- The paper presents a two-stage framework that integrates multimodal synthesis with symbolic reasoning to boost performance on tabular QA tasks.
- Experimental results on WikiTQ and TabFact show significant accuracy gains and reduced query complexity compared to traditional methods.
- Ablation studies reveal that both the Coarse and Fine stages are critical for robustness and efficiency, especially in handling large, complex tables.
Coarse-to-Fine Multimodal Synthesis for Enhanced Tabular Reasoning
Introduction
The challenge of developing AI systems that can robustly reason over semi-structured tabular data remains central to progress in question answering and fact verification tasks. While recent LLMs have achieved substantial advances in open-domain text-based QA, their performance on tabular domains is limited by the inherently complex, multimodal characteristics of tables and the ambiguity and diversity of queries. Prior symbolic-only approaches exhibit bottlenecks in holistic pattern discovery and suffer from inefficiencies in traversing the search space, especially when tables are large or visually-encoded information is essential. The CFMS (Coarse-to-Fine Multimodal Synthesis) framework introduces a two-stage architecture designed to mitigate these limitations via a principled division of hierarchical multimodal perception and iterative symbolic manipulation.
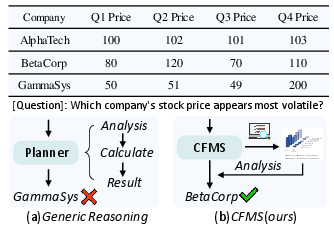
Figure 1: CFMS leverages a Coarse Stage using MLLMs for holistic visual and semantic perception, prior to efficient targeted symbolic computation in its Fine Stage.
Framework Architecture
CFMS operationalizes hierarchical tabular reasoning via two decoupled stages: the Coarse Stage for knowledge synthesis and the Fine Stage for iterative reasoning. In the Coarse Stage, the system implements a multi-perspective analysis using external MLLMs and code-oriented LLMs to extract complementary knowledge views: (1) visual insights via chart generation and description, (2) semantic rationale grounding via knowledge base-augmented prompts, and (3) statistical summaries via guided CoT prompts. The outputs are serialized into a compact, textual knowledge tuple, Kcoarse, serving as a structured, multimodal context.
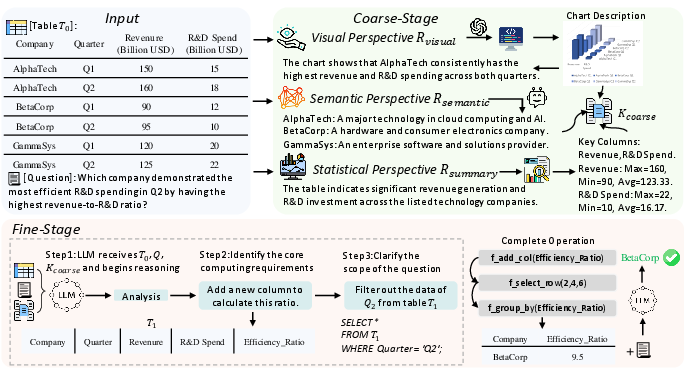
Figure 2: The overall CFMS pipeline: holistic analysis and multimodal knowledge synthesis precede targeted fine-grained table operations.
The Fine Stage is a symbolic reasoning engine driven by a planning policy πLLM conditioned on the question, current table state, operation history, and Kcoarse. The planner selects high-level table transformation operations (e.g., f_add_column, f_select_row) and parameters, evolving the table iteratively. This fundamentally extends the Chain-of-Table paradigm by fusing explicit multimodal priors, enabling the system to bypass brute force symbolic sampling and reduce sample complexity.
Experimental Results
Evaluations on WikiTQ (complex QA) and TabFact (binary fact verification) benchmarks demonstrate the effectiveness and transferability of CFMS. On WikiTQ, accuracy improves from 51.84% (End-to-End QA) and 59.94% (Chain-of-Table) to 61.42% under the GPT-3.5 backbone. On TabFact, CFMS achieves 81.37%, compared to 70.45% (End-to-End QA) and 80.20% (Chain-of-Table), validating its SOTA position. Importantly, CFMS preserves robustness as table size increases; accuracy degradation on large tables is smaller versus prior baselines.
Notably, CFMS outperforms comparators even when instantiated with smaller LLMs (e.g., LLaMA-2-13B), indicating that its architectural advantages are model-agnostic. The accuracy margin increases in resource-constrained and long-context settings, substantiating the benefit of hierarchical coarse-to-fine reasoning.
Efficiency and Long-Chain Reasoning
A key contribution of CFMS is its reduction in the number of model queries required per instance. While standard program-aided methods (Binder, Dater) may exceed 50-100 queries per question due to brute force search or self-consistency sampling, CFMS typically requires ≤15, with just 4 queries for the Coarse Stage and ≤10 for the Fine Stage. This reflects a substantial improvement in sample efficiency, computational cost, and end-to-end latency, making the framework favorable for deployment on real-world, large-scale tabular QA tasks.
For QA requiring long operation chains, CFMS consistently maintains superior accuracy across increasing chain lengths, indicating its effectiveness in complex multi-step reasoning scenarios.
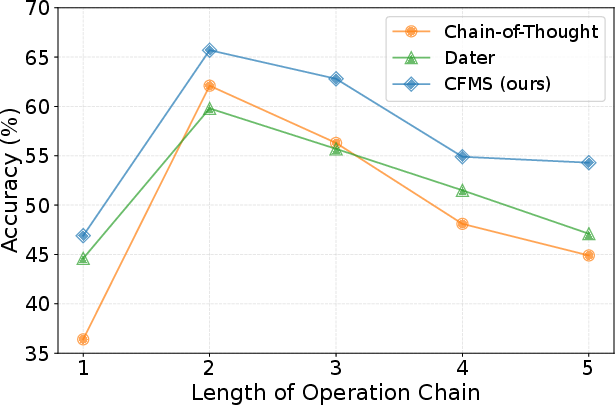
Figure 3: Accuracy of CFMS versus baselines across different operation chain lengths on WikiTQ.
Ablation Analysis
Component ablations underscore the integral nature of both Coarse and Fine stages. Removal of the Coarse Stage alone results in a 7.82% (TabFact) or 6.24% (WikiTQ) absolute accuracy decline, highlighting the value of holistic knowledge synthesis for downstream symbolic planning. Similarly, exclusion of individual symbolic operations (e.g., f_select_row, f_select_column, f_group_by) leads to significant performance drops, confirming the necessity of a rich, expressive symbolic operator set for fine-grained reasoning.
Implications and Future Directions
Practically, CFMS offers a modular pathway to leverage the synergies of multimodal models and symbolic reasoning in structured data domains while retaining efficiency and robustness. Its architectural principles can be generalized to other domains where hierarchical, coarse-to-fine strategies are advantageous, such as vision-language understanding and scientific data analysis.
Theoretically, CFMS advocates for explicit decoupling of perception and reasoning as an essential design paradigm, moving away from monolithic, end-to-end architectures that struggle with context fragmentation and inefficient resource use. Open research directions include (1) error correction and uncertainty tracking across coarse-to-fine boundaries, (2) joint training for more effective multimodal knowledge distillation, and (3) extension to open-domain heterogeneous tables with complex schema.
Conclusion
CFMS sets a new standard for tabular reasoning by combining holistic multimodal perception and efficient symbolic iteration. Empirical gains in accuracy, generalizability, and execution efficiency establish hierarchical, multimodal knowledge synthesis as a critical direction for next-generation reasoning systems operating on structured data. Ongoing research stemming from CFMS will likely further solidify the role of coarse-to-fine integration, multimodal priors, and explicit symbolic reasoning in robust, scalable AI.