- The paper demonstrates that robust, task-specific LLM agent scaffolding achieves a 94% verified success rate across 35 diverse software analysis tasks.
- It systematically compares four agent architectures, showing that structured decomposition and evidence-based validation outperform unstructured LLM outputs.
- It highlights significant efficiency gains, with lower costs and reduced execution times, emphasizing the role of adaptive agent designs in complex environments.
Evaluating LLM Agents on Automated Software Analysis Tasks
Problem Context and Task Formulation
Automated software analysis—encompassing static/dynamic analyzers, symbolic execution, fuzzers, and profilers—plays a crucial role in contemporary software lifecycles. However, practical deployment of these tools at scale is hindered by burdensome environment setup, dependency mangling, and nontrivial configuration for both tools and diverse target codebases. The work introduces a rigorous benchmark, Analysis, comprising 35 tool–project pairs cutting across seven nontrivial C/C++ and Java analyzers and ten open-source projects, demanding that an agent autonomously provisions a reproducible container, installs and configures the chosen tool, builds and prepares the target project, runs the analysis, and produces definitive, verifiable evidence of meaningful tool output.
Agent Architectures and Evaluation Design
Four agent architectures are systematically evaluated:
- RAG-Agent: Synthesis-driven, retrieval-augmented via web resources, generates aggregate build and analysis scripts upfront.
- Mini-SWE-Agent: Iterative ReAct-style agent cycling reasoning and shell/file actions for incremental debugging.
- ExecutionAgent: Emphasizes robust environment construction and deferred, in-container execution.
- Analysis (proposed): Task-specific, integrating explicit staged decomposition (Docker setup, tool, project, analysis), single-action cycles with deterministic log condensation, and evidence-based, LLM-as-judge-validated success checks.
All agents are tested with identical per-task budgets (max 120 cycles, $5$ minutes, \$2 API expense), and four commercial/proprietary LLM backends of varying context and price points (GPT-5-nano/mini, DeepSeek-V3.2, Gemini-3-Flash) over the full 35-task benchmark.
Quantitative Findings
Analysis agent, with Gemini-3-Flash or DeepSeek-V3.2, achieves a manually verified success rate of 94% (33/35), outperforming the best baseline (ExecutionAgent+Gemini-3-Flash, 77%) by a substantial margin.
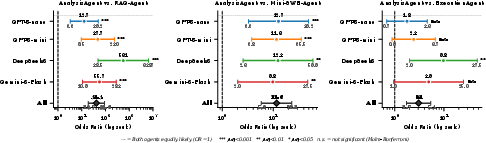
Figure 2: Analysis is consistently more likely to succeed than all baselines, with odds ratios substantially exceeding 1 across all evaluated LLMs and in aggregate.
Effect size analysis underscores this advantage: odds ratios of 34.5, 8.1, and 2.7 over RAG-Agent, Mini-SWE-Agent, and ExecutionAgent respectively (all padj<0.001, Holm-Bonferroni), with results robust across LLM choice. Notably, model choice alone does not suffice for high end-to-end reliability—agentic scaffolding exerts greater influence on verified outcomes than raw LLM capability.
Crucially, self-validated success rates are systematically inflated across all baselines. For instance, Mini-SWE-Agent and RAG-Agent often report >90% automated success, but manual inspection rates are as low as 9–37%. The Analysis agent's validator reduces—but does not eliminate—this gap, underscoring the necessity of extrinsic, reference-based validation for robust assessment in complex software analysis workflows.
Success and failure rates vary strongly as a function of the analysis tool and target ecosystem. Java tasks and whole-program/symbolic analyzers register higher failure and resource consumption rates, with WALA and Infer dominating the residual failure fraction.
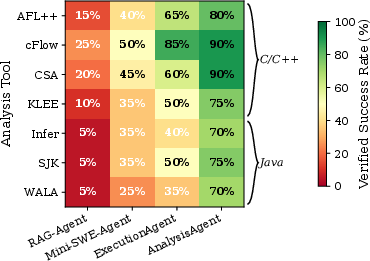
Figure 1: Success rates by tool and agent—Analysis closely approaches 100% for most static analyzers; hardest targets are whole-program Java analyses.
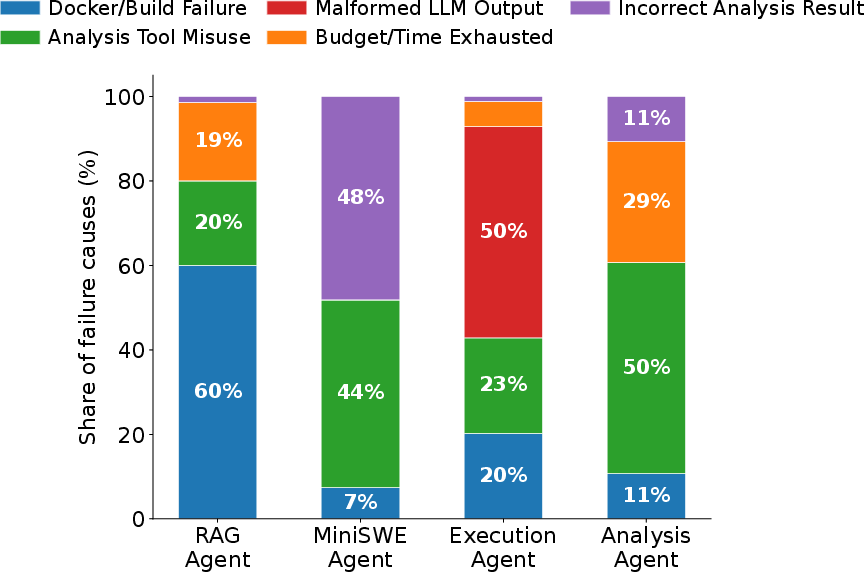
Root-cause analysis of failed trajectories reveals distinct clusters:
Efficiency and Resource Dynamics
Resource consumption analysis indicates that efficiency is non-monotonic in model price: weaker models (e.g., GPT-5-nano) perform more cycles and take longer due to missteps, up to 4× more than higher capability models, effectively negating lower per-token costs. Failed runs are 2.77× more expensive and 4.07× longer than successful ones, further amplifying the case for robust agentic scaffolding.
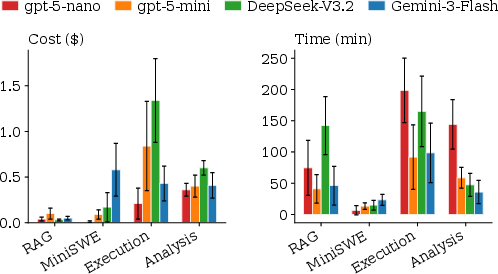
Figure 4: Resource consumption as a function of agent and LLM backend—Analysis yields lower mean cost and wall-clock time due to higher success rates.
Qualitative Insights and Output Depth
Despite constrained dynamic analysis budgets (30–180s per dynamic tool run), successful agent runs produce diverse, correct outputs ranging from nontrivial coverage and test cases (AFL++, KLEE) to full call graphs (WALA) and structured static bug reports (CSA, Infer). However, for dynamic tools, coverage remains shallow due to runtime limits—improvements in tool invocation robustness could enable scaling to deeper analysis in automated workflows.
Implications and Future Directions
Practical Implications: Analysis demonstrates that, with robust agentic scaffolding, LLM-powered automation can reliably orchestrate complex tool-plus-project tasks, rendering integration into CI/CD viable at cost <$1/task$ (for top-performing models). However, evidence validation remains essential, as LLMs tend to overreport superficial success in the absence of structured checks.
Theoretical and Methodological Implications: The findings reinforce that general-purpose LLM architectures, even at scale, underperform without task-specific structure, particularly when agentic planning, staged execution, and domain-tailored validation are essential. This supports a research direction favoring compositional, modular agent designs over pure prompt scaling for environment-intensive tasks.
Avenues for Future Work:
- Expansion of the Analysis benchmark to include additional languages, non-command-line/library targets, and commercial/closed-source analysis tools to further stress-test agent generality and portability.
- Development of adaptive agent strategies capable of early detection of failure modes (e.g., compile-fix loops, validation failures) and dynamic budget reallocation.
- Controlled studies benchmarking agent-assisted versus manual setup to empirically quantify developer productivity impact.
- Integration of self-reflective pipelines and lifelong learning to mitigate repeated errors in long-horizon action sequences.
Conclusion
The work establishes a clear methodology for evaluating, comparing, and improving LLM-agent architectures in the context of automated software analysis. It demonstrates that purpose-built, scaffolded agents with robust, evidence-based validation can solve multi-stage, environment-intensive tasks at near-human reliability, whereas unstructured prompting or model scaling alone is insufficient. This provides a blueprint for practical deployment of autonomous agents in software engineering and suggests fertile ground for further research on agent design principles in complex automation domains (2604.11270).