- The paper introduces VisPrompt, which leverages image-grounded semantics and FiLM-based modulation to mitigate label noise in prompt learning.
- The paper employs an optimal transport-driven approach to partition training data, enhancing robustness by using reliable supervision signals.
- The paper demonstrates state-of-the-art accuracy on benchmarks with minimal parameter overhead, ensuring resilient performance even at high noise levels.
Robust Vision-Guided Cross-Modal Prompt Learning under Label Noise
Introduction and Motivation
Label noise poses a persistent bottleneck for parameter-efficient adaptation in vision-LLMs (VLMs), particularly in the prompt learning paradigm where only a small set of context tokens are optimized atop a frozen backbone. Due to the limited capacity of prompt parameters, noisy supervision leads to pronounced drift in learned class representations and degrades generalization. Although prior work has explored label noise tolerance via label-side approaches (e.g., robust loss design, noisy-sample reweighting), the primary semantic signal—image content—remains underutilized as an anchor for prompt updates.
The paper "Seeing is Believing: Robust Vision-Guided Cross-Modal Prompt Learning under Label Noise" (2604.09532) proposes VisPrompt, a robust framework that explicitly leverages image-grounded semantics to regularize prompt learning under noisy annotation. The framework introduces a cross-modal conditioning pipeline and instance-adaptive FiLM-based modulation to control the amount of visual evidence injected into textual prompts, thereby mitigating the undue influence of corrupted labels.
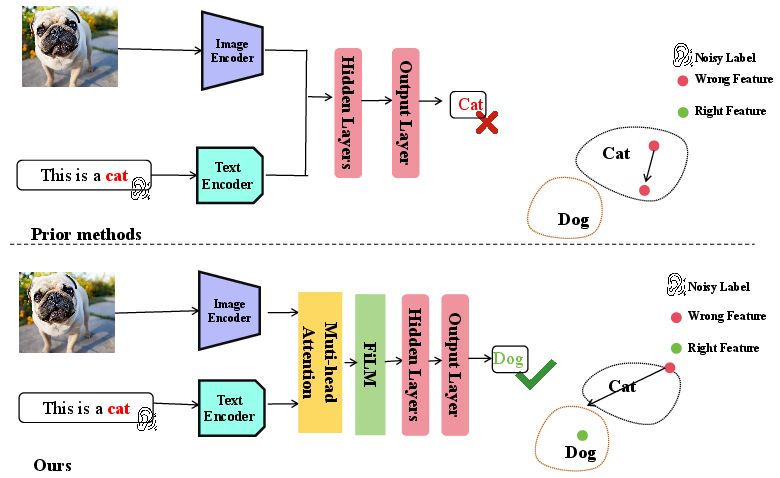
Figure 1: Prior label-driven prompt methods can be misled by noisy supervision and produce incorrect predictions, while VisPrompt injects reliable image-grounded information to guide prompt learning toward the correct class.
Cross-Modal Prompt Optimization Pipeline
VisPrompt comprises two principal modules: cross-modal prompt conditioning and FiLM-based adaptive modulation. The forward pipeline can be summarized in four stages: learnable context initialization, visual feature projection, cross-modal interaction, and adaptive visual gating.
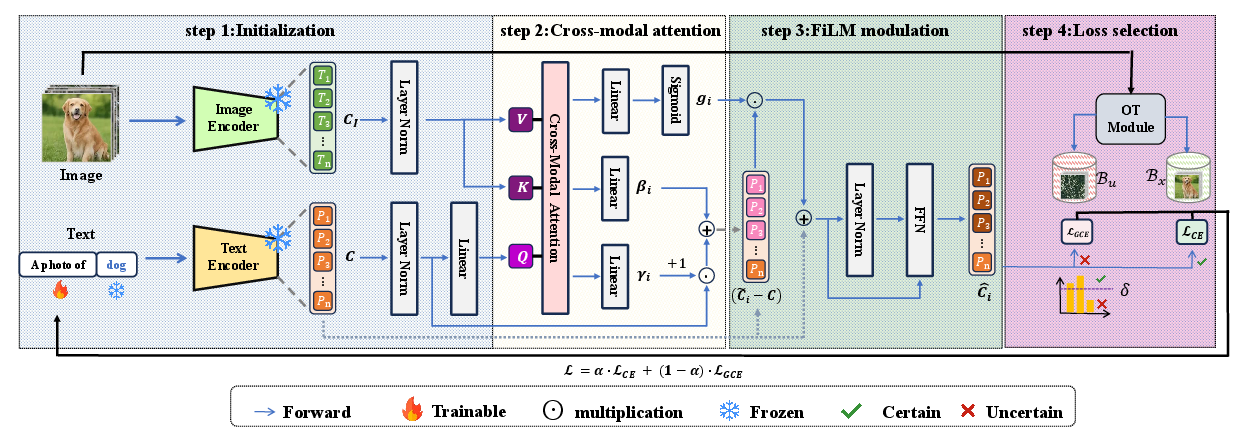
Figure 2: The overall architecture of VisPrompt which consists of four steps. Step 2 and Step 3 denote the robust update process.
Context Initialization: The framework instantiates nctx learnable prompt tokens, either class-shared or class-specific, residing in the text embedding space connected to the frozen text encoder.
Visual Feature Projection: For each input, local visual features are extracted from the image encoder, linearly projected into the context token space using a lightweight learnable matrix, enabling semantic alignment.
Cross-Modal Conditioning: Multi-head cross-attention (context tokens as queries, visual tokens as keys/values) aggregates salient visual cues relevant to each context token. The resulting attended features are then leveraged to regularize prompt representations for sample-specific adaptation.
FiLM-based Modulation: Instance-adaptive Feature-wise Linear Modulation (FiLM) learns to selectively adjust (scale and shift) each context token's embedding dimensions conditioned on the attended visual features. A token-wise gate further adaptively weights the integration, mitigating overshoot and unwanted drift induced by unreliable visual cues.
These modules operate with minimal added parameter overhead (<1%), preserving the parameter efficiency central to prompt learning.
Robust Loss Partitioning and Optimization
VisPrompt integrates an optimal transport-driven sample reliability estimation to bifurcate the training set into reliable and noisy subsets. The optimal transport plan, computed over the image-text similarity matrix, yields a soft pseudo-label distribution and a per-sample confidence score. Standard cross-entropy loss is applied to reliable samples, while the unreliable subset receives generalized cross-entropy to suppress memorization of corrupted annotations. The robust loss is a convex combination of the two terms, weighted by a tunable α parameter.
Theoretical Analysis of Robustness
The cross-modal pipeline is formally analyzed via a Lipschitz stability perspective. Under mild assumptions—existence of informative visual tokens close to clean class semantics; attention able to discriminate such tokens; FiLM being Lipschitz continuous—it is shown that the deviation of the adapted prompt from the (hypothetical) clean ground-truth is tightly controlled by the quality of projected visual evidence and the attention margin over irrelevant cues. The instance-level gating of modulation prevents noisy supervision from producing excessive drift, ensuring that as long as the clean logit margin is sufficiently large, the final prediction remains stable under label noise.
Experimental Results
VisPrompt is benchmarked against CoOp, GCE, JoAPR, and NLPrompt across six standard datasets with synthetic symmetric and asymmetric noise, and Food101N with genuine web-scale label errors. Results show consistent improvements in accuracy across all noise levels and datasets, typically outperforming the strongest baseline (NLPrompt) by 2–10 points, and maintaining graceful degradation at extreme (up to 75%) noise regimes.
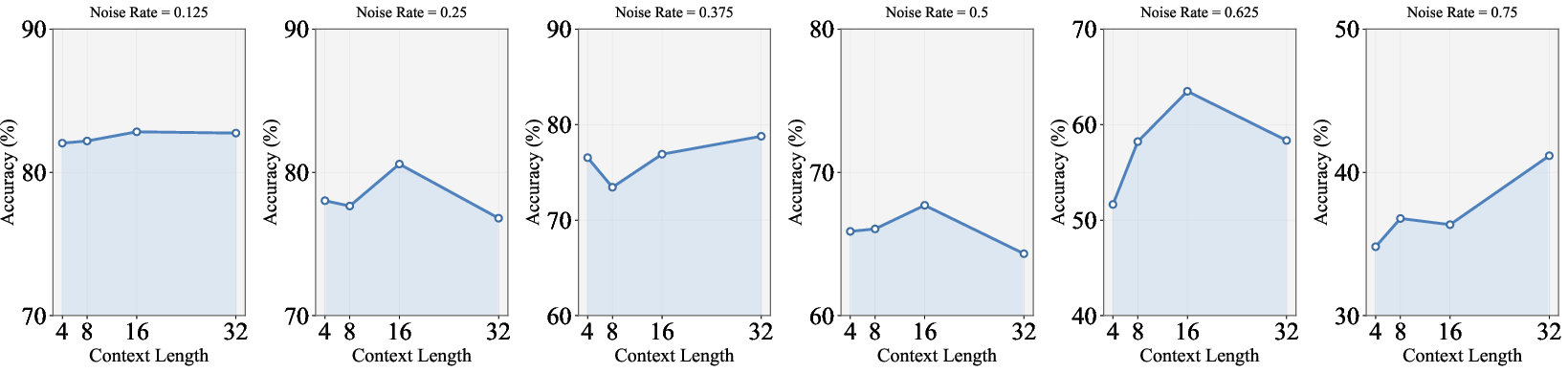
Figure 3: Test accuracy (\%) under different context token lengths, showing robust performance across a broad range of prompt sizes.
Ablation Studies
Ablation on EuroSAT demonstrates the necessity of both image guidance and FiLM gating. Image guidance without modulation provides only marginal gains, while the FiLM gate confers clear robustness, especially in high-noise scenarios. The additional parameter cost from FiLM remains negligible (0.3% of total).
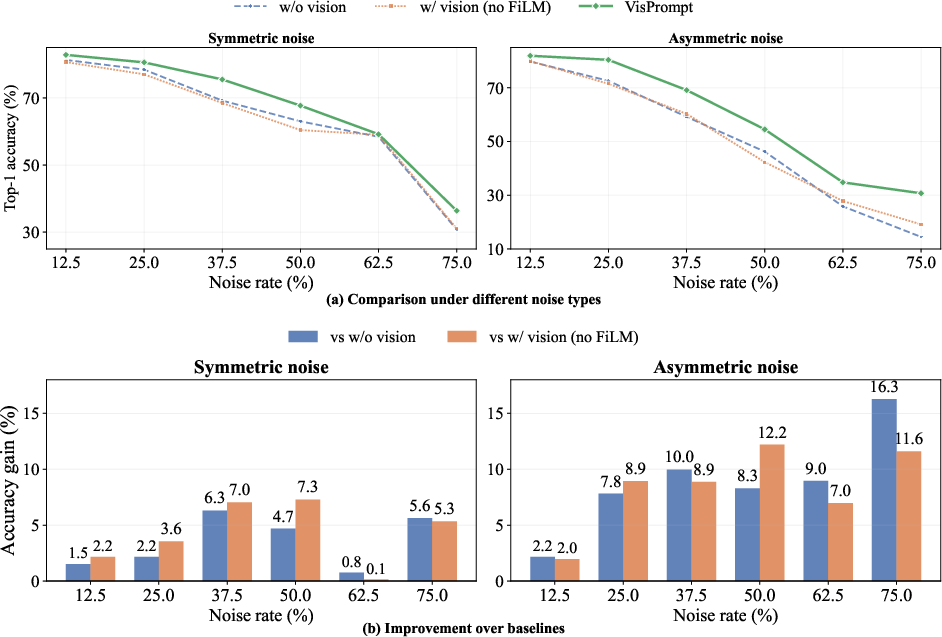
Figure 4: Ablation performance comparison, illustrating the importance of visual guidance and FiLM modulation for robustness.
Generalization to Backbone Variants and Data Regimes
Performance remains stable across both transformer- and CNN-based vision backbones (CLIP-ViT/ResNet variants), validating architecture-agnostic transferability. The sample efficiency of VisPrompt is also highlighted: accuracy steadily increases with additional shots, remaining robust at lower-data and high-noise regimes.
Practical and Theoretical Implications
VisPrompt substantively advances robust adaptation in noisy annotation environments by directly anchoring optimization to visual semantics, breaking reliance on wholly label-driven mechanisms. Architecturally, it generalizes to any frozen-encoder vision-language setup and imposes minimal computational overhead. Practically, the method's effectiveness on Food101N implies direct applicability to webly-supervised or weakly labeled data pipelines, a crucial setting for scalable deployment of foundation models.
Theoretically, the cross-modal FiLM-gated adaptation pipeline provides a rigorous avenue for distributionally robust optimization, limiting the amplification of noisy supervision in the restricted parameter regime of prompt learning.
Limitations and Future Directions
While VisPrompt demonstrates strong robustness in image classification and frozen VLMs, extension to dense prediction (detection, segmentation) remains untested. Broader real-world noise patterns (e.g., instance-dependent, open-set) warrant further evaluation, and efficiency-centric redesigns of the FiLM block may be necessary for large-scale or on-device deployment.
Conclusion
VisPrompt provides a parameter-efficient architecture for robust prompt learning under label noise, leveraging image-conditioned cross-modal interaction and adaptive FiLM-based gating to anchor prompt updates to reliable instance evidence. The method achieves state-of-the-art accuracy and stability across synthetic and real-world noisy benchmarks, validating vision-guided prompt optimization as a principled foundation for resilient multimodal learning (2604.09532).

