- The paper introduces a scalable, open-domain dataset for reasoning over complex table images using a modular LaTeX generation pipeline.
- The methodology integrates cross-model inspiration, automated QA generation, and multi-stage validation to ensure high-quality, diverse data.
- Experimental findings show enhanced transferability and improved performance on both visual and textual reasoning tasks across model types.
Visual-TableQA: Open-Domain Benchmark for Reasoning over Table Images
Motivation and Context
Visual reasoning over structured data, particularly rendered table images, remains a significant challenge for vision-LLMs (VLMs). Existing benchmarks are either limited in scale, diversity, or reasoning depth, and most focus on textual representations or domain-specific layouts, failing to capture the complexity of real-world tabular data. Visual-TableQA addresses these gaps by introducing a large-scale, open-domain multimodal dataset specifically designed to evaluate and enhance visual reasoning over complex table images. The dataset leverages a modular, scalable, and fully autonomous generation pipeline, integrating multiple LLMs for generation, validation, and inspiration, and is produced at minimal cost.
Dataset Construction and Pipeline
Visual-TableQA comprises 2,500 richly structured LaTeX-rendered tables and 6,000 reasoning-intensive QA pairs. The pipeline is built around the principles of Code-as-Intermediary Translation (CIT), using LaTeX as an intermediate representation to efficiently generate complex tables and minimize annotation costs.
The pipeline consists of several stages:
- Seed Collection: Diverse table layouts and topics are collected from various sources, including scientific journals and financial reports. Initial table images are converted to LaTeX using a visual LLM (VLM-0), and 5,000 topic prompts are generated by an LLM.
- Table Generation: For each iteration, an LLM receives a table sample and three topics, generating three new LaTeX tables inspired by the input but with substantial layout and data variations. The LaTeX code is compiled and visually inspected for quality.
- Cross-Model Inspiration: Generated tables are iteratively added to the inspiration pool, enabling cross-model prompting and fostering layout diversity through collaborative synthesis.
- QA Generation: Another LLM generates three reasoning-intensive QA pairs per table, focusing on multi-step reasoning, pattern recognition, and symbolic interpretation.
- Quality Assurance: A jury of high-performing LLMs evaluates each table and QA pair for validity, coherence, and grounding, using the ROSCOE reasoning score for step-by-step rationale assessment. Human annotators further validate a subset of QA pairs.
Figure 1: Full pipeline architecture of Visual-TableQA, illustrating the multi-stage, multi-model collaborative generation and validation process.
Dataset Properties: Diversity and Complexity
Visual-TableQA emphasizes structural reasoning over domain knowledge, coupling rendered table images with visually grounded reasoning tasks. Tables feature complex layouts, multirow cells, integrated diagrams, and color encoding, requiring models to interpret visual cues and perform multi-step logical analysis.
Topic diversity is ensured by clustering 5,000 topics using UMAP and K-Means, resulting in balanced semantic coverage. Layout diversity is achieved through iterative cross-model inspiration, producing a wide range of table structures from limited seeds.
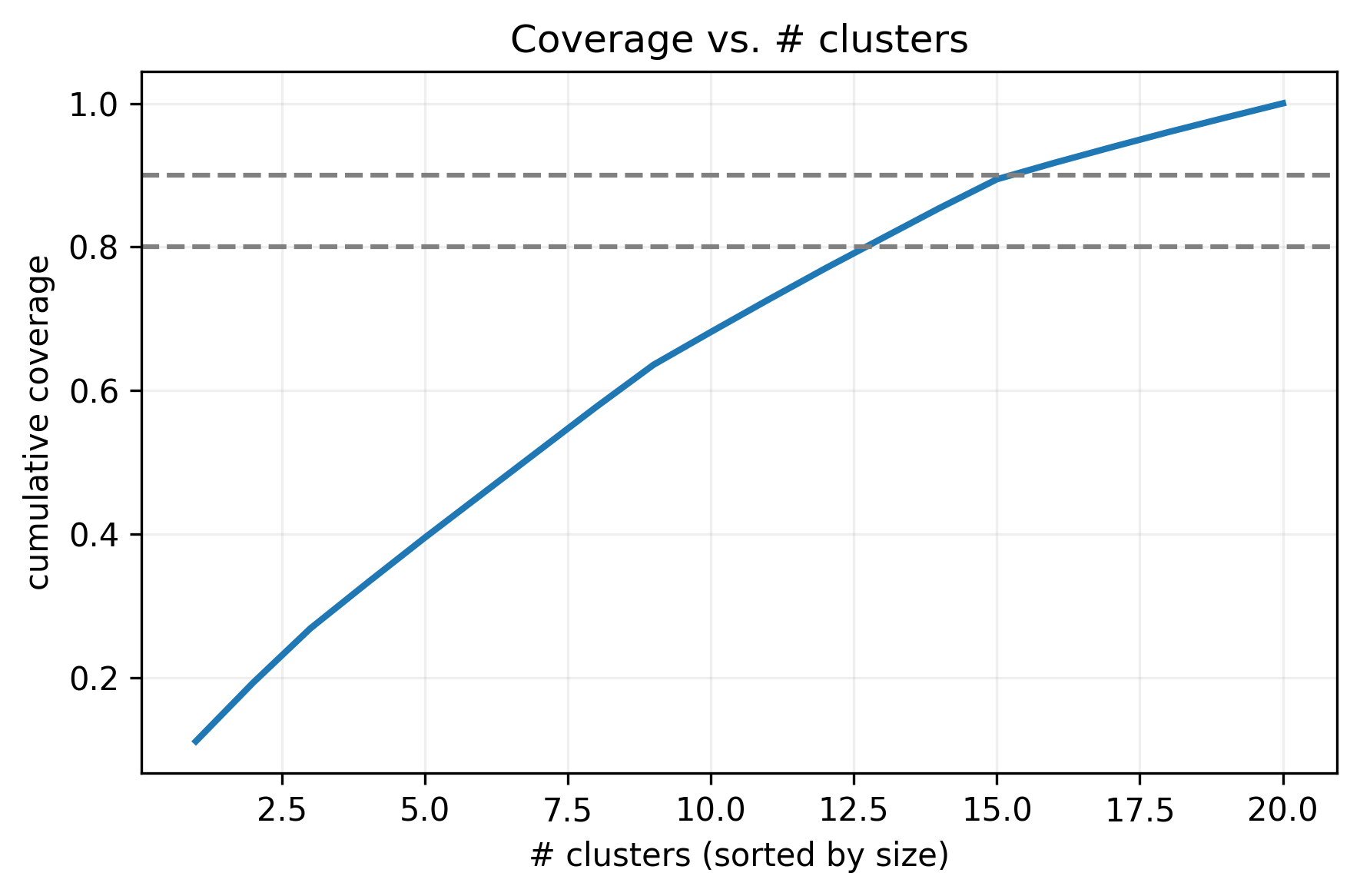
Figure 2: Cumulative topic coverage curve, demonstrating uniform distribution of topics across clusters.
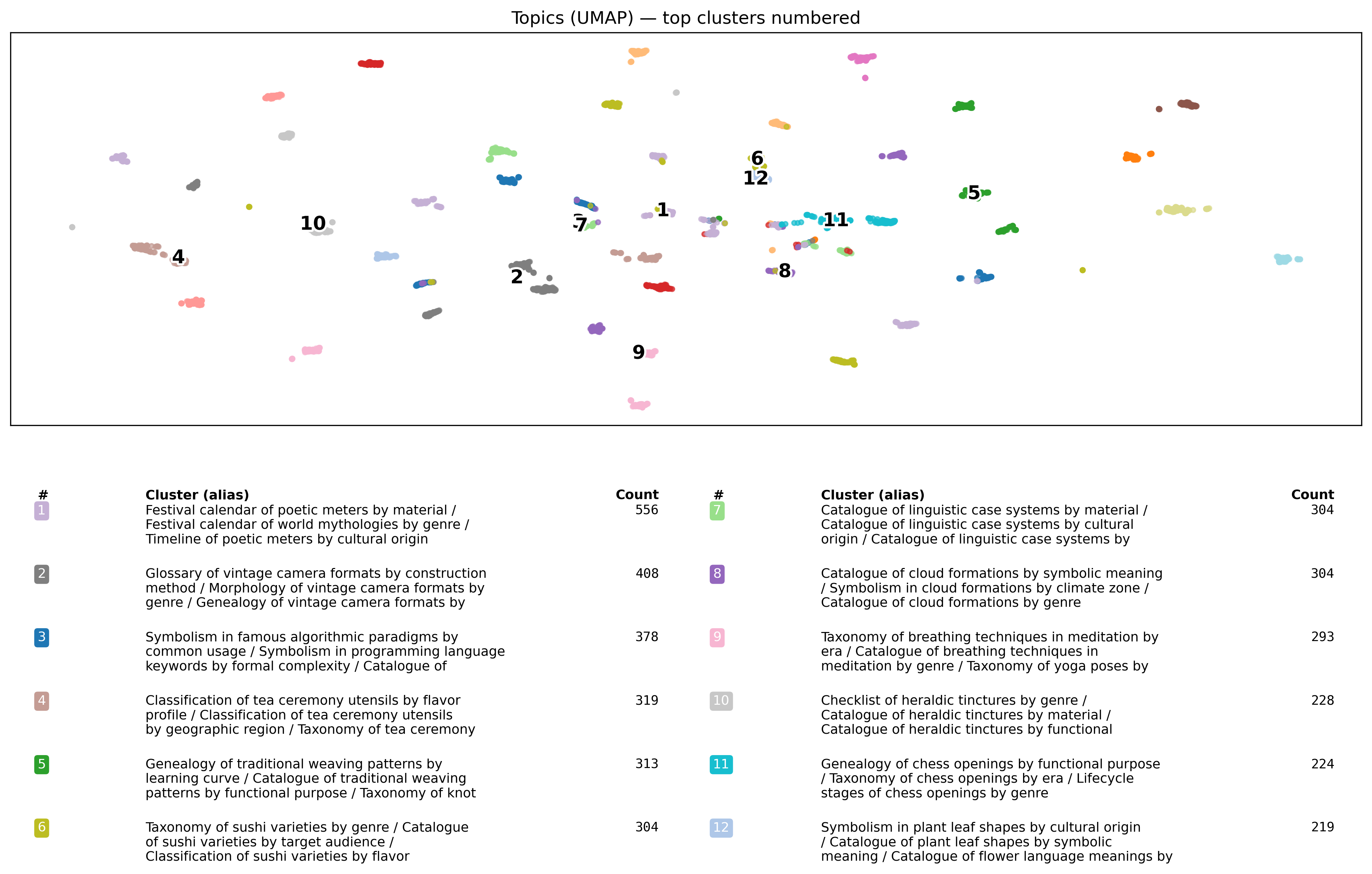
Figure 3: 2D projection of 5,000 topics, with semantic clusters and representative topics illustrating diversity.


Figure 4: Initial layout seeds used for table generation, serving as inspiration for subsequent iterations.
Experimental Evaluation
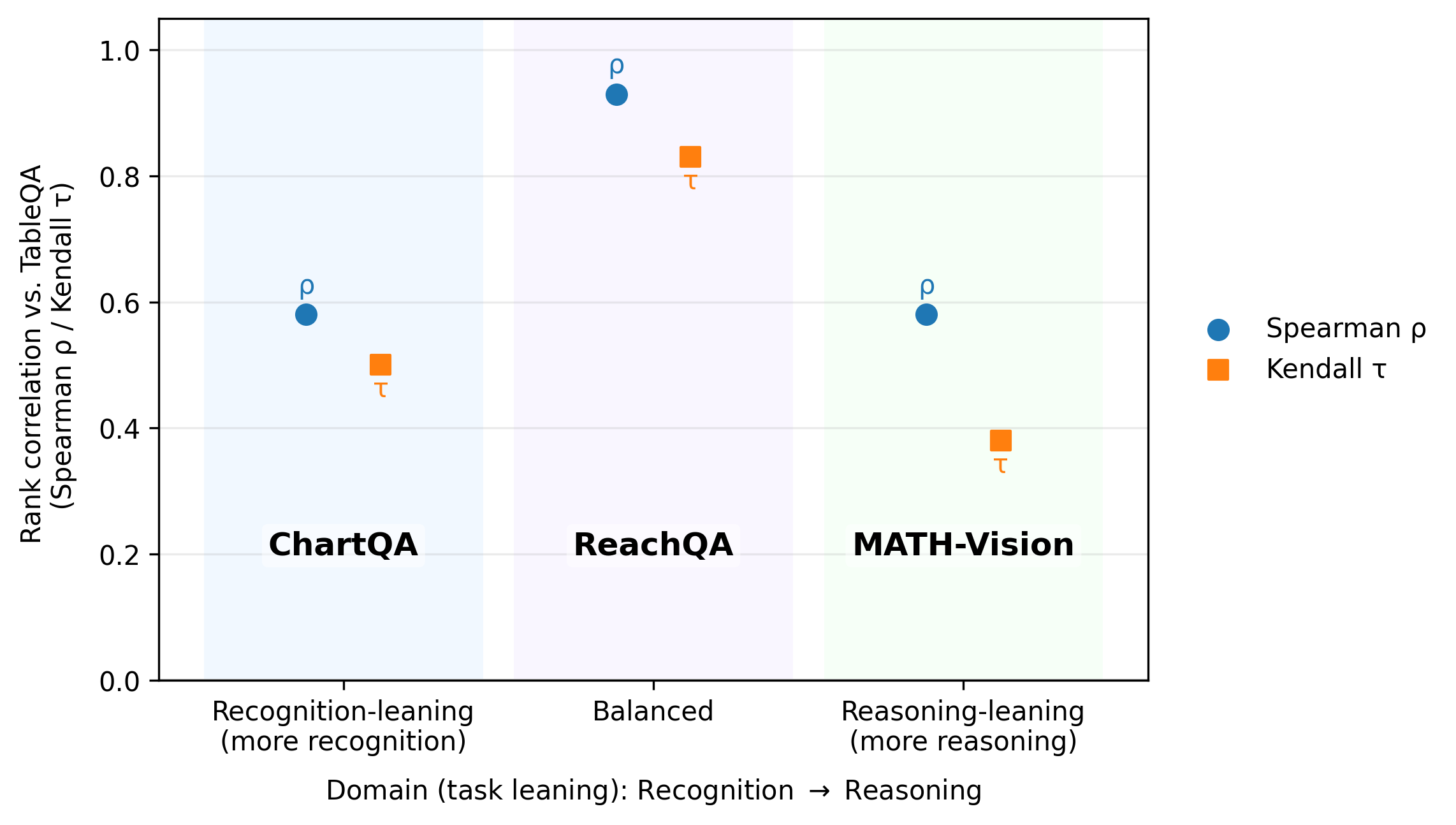
Visual-TableQA is benchmarked against ChartQA, ReachQA, and MATH-Vision, covering recognition-heavy, balanced, and reasoning-heavy tasks, respectively. A broad spectrum of VLMs, both proprietary and open-source, are evaluated using a unified prompt and majority-vote LLM jury.
Key findings include:
Error Analysis and Quality Metrics
A detailed error taxonomy for Qwen2.5-VL-7B-Instruct reveals that fine-tuning on Visual-TableQA shifts errors toward incoherence, with reductions in hallucination and partial data extraction. This suggests more consistent reasoning patterns post-finetuning, but highlights the need for targeted synthetic supervision to address specific error types.
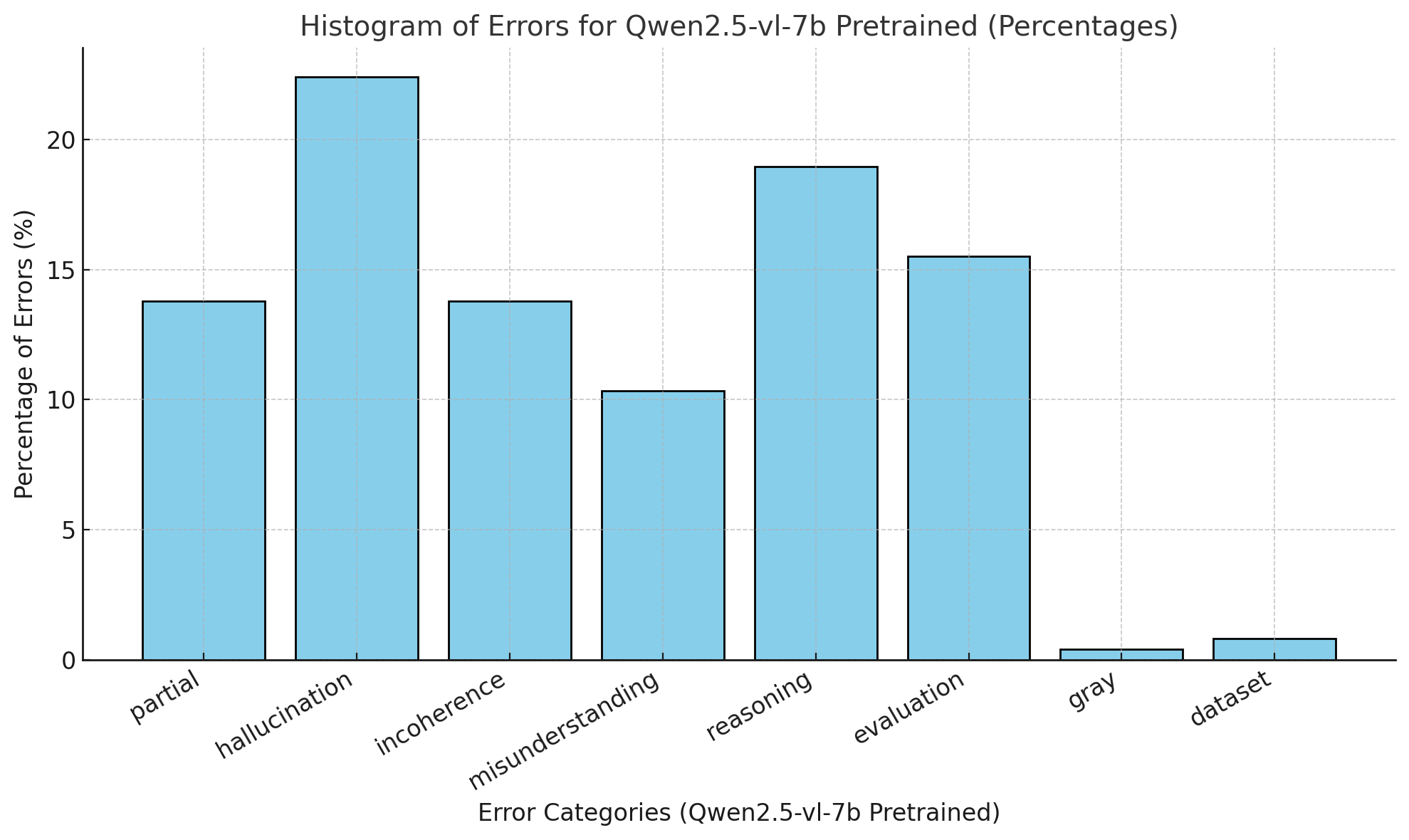
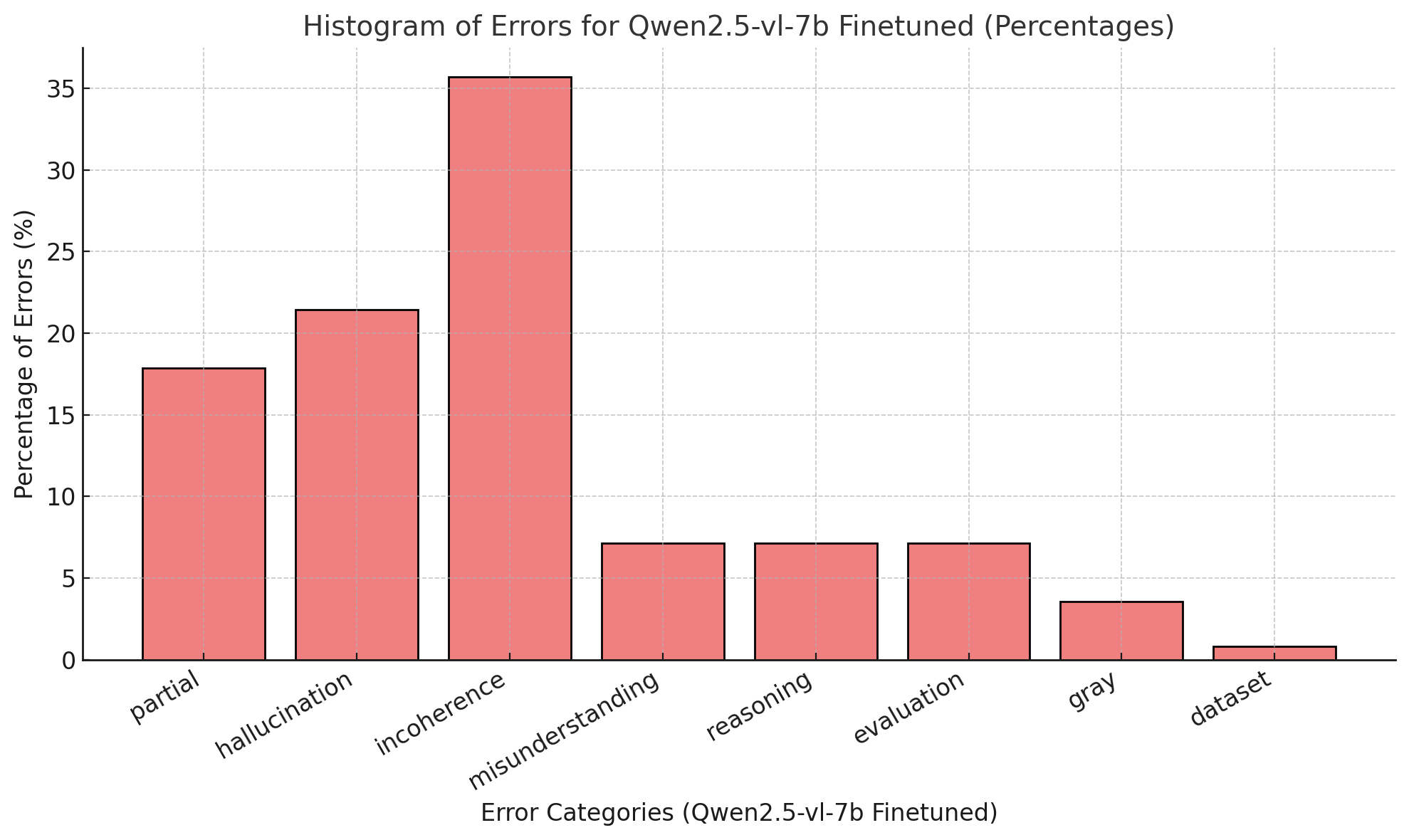
Figure 6: Histogram of errors for Qwen2.5-vl-7b, illustrating error distribution before and after fine-tuning.
ROSCOE metrics indicate near-perfect semantic adequacy, low redundancy, high logical inference, and strong grammaticality, supporting the overall quality of generated rationales.
Practical Implications and Future Directions
Visual-TableQA's modular, scalable pipeline enables cost-efficient, high-quality dataset generation, facilitating knowledge distillation and transfer learning for multimodal reasoning tasks. The collaborative cross-model inspiration mechanism fosters diversity and creativity, making the dataset particularly effective for training models with transferable reasoning skills.
The dataset's strong empirical results and transferability suggest its utility as a general-purpose benchmark for visual reasoning over structured data. However, limitations remain in LaTeX expressiveness for complex images and the reliability of automated evaluation metrics. Future work should focus on developing robust bidirectional image-to-text encoding systems and hybrid evaluation strategies combining automated and human verification.
Conclusion
Visual-TableQA establishes a new standard for open-domain visual reasoning benchmarks over table images, offering unprecedented diversity, reasoning depth, and scalability. Its pipeline demonstrates that synthetic datasets, when carefully constructed and validated, can effectively challenge and improve state-of-the-art VLMs. The dataset's transferability and modularity position it as a valuable resource for advancing multimodal reasoning and bridging the performance gap between open-source and proprietary models.