- The paper introduces AndroidBuildBench and GradleFixer, achieving an 81.4% pass@1 rate in automated Android build repair tasks.
- The study demonstrates that domain-specific tool abstractions effectively bridge the reasoning-execution gap, reducing inefficient trial-and-error cycles.
- The failure analysis reveals that repair success correlates with problem complexity, emphasizing the benefits of incremental build repair strategies.
Automating Android Build Repair: Bridging the Reasoning-Execution Gap in LLM Agents with Domain-Specific Tools
Benchmark Construction: AndroidBuildBench
The paper introduces AndroidBuildBench, a curated benchmark designed to evaluate automated build repair for Android projects. The dataset is formed from 1,019 reproducible build failures sourced from 43 open-source, actively maintained Android repositories, each annotated with a ground-truth fix from a subsequent commit. The benchmark encompasses failures arising from human error, dependency misconfiguration, and LLM-generated code, ensuring broad coverage of practical build issues. A detailed analysis reveals a dominant presence of syntax errors (59.8%), followed by configuration errors, resource file omissions, and missing libraries. Complexity is represented by a spectrum of code modifications, ranging from single-line tweaks to extensive changes involving thousands of lines, as demonstrated by the long-tailed distribution of problem difficulty.
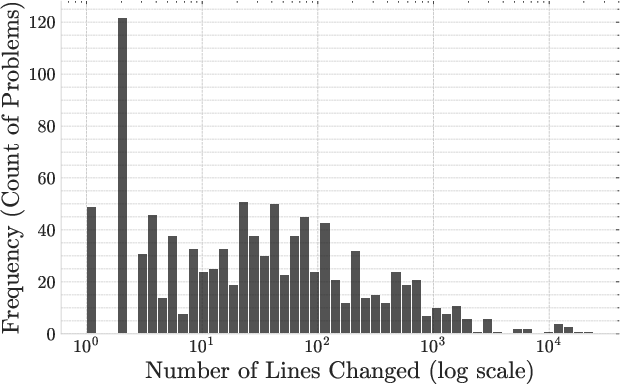
Figure 1: Distribution of problems by the number of lines changed showcases the benchmark’s ability to evaluate both small-scale and large-scale build repair tasks.
GradleFixer: Domain-Specific Tooling for LLM Agents
The central agent introduced is GradleFixer, which employs a suite of domain-specific tools tailored to the Gradle build ecosystem instead of relying solely on a general-purpose shell. Each tool provides a high-level API-like abstraction for build inspection and manipulation, reframing low-level shell commands (such as build invocation or environment configuration) into reliably usable agent actions. This approach, designated as Tool Bridging, directly addresses the reasoning-execution gap that emerges when LLMs are tasked with translating conceptual knowledge into the correct sequence of system-level operations. Empirical results show that domain-specific toolsets both reduce action-space and increase reliability of execution, with agents less likely to get trapped in inefficient trial-and-error cycles.
The experimental framework evaluates five agent configurations: Coding-Assistant, Hierarchical Agent, Gemini-CLI (Read/Write Only), Gemini-CLI (Shell), and GradleFixer. The core LLM used is Gemini-2.5-Pro. GradleFixer achieves a pass@1 resolve rate of 81.4% across diverse build errors, substantially outperforming Gemini-CLI baseline (Shell) at 65.1%. The largest discrepancies were observed for dependency-induced failures, where GradleFixer's domain tool abstractions allow the agent to manipulate and validate build environment far more efficiently.
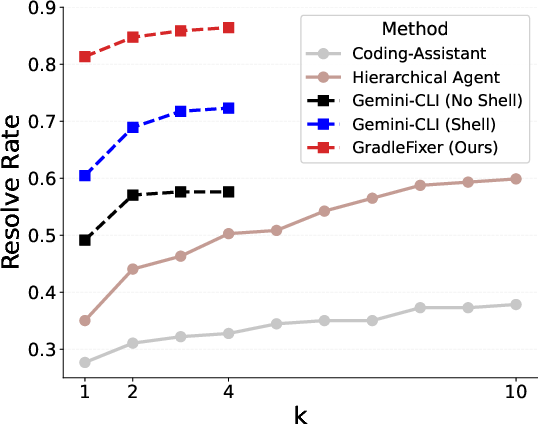
Figure 2: The inclusion of domain-specific tools yields significantly higher pass@k rates compared to agents limited to general-purpose shell commands.
An ablation study on tool specificity further establishes a monotonic increase in repair rates as tools become more abstract and focused. Notably, GradleFixer with a smaller Gemini-2.5-Flash model surpasses the Gemini-CLI (Shell) agent using the larger Pro model, highlighting that operational abstraction often trumps raw model capacity for this domain.
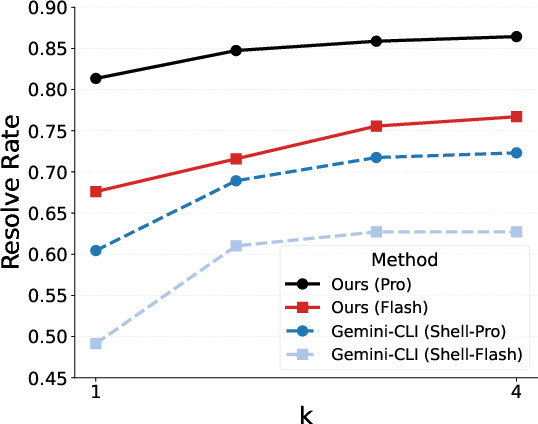
Figure 3: Smaller LLMs equipped with domain-specific tools outperform larger models without such tools, emphasizing the critical impact of tool abstraction.
Failure Analysis and Repair Difficulty
A detailed failure analysis shows that unsuccessful repair attempts correlate strongly with problem complexity, as measured by the number of lines and files modified in the faulty commit. Both successful and failed trajectories are documented in case studies, sharpening the insight that large, multi-file modifications pose compounding diagnostic challenges. The relative insensitivity to error type, juxtaposed with sensitivity to change magnitude, suggests that incremental build and repair may maximize agent efficacy and reduce operational cost.
The empirical success of Tool Bridging (domain abstraction and action-space constraint) supports the hypothesis that LLMs possess substantial latent domain knowledge but struggle with grounding that knowledge in effective command synthesis. Providing API-like, contextually named, and domain-relevant tools enables agents to activate specialized behavioral circuits, efficiently mapping high-level reasoning to correct low-level execution. This design pattern aligns with findings in studies of embodied agentic learning and code researcher frameworks but is isolated as the primary cause of performance gain in this work.
Practical Impact and Cost-Efficiency
By demonstrating that domain-specific tools dramatically outperform both prompt-based tool guidance and general shell interaction, the paper highlights a robust avenue for reducing both token cost and computational expense. Successful repair consumes fewer LLM calls, and effective abstraction enables smaller models to rival (or exceed) larger, more expensive counterparts. This opens opportunities for cascading agent design or fine-tuned, task-specific LLMs, with broad implications for enterprise-scale CI/CD, automated software maintenance, and democratized developer tooling.
Conclusion
The research establishes AndroidBuildBench as a comprehensive benchmark for build repair and demonstrates that agents equipped with domain-specific tools outperform state-of-the-art baselines both in efficiency and cost-effectiveness. Tool Bridging is empirically validated as the critical strategy for bridging the LLM reasoning-execution gap, with results generalizable to other agentic AI domains requiring robust operational abstraction. Future developments could include automatic tool generation and adaptation by LLM agents, as well as fine-tuning smaller models for specialized repair tasks, potentially reshaping agentic workflows in software engineering and beyond.