- The paper introduces staged token compression and joint self-supervised training to address token-to-latent collapse in deep compression autoencoders.
- The paper demonstrates that naive token scaling improves reconstruction metrics but fails to yield generative quality due to semantic collapse, as shown in extensive ImageNet experiments.
- The experimental results reveal that TC-AE achieves superior generative performance with up to 4.7× fewer training steps and significantly reduced GFLOPs compared to prior methods.
TC-AE: Unlocking Token Capacity for Deep Compression Autoencoders
Motivation and Contributions
TC-AE introduces an innovative formulation of deep compression autoencoders specifically targeting ViT-based tokenizers for efficient latent diffusion models. The paper identifies a fundamental issue: aggressive spatial compression compensated by latent channel expansion inevitably leads to latent representation collapse, severely degrading generative performance despite maintaining high reconstruction fidelity. The central thesis posits that improving performance under deep compression requires a structural rethinking of the token space—both its capacity and semantic organization—rather than merely increasing parameter count or expanding latents.
Key contributions are twofold. First, the authors rigorously analyze token number scaling in ViT architectures, revealing that naive increases in token counts improve reconstruction but fail to enhance generative performance due to excessive token-to-latent compression at the bottleneck. Second, TC-AE introduces staged token compression within the encoder, distributing compression over two stages, which substantially alleviates semantic structure loss. Complementarily, the incorporation of joint self-supervised objectives (specifically iBOT) structures the token space, directly addressing generatability.
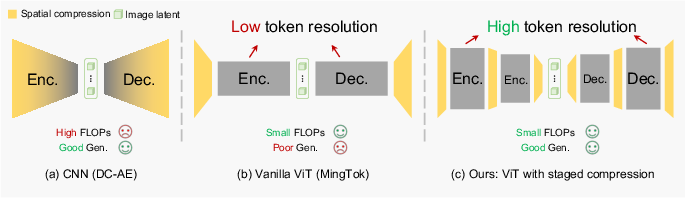
Figure 1: Comparative schematic of CNN, vanilla ViT, and TC-AE architectures for token compression and efficiency.
Failure Modes of Naive Token Scaling
A principal experimental finding is that increasing token numbers (via reduced ViT patch size) yields monotonically improved reconstruction metrics but does not translate into higher generative quality in diffusion models. Extensive ablations show a sharp collapse of latent semantic structure as the patch size decreases, with linear probing accuracy dropping precipitously post-bottleneck, indicating aggressive semantic loss.
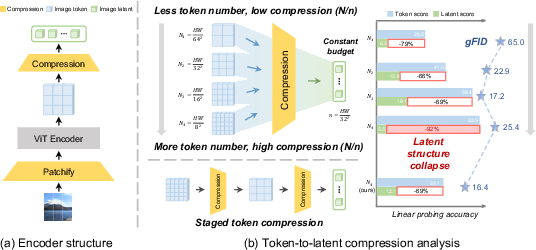
Figure 2: Visualization of latent structure collapse during token-to-latent compression at small patch sizes.

Figure 3: Empirical results of reconstruction and generation as token numbers increase; reconstruction improves, but generation stagnates.
This empirical contradiction pinpoints the token-to-latent bottleneck as the limiting factor for token scaling. Under fixed latent budgets, the compression ratio at the bottleneck grows with more tokens, destroying the semantic structure necessary for diffusion convergence and high-quality synthesis.
Method: Staged Token Compression and Self-Supervision
TC-AE decomposes the token-to-latent compression into an intermediate compression stage inside the encoder followed by a final bottleneck. The first stage operates on a large token space, enabling semantic structure learning; the intermediate compression aggregates local structure into fewer tokens; the second stage preserves this structure in the latent. This staged approach maintains semantic integrity even as token counts scale.

Figure 4: Demonstration that generative performance scales with token number when using staged token compression.
Complementing staged compression, the authors employ a joint self-supervised objective (iBOT), leveraging masked image modeling and cross-view semantic distillation. This encourages the ViT encoder not only to reconstruct, but to organize the token space semantically, directly improving generatability.
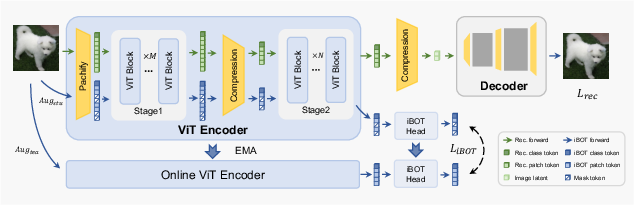
Figure 5: TC-AE architecture showcasing staged token compression and self-supervised auxiliary training.
The combined objective is a weighted sum of reconstruction (pixel, perceptual, adversarial) losses and self-supervision, enabling simultaneous structure preservation and generative quality.
Experimental Validation
The paper extensively evaluates TC-AE on ImageNet, demonstrating both quantitatively and qualitatively its superiority versus prior deep compression and low-compression tokenizers. Notably, TC-AE outperforms DC-AE and DC-AE-1.5 in generative metrics (gFID, IS) with dramatically reduced GFLOPs (164 vs. 607)—achieving strong compression-efficiency tradeoff. Furthermore, staged compression and self-supervision independently and jointly accelerate diffusion convergence: TC-AE attains the same gFID with up to 4.7× fewer training steps.
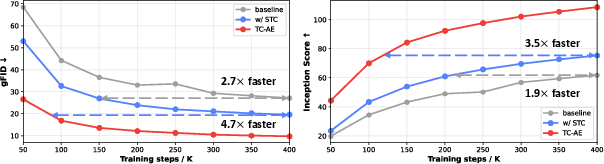
Figure 6: Diffusion convergence curves illustrating accelerated optimization with staged compression and self-supervised token structuring.
Qualitative samples confirm enhanced visual fidelity and semantic consistency compared to baselines.

Figure 7: Side-by-side qualitative comparison demonstrating visual improvements delivered by TC-AE.

Figure 8: Representative samples generated by TC-AE-enabled diffusion models at 256×256 resolution.
System-level comparisons further show TC-AE bridges the performance gap between deep compression and traditional tokenizers, matching or exceeding methods operating with larger latent spaces and substantially more compute.
Additional ablations confirm that token number scaling and parameter scaling are synergistic but token scaling yields stronger generative gains per FLOPs. The optimal split between encoder stages (M=6) balances semantic learning vs. compression capacity. iBOT outperforms other SSL methods in moderate-batch regimes, and two-layer convolutional token compression modules yield better generative performance than pixel shuffle+MLP alternatives.
Implications and Future Directions
TC-AE fundamentally shifts the perspective on designing autoencoders for generative models, reframing token space optimization as a primary dimension of scalability and efficiency. Practically, TC-AE enables highly compressed, generative-friendly latents suitable for deployment in resource-constrained scenarios (e.g., edge inference, large-scale image pipelines) without the quality degradation previously inherent to deep compression.
Theoretically, staged compression and semantic structuring advocate for architectural composability and joint objective optimization. Future research could explore more sophisticated intermediate compression schemes (potentially hierarchical or dynamic), scaling laws for token structuring, alternate self-supervised objectives, and the integration of multimodal semantic alignment.
TC-AE’s paradigm may inform design of efficient tokenizers for multimodal models, cross-domain generative tasks, and even non-visual domains where token capacity and structure are bottlenecks.
Conclusion
TC-AE rigorously identifies and addresses the latent collapse phenomenon in deep compression autoencoders via token-space-centric innovations: staged token compression and semantic self-supervision. Extensive empirical results demonstrate marked improvements in generative performance, efficiency, and convergence rate compared to state-of-the-art alternatives. This work establishes token space optimization as a critical and complementary axis for generative autoencoder scalability, opening avenues for future exploration in both architectural and objective design.

