- The paper introduces a transformer-based VAE that encodes sparse tracker trajectories and a start frame into a dense latent motion grid for long-horizon kinematics prediction.
- It demonstrates that aggressive temporal compression (up to 64×) maintains semantic fidelity while significantly boosting inference speed and latent clustering.
- The approach employs a conditional flow matching model to generate diverse, goal-conditioned motion hypotheses for applications in control and robotics.
Learning Long-term Motion Embeddings for Efficient Kinematics Generation
Motivation and Context
Modeling and predicting the dynamics of real-world scenes is a fundamental requirement for visual intelligence, control, and embodied decision making. Traditional generative video models conflate appearance and motion, resulting in high-dimensional, entangled representations that are computationally prohibitive for long-horizon reasoning and difficult to control for goal-directed motion. Meanwhile, trajectory-based approaches that operate on sparse tracks or optical flow lack dense semantic structure or the capacity for generalization beyond observed samples.
The framework introduced in "Learning Long-term Motion Embeddings for Efficient Kinematics Generation" (2604.11737) addresses these limitations by learning a temporally compressed, spatially dense motion embedding that mediates efficient and controllable kinematics reasoning. This motion representation aggregates kinematic content from tracker-derived trajectories into a latent grid that supports both interpolation and semantic manipulation, serving as a compact substrate for goal-conditioned motion generation.
Architecture: Dense, Temporally Compressed Motion Embedding
The proposed two-stage approach begins by encoding sparse tracker-generated trajectories and a start frame into a continuous, learnable motion grid via a transformer-based variational autoencoder (VAE). This latent motion space is designed to support queries at arbitrary spatial positions, producing dense, temporally consistent motion predictions far beyond naïve replication of tracker inputs.
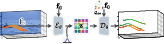
Figure 1: Sparse tracker trajectories and a start frame are encoded into a latent motion grid, which supports temporally consistent, spatially dense motion predictions at arbitrary spatial queries.
Temporal compression is a core property, with the authors demonstrating that severe compression (up to 64× reduction) does not significantly compromise semantic fidelity, but instead improves both efficiency and the structuring of the latent space. Empirical analysis shows that increased compression leads to faster inference and semantically more clustered latent representations, as evidenced by higher kNN accuracy for motion retrieval.
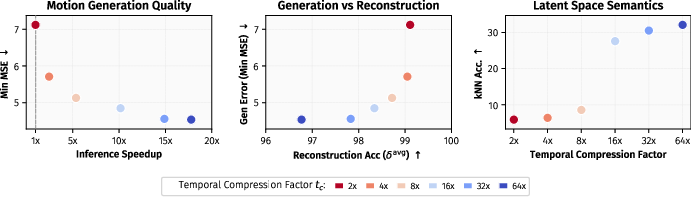
Figure 2: Strong temporal compression improves inference throughput and kinematic semantic structure with only minor loss in reconstruction fidelity.
Goal-conditioned Kinematics Generation via Flow Matching
The generative component of the framework consists of a conditional flow matching model trained to map random latents to the empirical motion latent distribution, conditioned on the scene context (start frame) and goal signals (spatial pokes or text prompts). This vector field, implemented as a transformer, learns to efficiently sample plausible trajectories in latent motion space that fulfill high-level objectives, enabling semantic and interpretable motion synthesis.
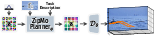
Figure 3: The flow matching model generates in learned motion space, conditioned via pokes or text to synthesize semantically coherent motions.
This abstraction enables highly expressive conditional generation—diverse, physically plausible motion hypotheses can be generated from a single static frame and a goal specification. Examples include spatial interpolation (moving an object along a user-posed endpoint), semantic planning (following a natural language instruction), or joint-action reasoning (predicting the coordinated motion of articulated subjects).
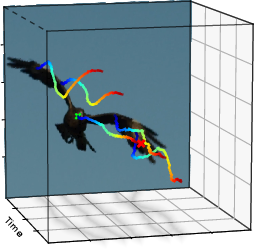
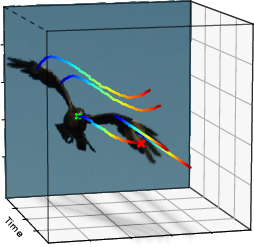
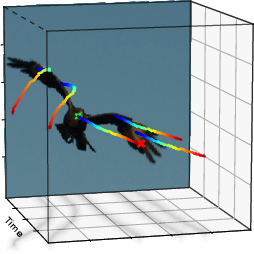
Figure 4: Multiple diverse and physically coherent flight hypotheses for an eagle, illustrating the expressiveness of the learned motion space.

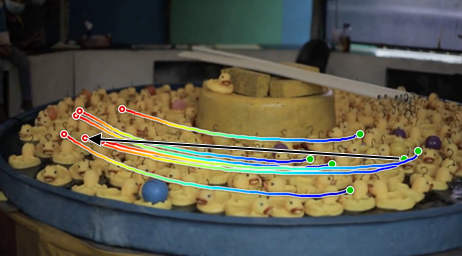

Figure 5: Path finding—demonstrations of the model’s semantic generalization over diverse kinematic regimes.
Quantitative Evaluation
The framework is evaluated on both open-domain (KOALA-36M, Pexels, DAVIS, PhysicsIQ) and structured robotics (LIBERO) datasets, benchmarking against both explicit trajectory-based and video-based modeling approaches. Motion quality is assessed using distributional metrics (Min/Mean MSE and Endpoint Error), where the predictive distribution over possible plausible future trajectories is crucial due to the inherent ambiguity in real-world scene dynamics.
The model consistently demonstrates superior motion quality with orders of magnitude greater inference speed compared to state-of-the-art flow-based and video diffusion models. For instance, with dense goal conditioning (poke-based motion specification), the model achieves a minimum endpoint error (EPE) of ∼0.5–1.1, substantially outperforming leading baselines (Motion-I2V at 8.8 and Track2Act at 20.9 EPE, see main text). In time-matched settings, owing to the heavy temporal compression and efficient latent modeling, the method can produce >10k trajectory samples in the time it takes leading video models to generate a single sample.
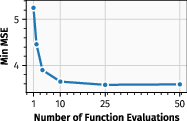
Figure 6: Performance (Min MSE) as a function of the number of function evaluations; strong performance is achieved with <100 steps.
For downstream tasks such as text-conditioned motion planning on robotics benchmarks, the latent motion embedding leads to higher policy success rates (77.5–80.3%) than ATM (60.4%) or Amplify (71.4%), under both spatial and semantic task decomposition protocols. These results empirically validate the claim that motion embedding–based reasoning supports more effective and efficient kinematic planning than traditional appearance- or track-based approaches.
Qualitative Analysis and Semantic Generalization
Visualization of motion hypotheses demonstrates that the model generates diverse, physically consistent, and interpretable kinematics under highly underconstrained conditions, such as ambiguous visual cues or sparse goal specifications. The embedding captures global kinematic context, supporting both interpolation and inpainting of dense plausible flows in scenes where only sparse tracker samples or goal endpoints are available.


Figure 7: Dense motion inference from sparse pokes; the model interpolates and inpaints globally coherent flows matching endpoint goals.





Figure 8: Additional qualitative samples—prompt and poke specification followed by randomly sampled plausible trajectories.
The architecture robustly generalizes across domains (open/in-the-wild motion, controlled manipulators) and can handle diverse classes of objects (articulated animals, vehicles, robots). The inductive bias of the temporally compressed latent space also mitigates mode collapse in generative reasoning and provides interpretable structure for downstream policy heads.
Implications and Prospective Impact
The introduction of a semantically structured, highly compressed latent motion space redefines the abstraction for kinematics modeling. By decoupling motion from appearance and focusing generative modeling directly on trajectory-level structure, this framework establishes a substrate that is suitable for large-scale world modeling, scalable integrated planning, and interpretable motion reasoning. High temporal compression makes long-horizon prediction and goal planning tractable for applications such as model-based reinforcement learning, multi-agent simulation, and robotics.
The results question the necessity of high-dimensional video-based modeling for many tasks related to planning and control, demonstrating that explicit motion embeddings offer superior sample-efficiency, controllability, and inference speed.
Potential future developments include:
- Extending latent motion embeddings to hierarchical or compositional kinematics over complex, multi-agent or multiscale scenes.
- Integrating with visual-language-action systems, where the motion embedding functions as an explicit policy substrate for embodied agents.
- Using this approach in real-world control and reinforcement learning pipelines for open-ended tasks requiring interactive planning and semantic transfer.
Conclusion
The paper presents a framework for learning temporally compressed, spatially dense motion embeddings that enable highly efficient, goal-conditioned kinematics generation and semantic motion reasoning. By combining scene-level global context integration with abstraction from raw video, it achieves strong improvements in motion quality, diversity, and efficiency over both pixel-based and previous trajectory-based models. The latent motion space provides a powerful, compact, and interpretable representation of dynamics, with broad relevance for both theoretical understanding and practical deployment of intelligent agents.

