- The paper introduces T-STAR, which consolidates agent trajectories into a cognitive tree to assign precise, step-level credit for policy optimization.
- It employs thought grafting and surgical policy optimization at divergence points to correct reasoning errors, achieving performance gains of 3–8.5%.
- Empirical results on ALFWorld, WebShop, and multi-hop QA demonstrate faster convergence and enhanced stability in environments with sparse rewards.
Tree-structured Self-Taught Agent Rectification for Multi-turn Policy Optimization
Motivation: Navigating Credit Assignment in Multi-step LLM Agent RL
Sparse rewards and long-horizon reasoning chains present significant obstacles for reinforcement learning of LLM-based agents operating in environments demanding sequential decision-making. Existing methods such as GRPO and its variants predominantly treat sampled trajectories as isolated chains, resulting in uniform credit assignment across all steps within each trajectory and inconsistent crediting of identical reasoning prefixes shared across trajectories. This structure obscures critical divergence points, thereby impeding precise policy optimization.
In WebShop operations, for example, multiple agent trajectories may share early reasoning steps but diverge at attribute verification, leading to success or failure. Conventional trajectory-level rewards fail to identify and appropriately leverage these crucial steps for policy improvement.
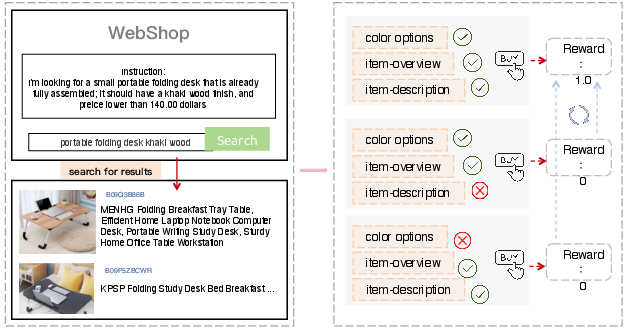
Figure 1: Three WebShop trajectories with identical prefixes diverge at critical steps, resulting in inconsistent prefix credit assignment and missed policy optimization opportunities.
T-STAR Framework: Cognitive Tree Consolidation and Introspective Valuation
T-STAR (Tree-structured Self-Taught Agent Rectification) introduces a paradigm shift in policy optimization by consolidating all sampled trajectories into a single Cognitive Tree via functional and historical equivalence merging. The resulting structure exposes shared reasoning paths and localizes divergence points. At each node, T-STAR computes a Q-tree value through Bellman backup, propagating trajectory-level rewards to intermediate reasoning steps. The tree-based node advantage aggregates per-step credit across all trajectories passing through a node, resulting in strict variance reduction ($1/k$ for shared nodes), as established theoretically and confirmed empirically.
This introspective valuation enables trajectory stitching: successful reasoning steps embedded in failed rollouts receive appropriate credit. Divergence points where children’s Q-tree values exhibit large spreads are algorithmically identified, localizing steps where reasoning quality determined outcome. The consolidation process, including functional equivalence testing via KL divergence and historical compatibility checking, is computationally tractable and empirically scales efficiently across task types.
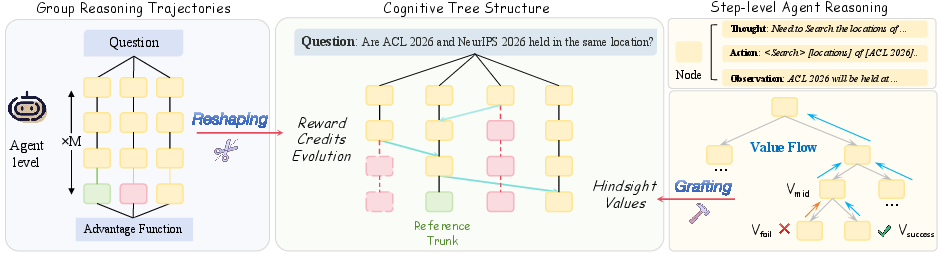
Figure 2: T-STAR overview—trajectory consolidation into a Cognitive Tree, Bellman backup for structural values, and step-level credit propagation with divergence-driven thought grafting.
Thought Grafting and Surgical Policy Optimization
At divergence points, T-STAR utilizes in-context thought grafting to synthesize corrective reasoning by contrasting successful and failed branches. The agent generates a rectified thought that transfers successful logic to the failed context, constructing preference pairs (zrect,z−) for surgical policy optimization. This process is efficiently implemented via controlled forward passes and provides dense step-level supervision grounded in outcome differences.
The resulting hybrid objective combines trajectory-level learning (GRPO) with step-level Bradley-Terry preference loss (surgical optimization), gradients masked to affect only divergence steps. The reference policy is updated via EMA to prevent drift, and each component’s computational scaling is validated to be practical across large models and extensive rollouts.
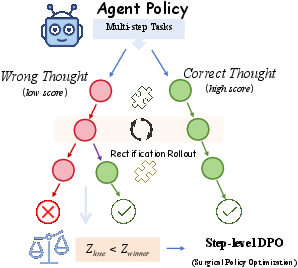
Figure 3: Thought grafting mechanism—agent observes outcome differences at divergence, synthesizes rectified reasoning, and generates step-level preference pairs.
Empirical Results and Training Dynamics
T-STAR demonstrates consistent and pronounced improvement across embodied, interactive, reasoning, and planning tasks. Gains are most evident in settings requiring extended reasoning chains and frequent trajectory overlap. On ALFWorld and WebShop, T-STAR achieves 3–5.8% improvement in success rates. Multi-hop QA benchmarks exhibit largest gains (2.8–7.5%), validating the efficacy of tree-based credit propagation in multi-step contexts. Logical planning tasks such as Sokoban and Blocksworld see 3–8.5% improvements, with enhanced recovery from dead ends via grafted reasoning.
Training dynamics indicate not only faster convergence but substantially greater stability, particularly in environments with sparse rewards (multi-hop QA, Sokoban). Value spreads at divergence points decrease steadily, confirming policy improvement through generalizable corrections rather than instance-specific fixes.
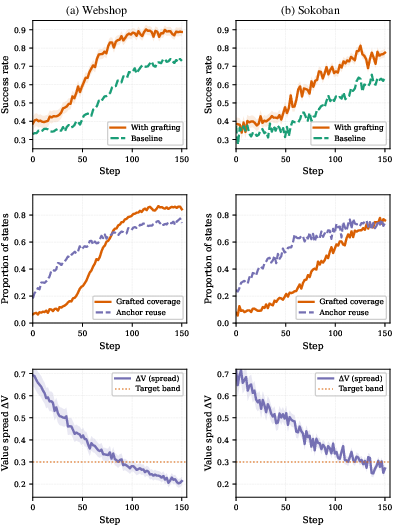
Figure 4: T-STAR training dynamics on WebShop and Sokoban showing increasing grafting coverage, anchor reuse, and decreasing divergence value spread.
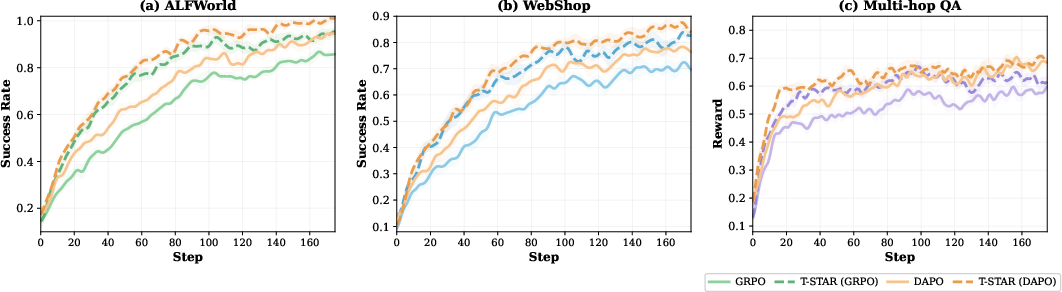
Figure 5: Training curves on ALFWorld, WebShop, and Multi-hop QA highlight faster convergence and higher success rates for T-STAR compared to baselines.
Ablation and Analysis
Comprehensive ablation studies establish that thought grafting accounts for the largest component of T-STAR’s performance (11.6% gain), followed by Q-tree valuation (7.3%) and surgical optimization (2.6%). The method exhibits robust performance across reasonable hyperparameter ranges for KL threshold, divergence threshold, and surgical loss weighting.
Performance improvements correlate strongly with reasoning chain length and merge ratio within the cognitive tree—tasks with longer chains benefit substantially from step-level credit assignment and corrective supervision. Manual analysis confirms >80% semantic validity in grafted thoughts, with corrections accurately addressing reasoning flaws.
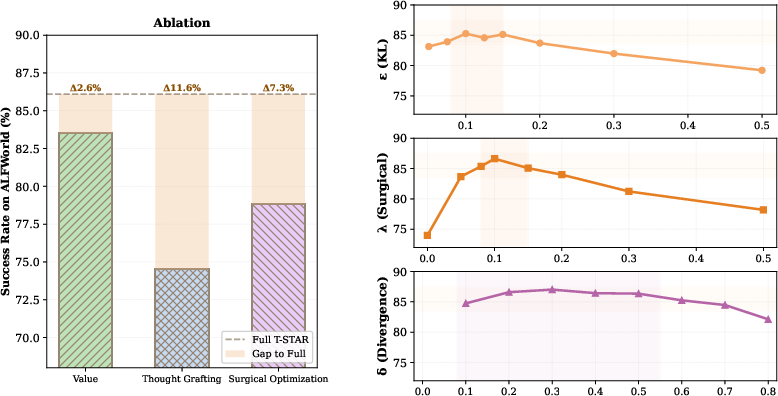
Figure 6: Component ablation and hyperparameter sensitivity confirm primary contributions and robustness of T-STAR.
Implications and Future Directions
T-STAR establishes that independent trajectory rollouts in sparse reward, long-horizon agent RL contain latent shared structure exploitable for variance reduction and precise correction. The consolidation of multi-turn reasoning into cognitive trees enables both variance-reduced advantage estimation and targeted self-rectification, providing stable, scalable, and effective policy optimization.
Practically, T-STAR integrates seamlessly with GRPO, DAPO, GiGPO, and can be generalized to broader sequential decision-making in agentic LLMs. The theoretical invariance and empirical validation suggest an avenue for more efficient RL in text-based and tool-augmented settings. Extending T-STAR to handle continuous action spaces or multimodal observations would further enhance its applicability. Adaptive sampling strategies for equivalence testing and improved rectification in high-entropy states are open technical directions.
Conclusion
T-STAR advances multi-turn LLM agent reinforcement learning by consolidating sampled rollouts into cognitive trees, providing variance-reduced step-level advantage estimation and systematic corrective supervision at critical divergence points through thought grafting. Empirical and theoretical results validate consistent performance improvements across domains requiring extended reasoning chains, notably in environments with sparse rewards. The framework’s modularity and computational efficiency suggest broad applicability for future RL-based agent optimization and policy training.

