Calibrating Verbalized Confidence with Self-Generated Distractors
Abstract: Calibrated confidence estimates are necessary for LLM outputs to be trusted by human users. While LLMs can express their confidence in human-interpretable ways, verbalized LLM-generated confidence scores have empirically been found to be miscalibrated, reporting high confidence on instances with low accuracy and thereby harming trust and safety. We hypothesize that this overconfidence often stems from a given LLM's heightened suggestibility when faced with claims that it encodes little information about; we empirically validate this hypothesis, finding more suggestibility on lower-accuracy claims. Building on this finding, we introduce Distractor-Normalized Coherence (DINCO), which estimates and accounts for an LLM's suggestibility bias by having the model verbalize its confidence independently across several self-generated distractors (i.e. alternative claims), and normalizes by the total verbalized confidence. To further improve calibration, we leverage generator-validator disagreement, augmenting normalized validator confidence with a consistency-based estimate of generator confidence. Here, we frame the popular approach of self-consistency as leveraging coherence across sampled generations, and normalized verbalized confidence as leveraging coherence across validations on incompatible claims, allowing us to integrate these complementary dimensions of coherence into DINCO. Moreover, our analysis shows that DINCO provides less saturated -- and therefore more usable -- confidence estimates, and that further sampling alone cannot close the gap between DINCO and baselines, with DINCO at 10 inference calls outperforming self-consistency at 100.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Calibrating Verbalized Confidence with Self-Generated Distractors — Explained Simply
What is this paper about?
This paper looks at how LLMs say how confident they are in their answers. Sometimes these models say things like “I’m 95% sure,” but that number isn’t always reliable. The goal is to make these confidence scores better matched to reality, so people know when to trust the model.
The authors introduce a method called DiNCo (short for Distractor-Normalized Coherence) that helps fix overconfident and unhelpful confidence scores.
The main questions the paper asks
- Can we make a model’s spoken confidence (like “80% sure”) better match how often it’s actually correct?
- Why are models often overconfident, especially on things they don’t really know?
- Can we reduce “saturation,” where the model keeps saying super-high confidence (like 1.0) so often that the numbers become useless?
- Is there a way to combine two types of model behavior—what it writes vs. what it says about correctness—to get a better confidence score?
How the method works (in everyday language)
Key idea: Models can be “suggestible”
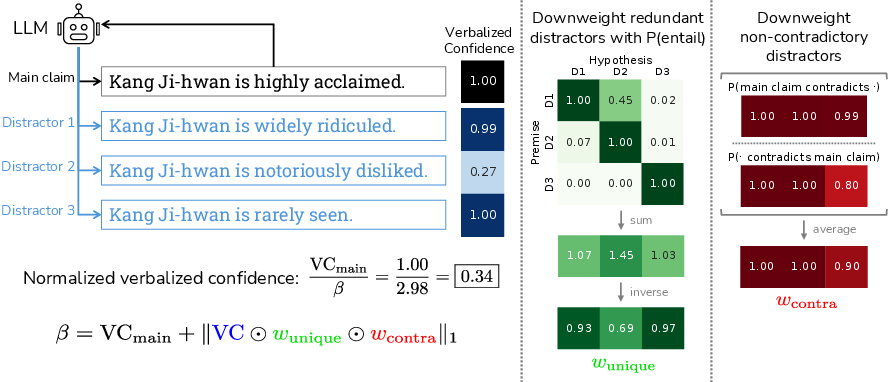
Imagine you ask, “Was Kang Ji-hwan born in 1980?” If the model doesn’t truly know, it might still say it’s pretty confident—partly because you asked about that exact year. If you then ask about 1990, it might also say it’s pretty confident. That’s not logical because both can’t be true. This tendency to be swayed by whatever is asked is called suggestibility.
DiNCo step-by-step
DiNCo tries to remove this suggestibility bias by comparing the model’s confidence across several alternative answers:
- Generate distractors:
- The model creates several alternative answers (distractors) to the same question. For example, if the question is about a birth year, it lists different possible years.
- This is like the model writing its own multiple-choice options.
- Ask for confidence separately:
- The model is asked, independently for each option, “How confident are you that THIS one is correct?”
- Doing it separately is important; it prevents the model from doing simple arithmetic to look consistent inside one prompt.
- Normalize the confidence:
- If the model says it’s quite confident in many conflicting options, that means it’s being suggestible.
- So DiNCo “shrinks” the main answer’s confidence by dividing it by the total confidence given to all the alternatives. Intuition: if you’re confident in everything, you shouldn’t be treated as very confident in any one thing.
- Avoid double-counting similar answers:
- Sometimes distractors are basically the same (e.g., “born in 1980” vs. “born in early 1980”).
- The method uses a separate, standard tool (an NLI model) to detect when two statements are similar or contradictory, so it doesn’t overcount near-duplicates or non-contradictions.
- Combine two kinds of “coherence”:
- Generation coherence (self-consistency): If you ask the model to answer several times and it keeps giving the same answer, that’s a good sign.
- Validation coherence (normalized verbalized confidence): If the model’s confidence makes sense when compared across conflicting claims, that’s also a good sign.
- DiNCo blends both signals: it averages the “how often do I generate this?” and the “how confident am I, after normalization?” to get a stronger, more reliable confidence score.
Think of it like a student who:
- Writes the same answer multiple times when asked in different ways (generation consistency), and
- Gives a confidence score that still looks sensible even when other tempting-but-wrong choices are around (validation consistency).
What did they test and how?
The authors evaluated DiNCo on:
- Short-answer questions (TriviaQA and SimpleQA), like trivia facts.
- Long-form writing (biography generation), where they checked each claim inside the text using a tool called FActScore.
They compared DiNCo to common alternatives:
- Verbalized confidence (just asking “How sure are you?”).
- Self-consistency (asking multiple times and seeing how often the same answer appears).
- Maximum sequence probability (how likely the model was to produce its answer).
- A few variations that combine these ideas.
They measured:
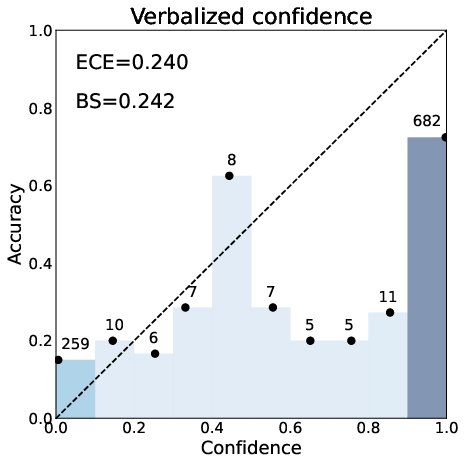
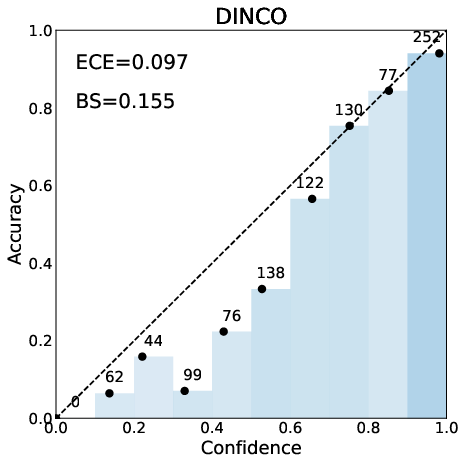
- Calibration (Does “80% sure” mean right about 8 out of 10 times? Lower ECE and Brier score = better.)
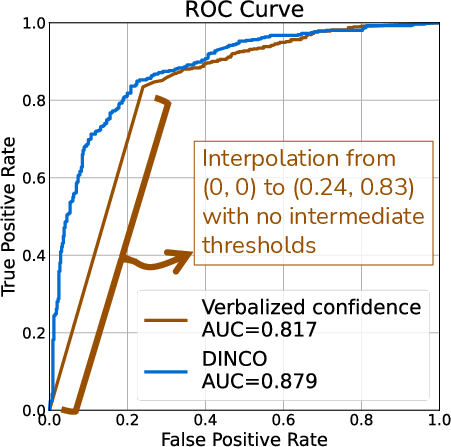
- Ranking quality (AUC: Can the method put true answers above false ones more often? Higher = better.)
- For long-form: correlation with actual factuality (do higher confidences line up with more factually correct passages? Higher Pearson/Spearman = better).
Main findings and why they matter
Here are the key takeaways:
- DiNCo is better calibrated:
- Across datasets and models, DiNCo’s confidence numbers match reality more closely than the baselines.
- It often reduces ECE (a main calibration error measure) the most.
- It reduces “saturation”:
- Plain verbalized confidence often clumps near 1.0, which isn’t helpful. DiNCo spreads scores out more, giving finer control over when to trust or reject an answer.
- It beats simple scaling:
- Even when the self-consistency method is run 10× more times (more samples), it still doesn’t reach DiNCo’s performance. This means DiNCo’s advantage isn’t just about asking more—it’s about asking smarter.
- It works on short and long answers:
- In long biographies, DiNCo’s confidence scores line up better with the actual proportion of true claims in the text.
- It improves correlation with FActScore (meaning higher confidence actually means more correctness).
- The NLI step matters:
- Removing the “similarity/contradiction” check makes performance notably worse. That check helps keep normalization fair and accurate.
Why this matters: Better calibration means safer and more trustworthy AI. If a model knows when it might be wrong, people and AI systems can decide when to double-check, ask a human, or refuse to answer—reducing harmful mistakes.
What could this change in the real world?
- Safer assistance: Systems can more reliably flag uncertain answers, which helps in healthcare, education, and legal contexts where guessing is risky.
- Smarter AI agents: Agents can decide when to search, ask for help, or abstain if confidence is low after DiNCo normalization.
- Better human-AI teamwork: Clearer, more honest confidence signals make it easier for people to judge when to trust the model.
In short, DiNCo helps LLMs be less “easily swayed,” more self-aware about uncertainty, and more honest about how sure they really are—so users get confidence numbers they can actually use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of missing, uncertain, or unexplored aspects that future work could address to strengthen and extend this paper’s claims.
- Validity of the shared-bias assumption: The core normalization relies on assuming a common bias factor β(C) across logically related claims. There is no empirical test of when this assumption holds or breaks, nor a diagnostic to detect per-claim deviations from β(C) ≈ β(c).
- Exhaustiveness and exclusivity of distractor sets: The method presumes the chosen distractors are sufficiently exhaustive and largely mutually exclusive; coverage and exclusivity are not quantified, and failure modes when distractors miss plausible alternatives or overlap semantically are not characterized.
- Sensitivity to distractor generation strategy: The impact of beam search versus pseudo-beam versus black-box list generation on calibration is not systematically analyzed, including how diversity/quality of distractors affects β(C) estimates and downstream metrics.
- NLI dependency and robustness: The approach critically depends on an off-the-shelf NLI model to weight uniqueness and contradiction, but there is no sensitivity analysis to NLI model choice, calibration of NLI probabilities, domain/length mismatch (short vs. long claims), or cross-lingual settings.
- Thresholding and weighting choices in NLI gates: The specific forms of w_unique and w_contra (including averaging, denominator form, and any thresholds) are heuristic; their effect on calibration, AUC, and saturation is not ablated beyond “on/off.”
- Inadequate handling of ambiguous or multi-answer questions: The framework assumes binary truth and mutually exclusive claims; how DiNCo behaves on questions with multiple correct answers, partial credit, ranges (dates/quantities), or inherently ambiguous statements is not evaluated.
- Defaulting via max(1, β(C)) may bias estimates: The fallback to max(1, β(C)) is ad hoc; its effect on under/over-normalization, especially when the distractor set is sparse or mis-specified, is not analyzed.
- Generator–validator mixture weight fixed at 0.5: The equal weighting of self-consistency and normalized verbalized confidence is not justified or tuned; there is no exploration of instance-adaptive or learned weights that might better reconcile generator–validator disagreement.
- No principled uncertainty propagation: Confidence aggregation across generation and validation is heuristic; there is no formal treatment of uncertainty propagation, nor guarantees that the combined estimator is a proper scoring rule or strictly improves calibration under defined conditions.
- Limited causal evidence for “suggestibility”: Preliminary evidence links higher β(C) to incorrect answers, but causal tests (e.g., controlled context manipulations, adversarial insertions, prior-strength interventions) to isolate suggestibility effects are missing.
- Prompt-format sensitivity: While both Yes/No and numeric verbalizations are mentioned, a systematic study of prompt styles, templates, and instruction strength on saturation and calibration (including long-form settings) is absent.
- Black-box setting performance and techniques: The black-box variant underperforms the logit-access version, but there is no exploration of stronger distractor generation without logits (e.g., external generators, retrieval-augmented distractors, diverse decoding strategies) to close the gap.
- Scalability and compute cost profiling: The method increases inference calls (generation + validation + NLI); there is no detailed budget-versus-benefit analysis across tasks, nor strategies to amortize or reduce cost (e.g., dynamic K, early stopping, reuse of NLI judgments).
- Generalization beyond QA and biographies: The approach is tested on short-form QA and long-form biographies; its applicability to code generation, instruction following, RAG, multi-hop reasoning, multi-modal tasks, or safety-critical domains remains unverified.
- Impact on downstream decision-making: The paper shows improvements in ECE/AUC/Brier and correlation with FActScore, but does not evaluate utility in abstention, triage, or risk-sensitive deployment (e.g., expected utility under thresholding, user trust outcomes).
- Human-grounded evaluation limits: Correctness assessment relies on LLM-as-a-judge with human spot checks; broader human evaluation (diverse annotators, adversarial/ambiguous cases, claim decomposition errors) to validate calibration improvements is limited.
- Topic/domain fairness and bias: There is no analysis of calibration across topical strata (e.g., underrepresented entities, temporal drift, contested facts), nor whether DiNCo reduces or amplifies domain-specific biases.
- Cross-lingual and non-English claims: The reliance on English NLI and prompts limits generalization; the method’s calibration in other languages and mixed-language contexts is unexplored.
- Robustness to adversarial prompts or gaming: It is unclear how DiNCo behaves when the model generates distractors strategically (e.g., high-confidence contradictions) that could artificially deflate normalized confidence or induce incoherence.
- Interaction with retrieval and knowledge updates: The method does not consider retrieval-augmented generation or dynamic knowledge changes (temporal drift); whether distractor normalization complements or conflicts with external evidence is an open question.
- NLI probability calibration: The paper treats NLI outputs as probabilities in weighting, but does not calibrate or validate their probabilistic fidelity; miscalibrated NLI could systematically skew β(C).
- Self-consistency scaling and trade-offs: While scaling SC alone doesn’t match DiNCo, the trade-off space of increasing distractors versus SC samples versus NLI precision (and their interactions) remains unexplored.
- Instance-wise diagnostics: There is no tooling to flag cases where β(C) appears unreliable (e.g., extremely large tails, high redundancy), nor guidance on abstaining from normalization when diagnostics fail.
- Theoretical guarantees on saturation reduction: Although DiNCo reduces saturation empirically, there is no theoretical characterization of when normalization produces better granularity without harming calibration.
- Applicability to classification and multiple-choice tasks: The method is framed for claims/QA; its adaptation and performance on standard classification/MC benchmarks (with label sets and priors) is not tested.
- Bin sensitivity of ECE: ECE is computed with 10 bins; sensitivity to binning, adaptive binning, or alternative calibration diagnostics (e.g., reliability diagrams, proper scoring rules beyond Brier) is not examined.
Glossary
- Area Under the ROC Curve (AUC): A performance metric that summarizes a classifier’s ability to rank positives above negatives across all thresholds. "area under the ROC curve"
- Beam search: A heuristic decoding algorithm that keeps the top-k partial sequences at each step to efficiently explore high-probability generations. "We generate minimal pair distractors using beam search when available"
- Black-box setting: An evaluation or usage scenario where only textual inputs and outputs are available, with no access to internal model signals like logits. "black-box settings with only textual input and output"
- Brier score: A proper scoring rule measuring the mean squared error between predicted probabilities and actual outcomes. "Brier score"
- Confidence saturation: The tendency of reported confidence scores to cluster into a few bins (often high), reducing granularity and usefulness. "confidence saturation, wherein the model's reported scores tend to fall into a few bins, making them uninformative."
- Distractor: An alternative, plausibly competing claim used to test coherence and calibrate confidence. "self-generated distractors (i.e. alternative claims)"
- Distractor-Normalized Coherence (DiNCo): The proposed method that normalizes verbalized confidence over distractors and integrates self-consistency for improved calibration. "DiNCo normalizes by the total confidence over candidate answers"
- Entailment: A logical relation where one statement implies another; used with NLI to detect redundancy among claims. "We use an NLI model to quantify entailment and contradiction relationships between claims."
- Epistemic humility: The recognition (by a system) of its own uncertainty, reflected in low confidence on uncertain instances. "we first observe that many incorrect answers are assigned a confidence near 0, suggesting epistemic humility."
- Epistemic uncertainty: Uncertainty arising from limited knowledge about a claim or topic. "Some studies indicate that when LLMs are epistemically uncertain"
- Expected Calibration Error (ECE): A metric quantifying the mismatch between predicted confidence and empirical accuracy across bins. "Expected Calibration Error (ECE)"
- FActScore: A framework that decomposes long-form text into atomic claims and verifies each against a knowledge source to measure factuality. "FActScore decomposes a generated biography into atomic claims"
- False positive rate (FPR): The proportion of negative instances incorrectly classified as positive at a given threshold. "false positive rate (FPR) of 0.24."
- Generator-validator inconsistency: The phenomenon where a model’s most likely generations differ from what the same model later validates as most probable or correct. "generator-validator inconsistency, wherein a model may produce inconsistent results between the generation and validation stages."
- Gray-box setting: A usage scenario with partial internal access (e.g., logits) enabling richer confidence estimation than pure black-box use. "gray-box settings with logit access"
- LLM-as-a-judge: An evaluation approach where an LLM assesses the correctness of outputs, often used to obtain labels or scores. "We use LLM-as-a-judge to evaluate binary correctness"
- Maximum sequence probability (MSP): The probability assigned by the model to its generated sequence; used as a confidence proxy. "Maximum sequence probability (MSP)"
- Mutual exclusivity: A relationship where two claims cannot both be true at the same time. "mutually exclusive"
- Natural Language Inference (NLI): The task of determining whether one statement entails, contradicts, or is neutral with respect to another. "we use an off-the-shelf NLI model"
- Normalization factor β(C): The sum of confidences (appropriately weighted) over distractors used to debias and normalize the main claim’s confidence. "the normalization factor ( in \cref{eq:mutually-exclusive-nvc})"
- Pseudo-beam search: An API-based approximation to beam search that leverages top token probabilities instead of full logit access. "we use top token probabilities if available to implement a pseudo-beam search"
- Self-consistency: A method that samples multiple generations and uses agreement among samples as a confidence estimate. "we frame the popular approach of self-consistency as leveraging coherence across sampled generations"
- Semantic equivalence: A relation indicating that two answers express the same meaning; used to cluster or match sampled outputs. "we use an NLI model to determine semantic equivalence."
- Suggestibility: The tendency of an LLM to increase confidence in a claim simply because it appears in the prompt context, especially when unsure. "We refer to this phenomenon as suggestibility"
- Top-K prompting: A technique prompting the model to produce its top K candidate answers (often with reported confidences). "Top- prompting"
- True positive rate (TPR): The proportion of positive instances correctly identified at a given threshold. "true positive rate (TPR)"
- Verbalized confidence: Confidence expressed by the model in natural language or via explicit yes/no validation probabilities. "verbalized confidence is a simple and commonly-used approach that prompts the model to report its confidence in an answer"
Practical Applications
Practical Applications of “Calibrating Verbalized Confidence with Self-Generated Distractors (DiNCo)”
Below are actionable, real-world applications derived from the paper’s findings and methods. Each item indicates sector(s), potential tools/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Confidence calibration middleware for LLM products
- Sectors: software, platform, general industry
- What: Wrap any LLM with a post-hoc DiNCo layer that returns an answer, a calibrated confidence score, and an abstain/route-to-human signal. Works in gray-box (with logits) and black-box (prompt-only) settings; integrates with existing inference stacks.
- Tools/Workflow:
- Claim extraction (short- or long-form), distractor generation (beam/pseudo-beam or prompt-generated), NLI-based reweighting, verbalized confidence normalization, optional self-consistency sampling, confidence logging.
- API output schema: {answer, dinco_score, thresholded_abstain, distractors, explanation/log}.
- Assumptions/Dependencies: Access to an NLI model (off-the-shelf), tolerance for ~5–10 extra inference calls, token-probabilities optional (improves performance), latency budget.
- Human-in-the-loop triage and escalation
- Sectors: customer support, legal ops, healthcare intake, finance operations
- What: Use DiNCo to triage which interactions require human review based on calibrated claim-level or answer-level confidence, reducing false positives due to verbalized overconfidence.
- Tools/Workflow: Confidence thresholds per claim; red/yellow/green highlighting; queue prioritization and audit logs.
- Assumptions/Dependencies: Thresholds tuned to domain risk; staff capacity to handle escalations; clear UI to avoid over-trust.
- Safer long-form content generation with claim-level flags
- Sectors: marketing, newsrooms, technical writing, knowledge management
- What: During article/brief/biography drafting, decompose generated text into atomic claims (FActScore-style), apply DiNCo per claim, and highlight low-confidence statements for revision or citation requirement.
- Tools/Workflow: Claim extraction → distractor generation → NLI weighting → DiNCo score → editor UI with confidence overlays.
- Assumptions/Dependencies: Robust claim extraction for the genre; acceptable latency in editorial pipelines.
- RAG routing and citation control
- Sectors: enterprise search, legal, healthcare knowledge retrieval
- What: Use DiNCo to decide when to (a) abstain and expand retrieval, (b) enforce citation requirements for low-confidence claims, or (c) suppress finalization until evidence is found.
- Tools/Workflow: DiNCo score as a gating function to trigger RAG re-query, source expansion, or stricter citation filters.
- Assumptions/Dependencies: Retrieval system availability; cost/latency tolerance; citation quality checks.
- Model risk dashboards and calibration monitoring
- Sectors: model governance, safety, MLOps
- What: Operationalize ECE, Brier score, AUC, and the paper’s saturation metric Δε to monitor reliability over time and across domains; detect confidence saturation regressions.
- Tools/Workflow: Scheduled eval jobs; cohort analysis; drift detection; alerting when DiNCo vs. SC vs. VC diverge.
- Assumptions/Dependencies: Representative eval sets; governance buy-in to treat calibration as a KPI.
- Active learning and data labeling prioritization
- Sectors: ML data operations
- What: Use DiNCo to identify low-confidence or inconsistent claims for targeted human labeling, accelerating dataset curation where model is suggestible/uncertain.
- Tools/Workflow: Labeling queue sorted by low DiNCo; feedback loop to improve retrieval, prompts, or fine-tunes.
- Assumptions/Dependencies: Labeling budget; pipeline to incorporate labels.
- Safer coding assistants
- Sectors: software engineering
- What: Present DiNCo-calibrated confidence on code completions, comments, and suggested refactors; block or require review for low-confidence edits.
- Tools/Workflow: Extract atomic “claims” (e.g., type/contract assertions), compute DiNCo, enforce review gates in IDE/CI.
- Assumptions/Dependencies: Lightweight claim extraction for code assertions; latency budgets in IDEs.
- Customer-facing confidence UX for assistants
- Sectors: consumer apps, productivity tools
- What: Replace raw verbalized confidence with DiNCo-calibrated scores and brief coherence-aware explanations that avoid overclaiming.
- Tools/Workflow: Show calibrated bars, alternative plausible answers, and “why we’re unsure” notes based on distractor incoherence.
- Assumptions/Dependencies: Thoughtful UX to prevent misinterpretation and overreliance.
- Compliance-oriented abstention policies
- Sectors: finance, healthcare, legal, sensitive domains
- What: Set DiNCo thresholds below which the system must abstain or route to a human, aligning with internal controls and audit trails.
- Tools/Workflow: Policy rules tied to DiNCo scores per domain/entity; auto-documentation of decisions and distractors considered.
- Assumptions/Dependencies: Policy framework; documentation requirements; regulator acceptance of calibrated metrics.
- Benchmarking and academic evaluation
- Sectors: academia, research labs
- What: Add DiNCo as a standard baseline in calibration papers; use Δε saturation metric to better capture score granularity; examine generator–validator disagreement.
- Tools/Workflow: Public code integration; reproducible configs across TriviaQA/SimpleQA/FActScore-like tasks.
- Assumptions/Dependencies: Access to models tested; agreement on calibration metrics.
Long-Term Applications
- End-to-end calibrated agentic systems
- Sectors: autonomous agents, enterprise workflows
- What: Use DiNCo at every reasoning/decision node to choose tools, branch plans, or halt/seek human input; integrate into tool-use policies and multi-step planning.
- Tools/Workflow: Node-level DiNCo gating, dynamic inference budgets (e.g., more distractors when uncertain), auditability.
- Assumptions/Dependencies: Orchestration frameworks that can adapt inference budgets; cost-effective scaling.
- Training-time integration of coherence constraints
- Sectors: model training, foundation model providers
- What: Bake distractor-normalization and coherence objectives into fine-tuning or RL (reducing suggestibility-driven overconfidence), aligning generation and validation heads.
- Tools/Workflow: Multi-objective training (generator/validator distributions), synthetic distractor corpora, consistency losses.
- Assumptions/Dependencies: Access to model weights; compute; careful handling to avoid underconfidence.
- Domain-specialized NLI and claim extraction
- Sectors: healthcare, law, finance, scientific R&D
- What: Replace general NLI with domain NLI to better detect redundancy/contradiction; use domain claim schemas (e.g., clinical assertions, legal holdings, financial metrics).
- Tools/Workflow: Fine-tuned NLI; domain ontologies; schema-guided claim extraction.
- Assumptions/Dependencies: High-quality annotated corpora; regulatory validation in high-stakes domains.
- Multi-modal calibrated confidence
- Sectors: robotics, AVs, medical imaging, industrial inspection
- What: Extend DiNCo to vision/audio/sensor inputs by generating distractors (counterfactual hypotheses) and applying cross-modal contradiction checks.
- Tools/Workflow: Multi-modal NLI/entailment; distractor generation for perceptual hypotheses; agent safety controllers.
- Assumptions/Dependencies: Mature cross-modal entailment models; real-time constraints.
- Standard-setting and policy adoption
- Sectors: public policy, procurement, standards bodies
- What: Embed calibrated confidence requirements (ECE/AUC/Δε targets) into procurement guidelines, compliance checklists, and model cards; require abstention rules tied to calibrated scores.
- Tools/Workflow: Certification audits; standardized reporting of DiNCo settings (K, sampling, NLI); sector-specific thresholds.
- Assumptions/Dependencies: Consensus on metrics; regulator familiarity with calibration; cost-benefit analysis for SMEs.
- Marketplaces for confidence-aware model routing
- Sectors: AI platforms, cloud
- What: Route each query to the model with the best DiNCo-adjusted confidence-cost tradeoff; offer “confidence SLAs” for enterprise tenants.
- Tools/Workflow: Cross-model DiNCo scoring; portfolio optimization (cost, latency, calibrated AUC); usage analytics.
- Assumptions/Dependencies: Access to multiple models; robust black-box DiNCo performance without logits.
- Proactive misinformation mitigation and content moderation
- Sectors: social platforms, news, public health
- What: Use DiNCo to downrank or flag low-confidence claims in user-generated content summaries; require stronger evidence before amplification.
- Tools/Workflow: Summarization → claim extraction → DiNCo → moderation thresholds; transparency panels for flagged claims.
- Assumptions/Dependencies: Platform policy alignment; handling adversarial prompt/circumvention attempts.
- Safety in code-autonomy and DevOps
- Sectors: software, DevOps, SRE
- What: Gate automated rollouts, config changes, or remediation actions behind DiNCo thresholds on generated plans and assertions (e.g., dependency risk, blast radius).
- Tools/Workflow: CI/CD policy checks; staged rollouts when confidence is high; enforced human approval otherwise.
- Assumptions/Dependencies: Reliable claim extraction for infra tasks; careful choice of confidence thresholds.
- Scientific discovery assistants with calibrated hypotheses
- Sectors: pharma, materials, climate science
- What: Propose hypotheses with calibrated confidence and self-generated counter-hypotheses; prioritize experiments where model is both confident and coherent.
- Tools/Workflow: Hypothesis generation → DiNCo scoring → experiment ranking; lab notebook integrations.
- Assumptions/Dependencies: Domain NLI; integration with structured experiment planning; acceptance of model-assisted prioritization.
- Education and assessment at scale
- Sectors: education, edtech
- What: Tutors that signal uncertainty at a concept/step level and present plausible distractors to deepen learning; assessments that score both correctness and calibration.
- Tools/Workflow: Step-wise DiNCo on explanations; UI that encourages student reflection on distractor space; calibration-aware grading rubrics.
- Assumptions/Dependencies: Age-appropriate UX; careful messaging to avoid confusing learners.
Cross-cutting dependencies and risks
- Cost/latency: DiNCo typically uses ~10 inference calls; dynamic budgeting and caching help.
- Black-box limits: Without token probabilities, calibration improves but may trail gray-box performance.
- NLI reliability: Off-the-shelf NLI may struggle with specialized jargon; domain NLI mitigates this.
- Assumption of localized bias: DiNCo assumes similar suggestibility across related claims; severe violations reduce gains.
- Adversarial prompts: Attackers might craft distractors to manipulate normalization; require guardrails.
- Human factors: Confidence presentation can mislead; careful UI, training, and threshold setting are essential.
These applications build directly on the paper’s core innovations: independent verbalized confidence across self-generated distractors, NLI-based redundancy/contradiction weighting, and integration with self-consistency to reduce overconfidence and saturation while improving calibration and downstream decision quality.
Collections
Sign up for free to add this paper to one or more collections.

