- The paper presents a novel structured state-space regularization that leverages frequency-aware basis projections to enhance both reconstruction and generation in image tokenizers.
- The method integrates a hybrid training regime with progressive Gaussian blurring, achieving improved generative metrics (gFID 13.33, sFID 7.29, IS 106.61) with minimal loss in quality.
- The approach yields interpretable, frequency-specialized latent channels that support efficient image synthesis and suggest extensions to video and multi-modal models.
Structured State-Space Regularization for Image Tokenization
Introduction and Motivation
State-of-the-art computer vision models increasingly rely on learned image tokenizers to compress visual input into compact, information-rich, and generative-friendly latent representations. The construction of such latent spaces is critical for both efficient computation and improved image synthesis, with particular relevance to diffusion models and world models operating in the latent rather than pixel domain. However, the joint objectives of compactness and generation-friendliness can be antagonistic, and current autoencoding methods often trade off reconstructive fidelity against downstream generative modeling quality. The paper "Structured State-Space Regularization for Compact and Generation-Friendly Image Tokenization" (2604.11089) addresses this challenge by introducing a new regularizer inspired by the frequency-aware structure of state-space models (SSMs), explicitly designed to enhance both compactness and generative suitability of image tokenizers.
Theoretical Foundation: State-Space Model Inductive Bias
The primary insight underlying the proposed method is that SSMs, particularly those parameterized by orthogonal polynomial or Fourier bases (such as HiPPO, LSSL, and Mamba layers), intrinsically provide frequency domain decompositions of the input signal. By projecting an input sequence onto such bases and examining the evolution of basis coefficients under structured transformations (e.g., progressive Gaussian blurring), SSM hidden states enable fine-grained separation and prioritization of frequency content.
The authors recast SSMs in a generalized framework consisting of two key operations:
- Basis projection: Compression of the input signal into basis coefficients (e.g., via 2D Fourier or orthogonal polynomial expansions).
- Input transformation: Sequential or continuous transformations applied to the input (e.g., concatenation in time, progressive 2D Gaussian blur in space).
This yields a recursive coefficient dynamics that can be mathematically derived for various bases and transformations. Crucially, the frequency separation property—where basis coefficients with lower indices encode global structure and higher indices encode finer details—matches desirable tokenization properties.
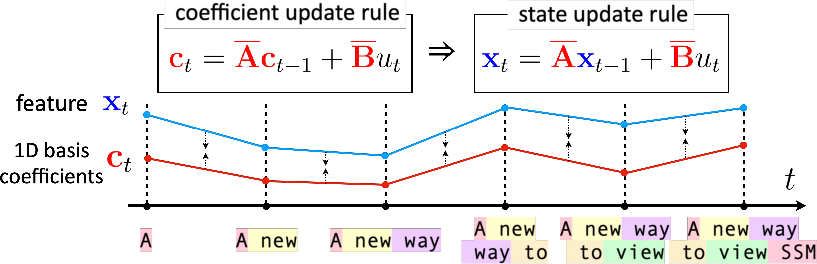

Figure 1: Different choices of basis projection c(⋅) and transformation θ(⋅) give rise to distinct SSM update dynamics, enabling modeling of both sequential signals and spatial blurring.
Structured State-Space Regularization: Methodology
Building on the above theory, the authors propose structured state-space regularization: Instead of using arbitrary encoder features, they regularize the latent codes produced by the image tokenizer to mimic the dynamics of SSM basis coefficients under a progressive image transformation (specifically, Gaussian blurring). For an image It at blur level t, its feature encoding zt=E(It) is regularized so that
zt+1≈Azt,
where A is the discretized SSM dynamics matrix corresponding to the chosen basis (e.g., diagonal in the case of 2D Fourier). The regularizer encourages the encoder to learn feature channels that act analogously to basis coefficients—each with interpretable, frequency-oriented meaning and predictable transformation behavior.
The implementation uses a hybrid training regime: with probability α, the SSM-based regularizer is applied; otherwise, a standard reconstruction loss is used. The loss is computed not only on the latent space (MSE) but also in the pixel space after decoding, mitigating degenerate solutions.

Figure 2: State-space regularization applied to an image tokenizer, leveraging the SSM update (Eq.~(\ref{eq:whippo_update2})) with probability α.
Empirical Evaluation and Quantitative Results
The structured SSM regularization is integrated with prevailing tokenizers, e.g., Flux (8× downsampling) and Cosmos (16×), and downstream latent diffusion models (DiT-B/2) are trained on these latents for ImageNet-1K synthesis. The results reveal several salient points:
Analysis of Latent Structure and Frequency Separation
Further inspection of the latent spaces reveals that the regularization induces interpretable organization:
- Latent channel dynamics: Channels evolve predictably across a blurring sequence, matching the exponential decay/growth of corresponding basis coefficients in the SSM, leading to smoother and more structured latent trajectories.
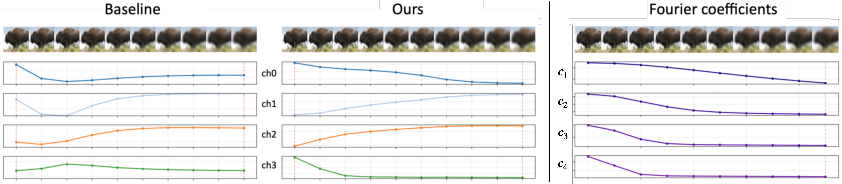
Figure 4: Latent channel activations across blurring steps closely mimicking SSM coefficient dynamics; channels remain ordered and frequency-specific.
- Channel frequency specialization: Masking experiments confirm that latent channels predominantly encode specific frequency bands; progressively unmasking low-to-high-index channels reconstructs images coarse-to-fine, echoing DCT/JPEG-like representations in an end-to-end learned form.

Figure 5: Latent channels decode low-to-high frequency content; just a few low-frequency channels suffice for coarse image reconstruction, reflecting frequency-aware allocation of capacity.
- Mean-centering adjustment: The use of spatial mean-centering in the latent regularization avoids trivial shrinking of norms for blurred images and stabilizes the learning process, preserving KL regularization and latent expressivity.

Figure 6: Visualization of latent norms, illustrating regularization with mean-centering versus naïve application.
Ablation studies determine that the frequency structure (and efficiency) of the SSM matrix A is crucial. Random (unstructured) matrices preclude convergence, while Fourier, Chebyshev, Legendre, and Hermite all improve metrics, with Fourier giving maximal gains. Regularization strength θ(⋅)0 also must be tuned to balance reconstruction and generative performance; excess regularization hurts both.
Visualization of the learned θ(⋅)1 matrices confirms their sparsity and frequency-aligned structure, supporting efficient and interpretable feature dynamics.
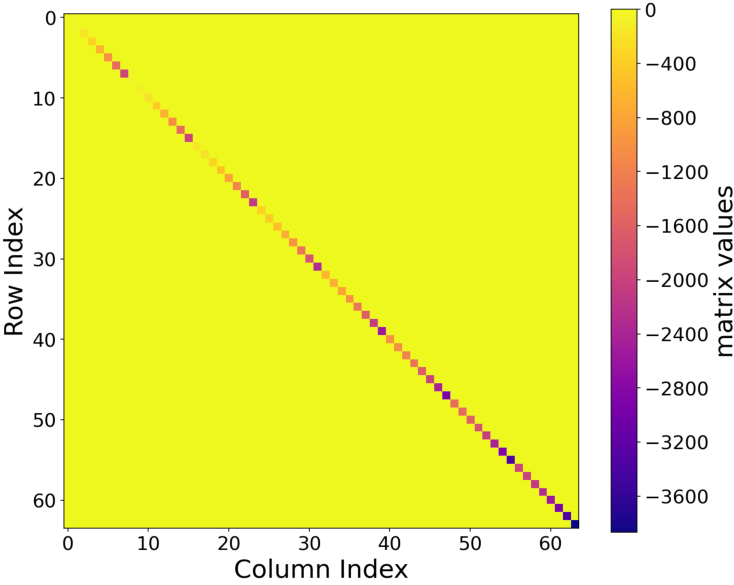
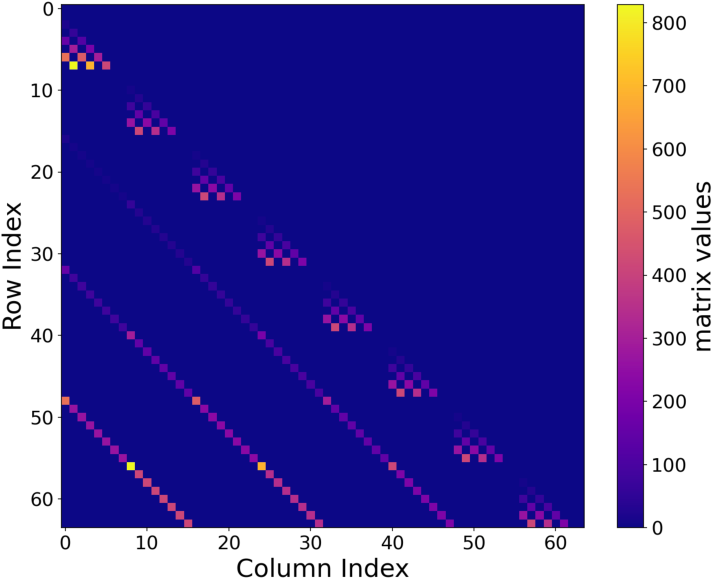
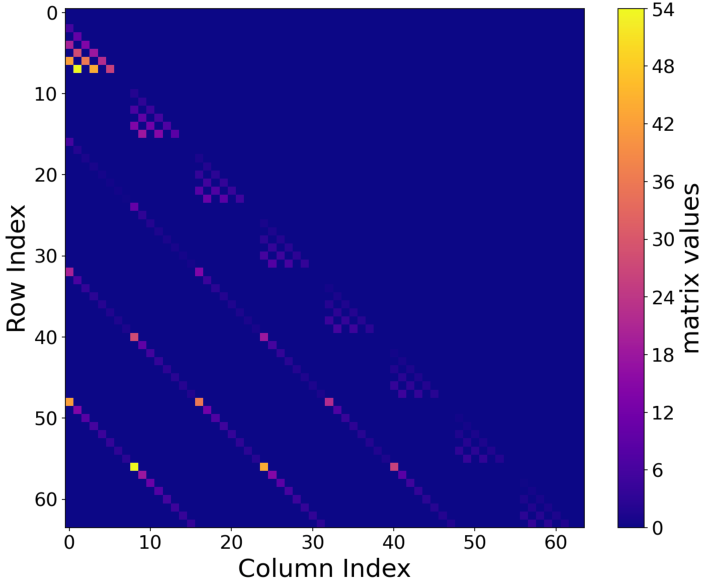
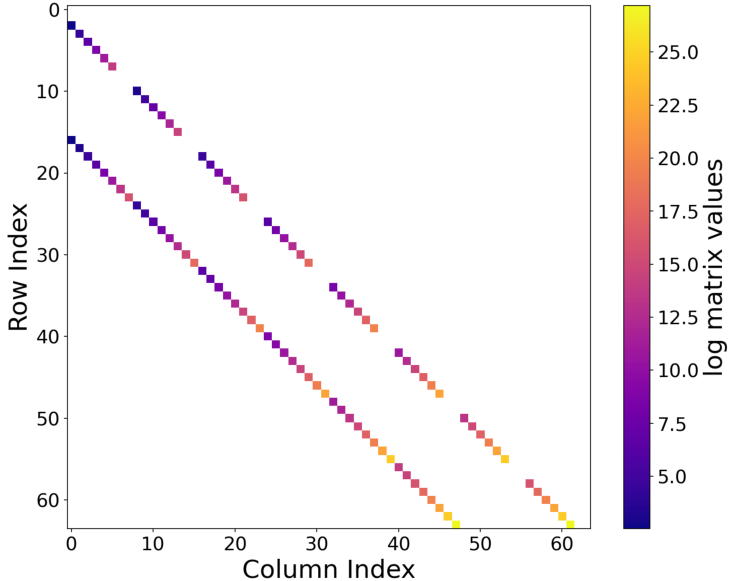
Figure 7: Visualization of the Fourier θ(⋅)2 matrix, which is highly sparse and diagonal, reflecting pure frequency selectivity.
Implications and Future Directions
The main implication is that SSM-inspired frequency-structured inductive bias can yield tokenizers whose representations are both reconstructive and exceptionally well-suited for latent generative modeling. This bridges classical signal-processing insights (e.g., bandwidth separation, spectral compression) with contemporary learned representation techniques in deep neural frameworks. Practically, the approach enhances the efficiency of generative pipelines, suggesting improved scaling for high-resolution and video models.
Theoretically, the paper frames a general class of inductive priors—basis projection plus input transformation—beyond standard SSMs, offering a toolkit for flexible inductive bias construction across domains and architectures.
Future developments may extend these methods to video tokenization, continuous-time state-spaces, or multi-modal generative models; they also open the door for further cross-pollination between control-theoretic, spectral, and deep learning perspectives on representation structure.
Conclusion
Structured state-space regularization offers a rigorous, theoretically motivated approach to image tokenizer design, harmonizing compactness, generative friendliness, and interpretability. By directly encoding frequency decomposition and evolution into the latent space, the method achieves state-of-the-art generative metrics with negligible reconstructive penalty. The framework’s flexibility and empirical efficacy recommend its adoption as a standard regularizer in both academic and industrial generative pipelines, with substantial implications for the future of representation learning and model efficiency across visual domains.


