- The paper introduces TEMPO, leveraging a Prefix-to-Tree algorithm for precise token-level credit assignment in RL training of LLMs.
- The methodology integrates branch-specific temporal-difference corrections without a critic model, driving faster convergence and improved accuracy.
- Experimental evaluations reveal TEMPO's superiority over PPO and GRPO across various datasets, underlining its efficiency and scalability.
Paper Overview
"Exploiting Tree Structure for Credit Assignment in RL Training of LLMs" (2509.18314) introduces a method called TEMPO, designed to improve reinforcement learning (RL) in the context of LLMs. The method addresses the challenge of credit assignment in RL, specifically in situations where rewards are sparse and delayed over long sequences. TEMPO is built on a novel approach called Prefix-to-Tree (P2T), which converts a group of responses into a prefix tree and computes nonparametric prefix values to enable token-level credit assignment without a critic model.
Methodology
Prefix-to-Tree (P2T)
The P2T algorithm is the foundation for TEMPO, transforming a set of responses into a prefix tree structure. Each node in this tree corresponds to a token prefix, with values estimated by averaging the outcomes of all descendant completions. This method provides a mechanism for valuing non-terminal nodes and focuses reward credit on decision points, overcoming limitations of both Proximal Policy Optimization (PPO) and Group Relative Policy Optimization (GRPO).
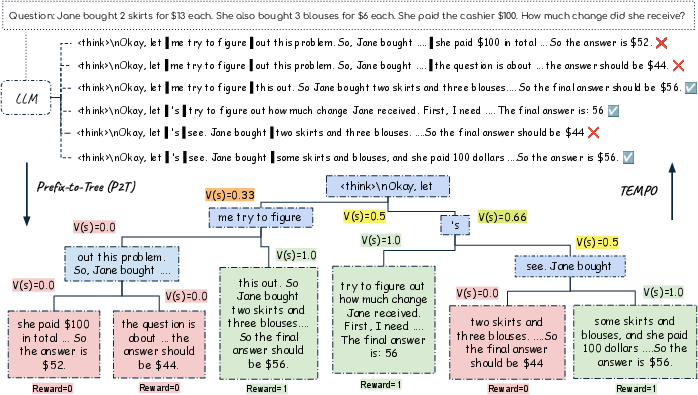
Figure 1: Overview of prefix tree value estimation in TEMPO. Each node corresponds to a token prefix s, with V(s) estimated by averaging over the outcomes of all descendant completions.
TEMPO Algorithm
TEMPO extends GRPO by incorporating branch-specific temporal-difference (TD) corrections. At non-branch tokens, TD errors are zero, reducing the algorithm to GRPO. At branching tokens, TEMPO provides precise token-level credit, leveraging the tree structure without the need for a learned value network or additional judges. This approach maintains computational efficiency while offering more nuanced credit assignment.
Experimental Evaluation
TEMPO is evaluated across in-distribution and out-of-distribution datasets, including MATH, MedQA, GSM-HARD, AMC23, MedMCQA, and MMLU-Medical. It outperforms PPO, GRPO, and HEPO, achieving higher validation accuracy and faster convergence.
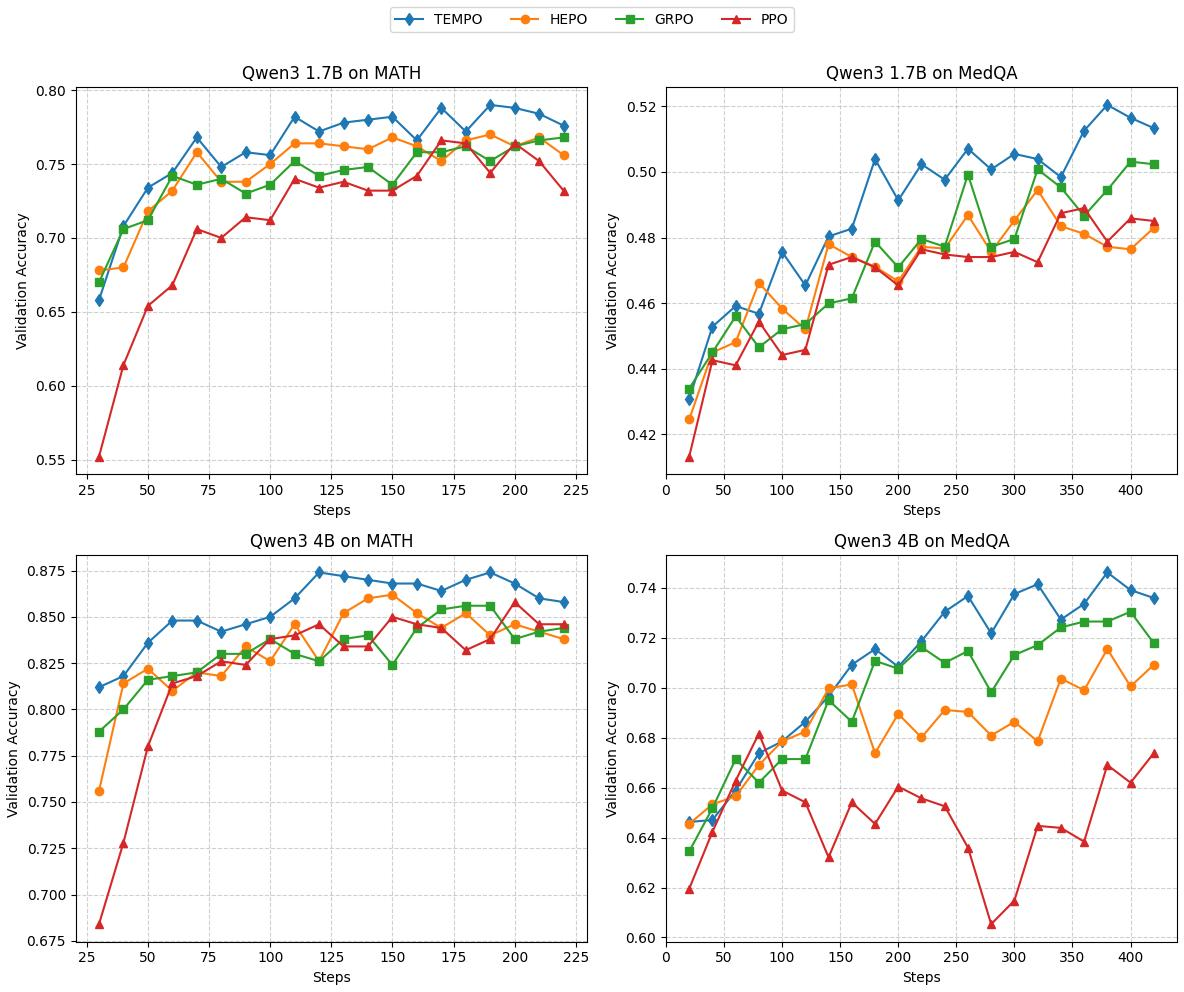
Figure 2: Validation accuracy of MATH and MedQA for Qwen3-1.7B and Qwen3-4B. TEMPO consistently achieves higher accuracy and faster convergence across both domains and model sizes.
Computational Efficiency
TEMPO also demonstrates computational efficiency, achieving peak performance in fewer iterations and less wall-clock time compared to baseline methods. This efficiency is significant when considering practical deployment scenarios where computational resources are constrained.
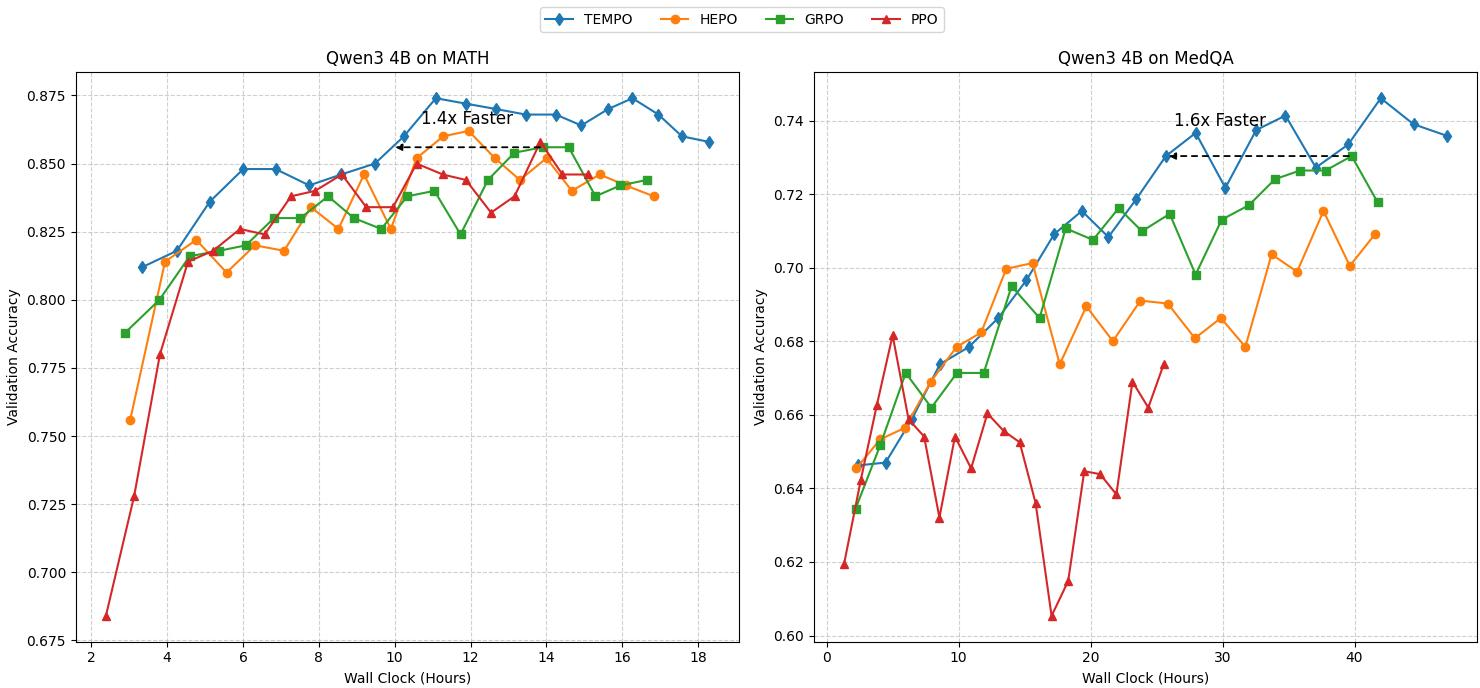
Figure 3: TEMPO converges faster and to higher accuracy than GRPO, surpassing GRPO's peak performance in fewer iterations and less overall time.
Impact of Group Size and Branch Count
The study examines the influence of group size and branching on performance. Larger group sizes contribute to more reliable baselines, and more branches in the prefix tree lead to faster learning and higher final accuracy.


Figure 4: MATH (branching tokens)
Implications and Future Directions
TEMPO represents a significant step in applying RL to LLM training by effectively addressing credit assignment challenges without the overhead of critic models. Its ability to integrate temporal-difference signals into group-relative optimization provides a scalable method for LLM alignment. The paper suggests that this approach could be expanded to incorporate multi-step verifications and retrieval-augmented reasoning tasks, potentially broadening the applicability of RL in diverse reasoning contexts.
Conclusion
The introduction of TEMPO offers a practical and efficient solution for credit assignment in RL when training LLMs, leveraging tree-structured TD corrections to enhance accuracy and speed. The empirical results support its advantages over existing methods, highlighting its potential for broader application in advanced AI systems where efficiency and precision in learning are paramount.