirming proper separation of uncertainty sources.
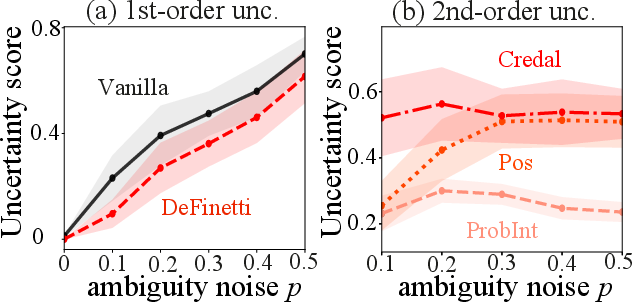
Figure 3: First-order noise is captured by vanilla/De Finetti, while IP scores remain constant for second-order uncertainty.
Varying the number of in-context examples demonstrates that IP-based scores decrease as error falls, fully reflecting epistemic denoising. In contrast, vanilla scores are invariant, failing to track predictive improvement.
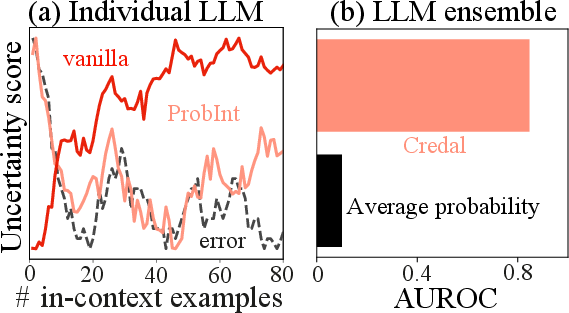
Figure 4: ProbInt-EU tracks prediction error under epistemic denoising; Credal-EU yields improved AUROC in ensemble settings.
Ensembles using credal sets capture cross-model disagreement, substantially improving AUROC for correctness versus utilitarian aggregation.
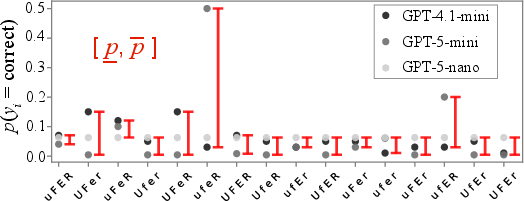
Figure 5: Credal sets aggregate ensemble member probabilities to construct interval bounds, used for MMI computation.
Real-world QA Evaluation: Ambiguity and Correctness Detection
On both ambiguous and non-ambiguous QA benchmarks, IP-based elicitation achieves robust separation of ambiguous from clear items and improved AUROC for correctness detection compared to sampling-based and classical verbalized baselines.
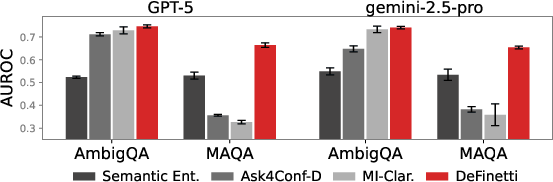
Figure 6: IP-based elicitation yields superior AUROC for ambiguity detection.
Combined scores from first- and second-order uncertainty estimates are multiplicatively integrated, producing robust improvement for correctness with ambiguity.
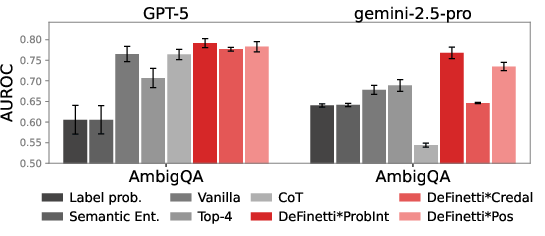
Figure 7: Joint uncertainty scores deliver enhanced AUROC for correctness under ambiguity.
API cost analysis shows that IP-based methods are more efficient than sampling-based methods and less expensive than approaches entailing uncertainty disentanglement via input clarification.
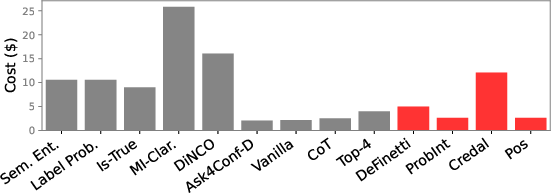
Figure 8: IP-based uncertainty elicitation is cost-effective relative to sampling and input-clarification ensembling.
Calibration and Decision Alignment
IP-based scores are strongly correlated with KL metric and exhibit high concordance with proxy uncertainty statistics derived from dataset answer distributions, outperforming classical and sampling-based methods across benchmarks.
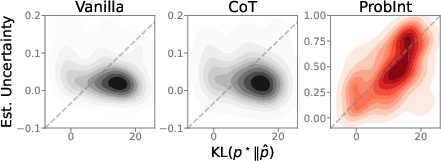
Figure 9: ProbInt uncertainty correlates closely with KL divergence from corpus answer distribution.
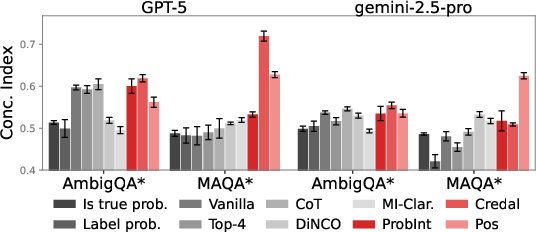
Figure 10: Concordance indices demonstrate strong alignment between IP-based uncertainty and ground-truth KL.
LLM predictions align most closely with the maximin rule derived from IP interval lower bounds, supporting decision-theoretic faithfulness of elicited interval scores.
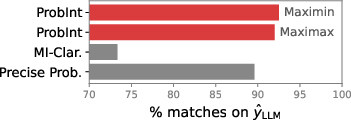
Figure 11: LLM answer selection best matches the IP-derived maximin decision rule.
Implications and Future Directions
The adoption of IP-based uncertainty quantification introduces a principled separation between aleatoric and epistemic sources in LLMs, remedying fundamental flaws in classical elicitation and calibration. Practical implications include improved credibility for downstream decision-making, robust ambiguity detection, cost-efficient uncertainty estimation, and alignment with rational action selection. The theoretical underpinnings of IP frameworks support advanced evaluation paradigms, ensemble disagreement analysis, and open-ended QA scenarios.
Speculation on future developments includes extending IP-based elicitation to domains beyond QA (e.g., translation, summarization), adapting to non-verbalized uncertainty settings, and exploring integration with RLHF and multi-agent LLM systems. Further study is warranted for multi-modal uncertainty, dynamic epistemic updating, and adversarial calibration.
Conclusion
IP-based verbal elicitation and MMI-driven post-processing provide a scalable and principled framework for higher-order uncertainty quantification in LLMs. Empirical evidence demonstrates improved calibration, internal consistency, ambiguity detection, correctness classification, and decision alignment, all in a cost-efficient manner. The approach establishes a rigorous foundation for both practical deployment and theoretical analysis of uncertainty in LLMs.