- The paper presents a novel dual-branch VAE that couples discrete tokens with continuous latents via conditional flow matching to enhance text-to-motion synthesis.
- It demonstrates superior semantic alignment and high-fidelity motion generation, validated by state-of-the-art R-Precision and FID scores on HumanML3D and SnapMoGen benchmarks.
- The approach reduces sampling steps by 15× compared to diffusion models, making it highly efficient for applications in animation, robotics, and embodied AI.
FlowCoMotion: Text-to-Motion Generation via Token-Latent Flow Modeling
Introduction
FlowCoMotion advances text-to-motion generation by introducing a hybrid token-latent representation trained via a flow-matching generative process. Existing paradigms—autoregressive models with vector quantization and diffusion-based approaches—face compromises between semantic granularity, high-fidelity detail, and sampling efficiency. FlowCoMotion bridges these limitations by coupling discrete and continuous representations through a dual-branch VAE, fusing semantics and dynamics, and employing conditional flow matching for efficient inference. This framework achieves improved alignment with fine-grained text prompts, enhanced motion quality, and faster generation compared to standard diffusion models.

Figure 1: FlowCoMotion supports diverse conditioning and fine-grained motion generation, robust to input forms including numeric, geometric, and directional cues.
Methodology
Token-Latent Representation and Multi-View Distillation
The backbone of FlowCoMotion is a VAE featuring two parallel branches: a Token Branch leveraging residual vector quantization (RVQ-VAE) for discrete semantics, and a Latent Branch capturing continuous kinematic details. Discrete tokens anchor the motion sequence in semantic space via multi-resolution quantization, while the continuous latent encapsulates fine-grained trajectory dynamics.
A multi-view teacher-student distillation schema regularizes the latent space, maximizing generalizability and robustness under data augmentation. The outputs of both branches are fused via a coupling network, yielding a hybrid representation that is demonstrably more expressive for subsequent conditional generative modeling.
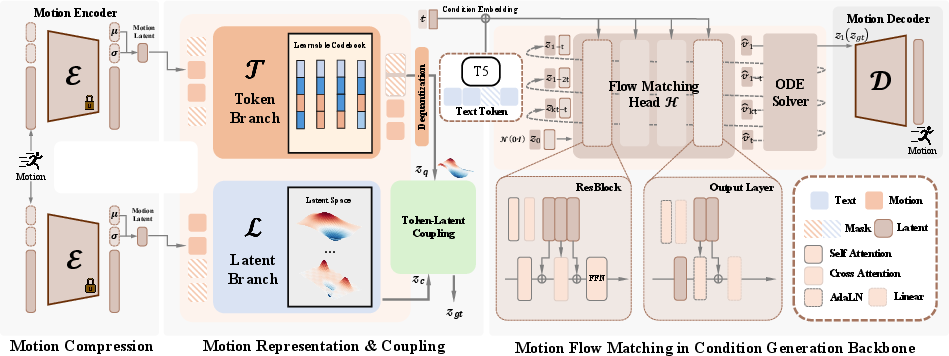
Figure 2: Schematic of the FlowCoMotion framework—the dual-branch VAE compresses and couples motion sequences using discrete and continuous representations, which are then used as targets for the conditional flow matching process.
Conditional Flow Matching Generation
FlowCoMotion employs a conditional flow matching head, parameterized by a Transformer, to operate in the coupled latent space. The generation process defines a straight-line latent trajectory between isotropic Gaussian noise and the real data manifold, with the instantaneous velocity field conditioned on text features extracted by a T5-base encoder. The resulting ODE is integrated to yield the target latent for decoding.
Notably, two Transformer block variants (Nova and Orbit) are evaluated for conditioning locality and stability. Both use learnable gates to modulate conditional influences, with Orbit introducing explicit separation and QK-normalization for finer control over temporal and textual conditions.
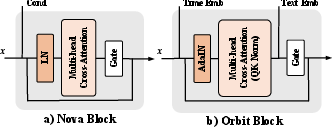
Figure 3: Overview of Nova and Orbit conditional Transformer blocks—Nova integrates unified conditions, while Orbit decouples and normalizes time/text conditioning.
The training pipeline is staged to ensure latent stability and kinematic fidelity: first, representation learning; second, decoder fine-tuning with kinematic losses; third, training of the conditional flow head.
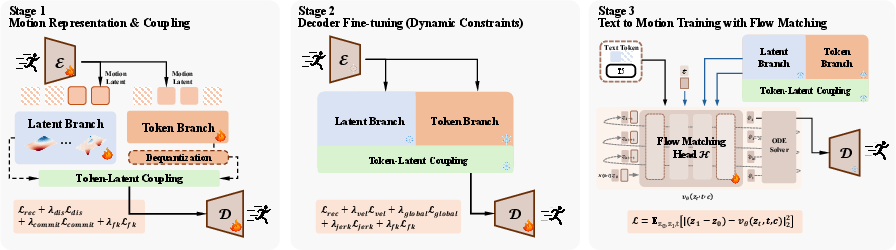
Figure 4: Three-stage training procedure—representation coupling, kinematic refinement, and flow-matching-driven conditional generation.
Experimental Results
Quantitative and Qualitative Evaluation
Experiments on HumanML3D and SnapMoGen benchmarks affirm that FlowCoMotion achieves state-of-the-art R-Precision (top-1/2/3: 0.55/0.74/0.83 on HumanML3D) and FID (0.061), outperforming or matching the best prior works in text-motion alignment and fidelity. On SnapMoGen, the Orbit variant yields top-1 R-Precision of 0.776 and FID of 14.678, again at the top tier.
Qualitative assessments highlight superior semantic adherence, especially for numerically or directionally nuanced prompts (“clockwise half circle”, etc). Motions generated by FlowCoMotion are more plausible, temporally consistent, and less susceptible to token degeneracy or quantization artifacts compared to baselines such as MotionGPT3 and MoMask++.
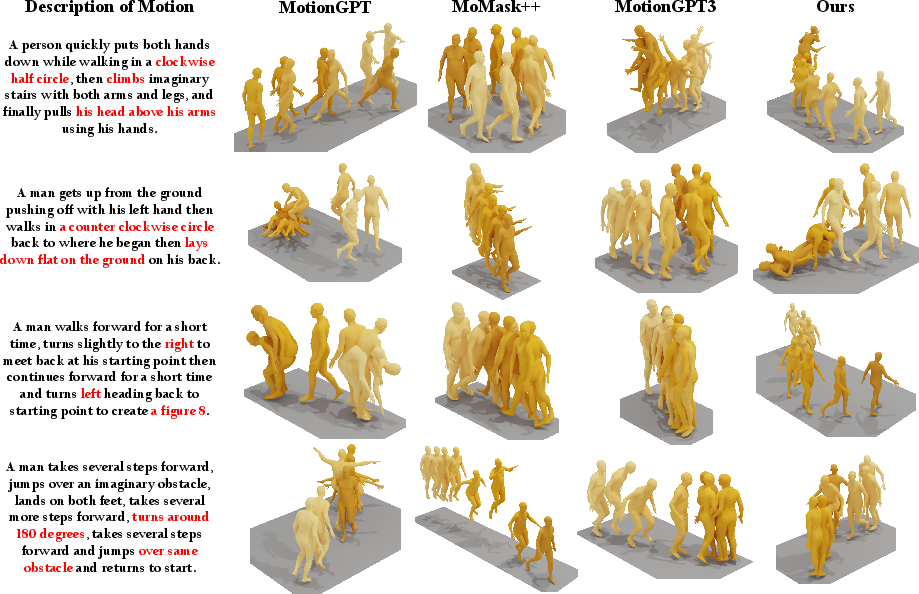
Figure 5: FlowCoMotion delivers higher text-motion alignment with more accurate and coherent generations versus MotionGPT, MoMask++, and MotionGPT3.
This advantage is robust for both short and long, compositionally complex prompts.
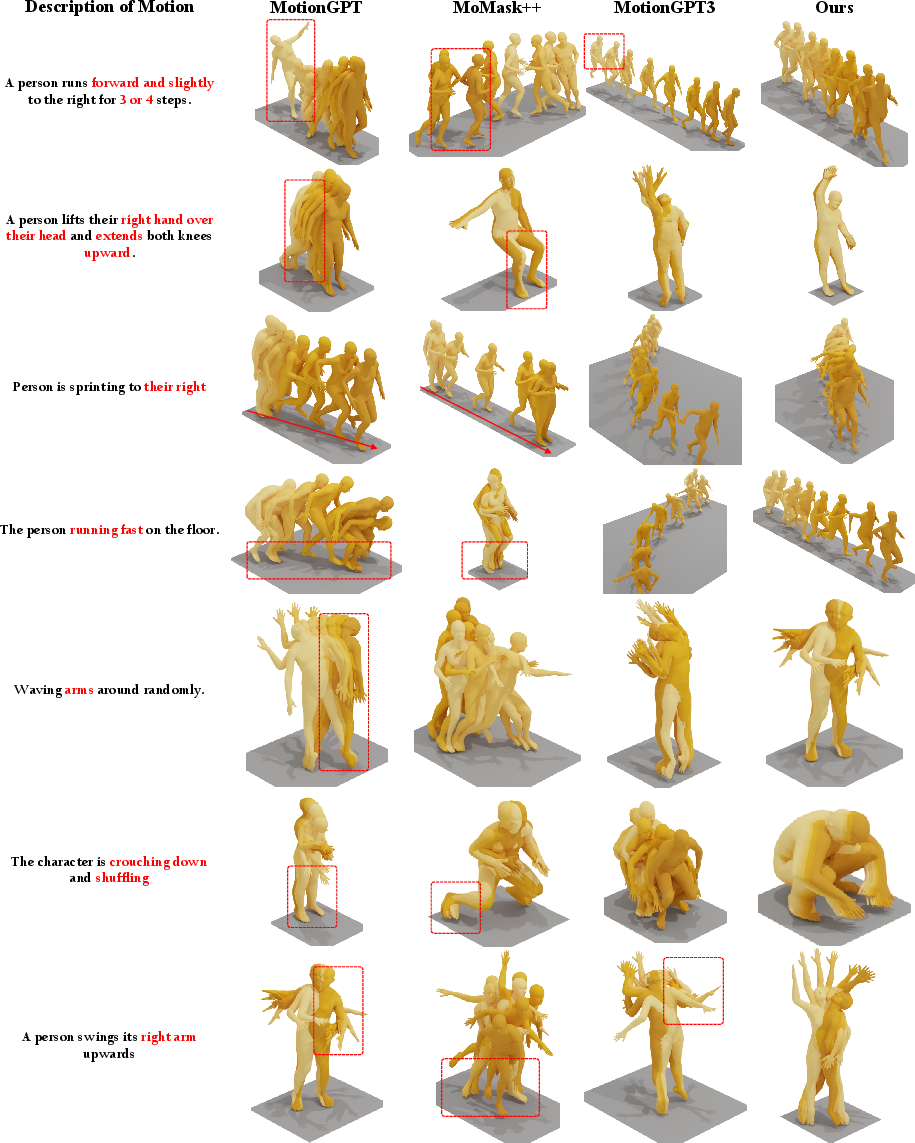
Figure 6: Short-prompt outputs show FlowCoMotion’s precise text understanding; mismatches in competing methods are highlighted.

Figure 7: FlowCoMotion outperforms competing models on long, multi-action prompts, generating coherent and precise motion sequences.
Fine-Grained Text Understanding
A rigorous analysis on a subset of HumanML3D filtered for high linguistic complexity demonstrates that FlowCoMotion's explicit coupling and flow conditioning yield superior R-Precision for fine-grained and compositional text instructions, confirming enhanced capability for highly constrained semantic mapping over previous methods.
Efficiency and Ablation
Inference efficiency is substantially improved via flow matching—a 15× reduction in sampling steps relative to diffusion-based models, with competitive or better quality metrics. Ablations confirm the superiority of the hybrid token-latent representation: models with only discrete or continuous representation suffer from higher reconstruction error and lower alignment scores. The tradeoff between token and latent dimensions was validated, with a non-symmetric allocation optimal for capacity utilization.
ODE solver and guidance scale analysis reveal robust FID and R-Precision performance at modest ODE step counts (L=40) and guidance scale (s=2).
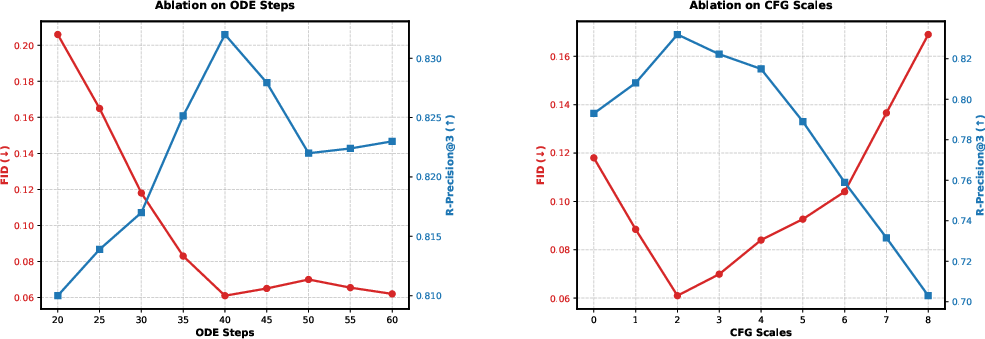
Figure 8: FID and R-Precision sweep over ODE steps and guidance scaling, showing convergence of performance with modest computational effort.
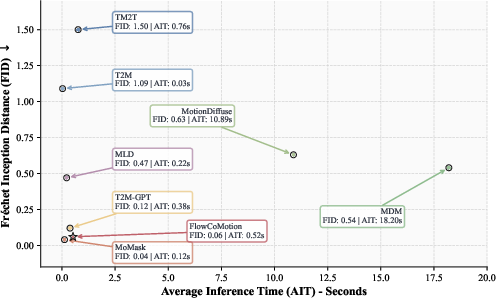
Figure 9: Inference time comparison—FlowCoMotion approximates autoregressive models in speed, outperforming non-autoregressive baselines such as diffusion.
Human Evaluation
User studies corroborate the objective metrics: FlowCoMotion is consistently ranked as the most preferred method for motion quality, diversity, and text-motion alignment in both individual and comparative settings.
Figure 10: Interface for user study evaluating qualitative aspects across models and prompts.
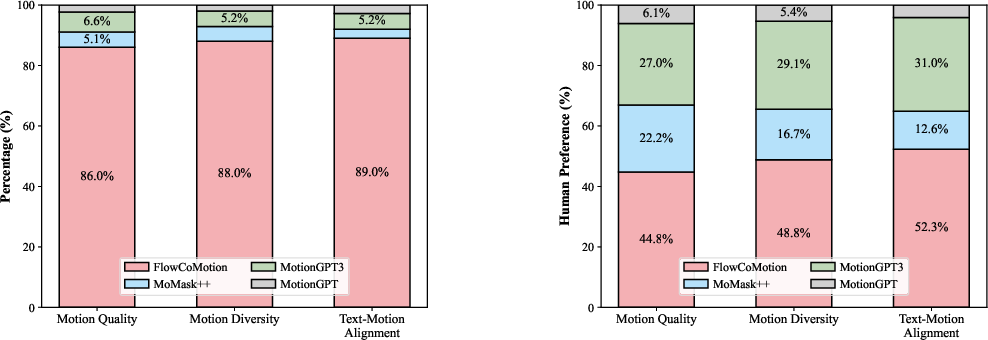
Figure 11: Human preference scores indicate clear superiority of FlowCoMotion in all qualitative aspects over baselines.
Theoretical Analysis
Theoretical results confirm that token-latent coupling monotonically reduces the minimum achievable reconstruction risk, as measured by the Bayes risk under squared loss, relative to pure token or latent branches. Moreover, coupling decreases the conditional ambiguity of the target latent, which reduces the irreducible error in the flow matching regression and directly eases learning of the velocity field. This is particularly consequential in text-to-motion, where text-to-motion mappings are inherently one-to-many and prone to semantic drift in single-branch representations, reinforcing the utility of the FlowCoMotion coupling paradigm.
Implications and Future Directions
Practically, FlowCoMotion’s improved semantic precision, inference acceleration, and flexibility in conditioning modes make it directly applicable to animation, robotics, and embodied AI requiring fast, high-fidelity, text-driven control. Theoretically, the hybrid representation with flow-matched generation underlines the value of reconciling discrete structure with continuous dynamics, suggesting a general pathway for hierarchical multimodal generation.
Future research should address single-stage training to reduce computational overhead, extend the framework to more complex compositions and multi-action sequences, and systematically assess zero-shot generalization to unseen motion categories. Exploring more sophisticated coupling networks, latent regularization paradigms, and hierarchical semantic control remains promising for scalable, compositional motion synthesis.
Conclusion
FlowCoMotion establishes a new paradigm for text-to-motion generation by coupling token and latent representations in a conditional flow-matched generative process. The approach yields improved semantic alignment, motion fidelity, and computational efficiency compared to state-of-the-art diffusion and autoregressive models. Both theoretical analysis and extensive empirical validation confirm the framework’s efficacy for fine-grained, text-conditioned human motion synthesis.