Do Large Language Models Reason Causally Like Us? Even Better?
Abstract: Causal reasoning is a core component of intelligence. LLMs have shown impressive capabilities in generating human-like text, raising questions about whether their responses reflect true understanding or statistical patterns. We compared causal reasoning in humans and four LLMs using tasks based on collider graphs, rating the likelihood of a query variable occurring given evidence from other variables. LLMs' causal inferences ranged from often nonsensical (GPT-3.5) to human-like to often more normatively aligned than those of humans (GPT-4o, Gemini-Pro, and Claude). Computational model fitting showed that one reason for GPT-4o, Gemini-Pro, and Claude's superior performance is they didn't exhibit the "associative bias" that plagues human causal reasoning. Nevertheless, even these LLMs did not fully capture subtler reasoning patterns associated with collider graphs, such as "explaining away".
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper asks: Do big AI chatbots think about cause and effect like people do? The authors test four well-known LLMs (GPT-3.5, GPT-4o, Claude-3 Opus, and Gemini-Pro) on the same kind of cause-and-effect problems that college students solved in a psychology study. They compare how “human-like” the AIs are, and how close they are to what the math says you should conclude in these situations.
The main questions the researchers asked
- Can LLMs do basic cause-and-effect reasoning, not just repeat patterns from text?
- Do they show the same kinds of mistakes people make?
- Which models match the “correct” answers best (the ones predicted by a standard math model of causality)?
- Do models rely on background world knowledge in ways people didn’t in this experiment?
How the study worked (with simple analogies)
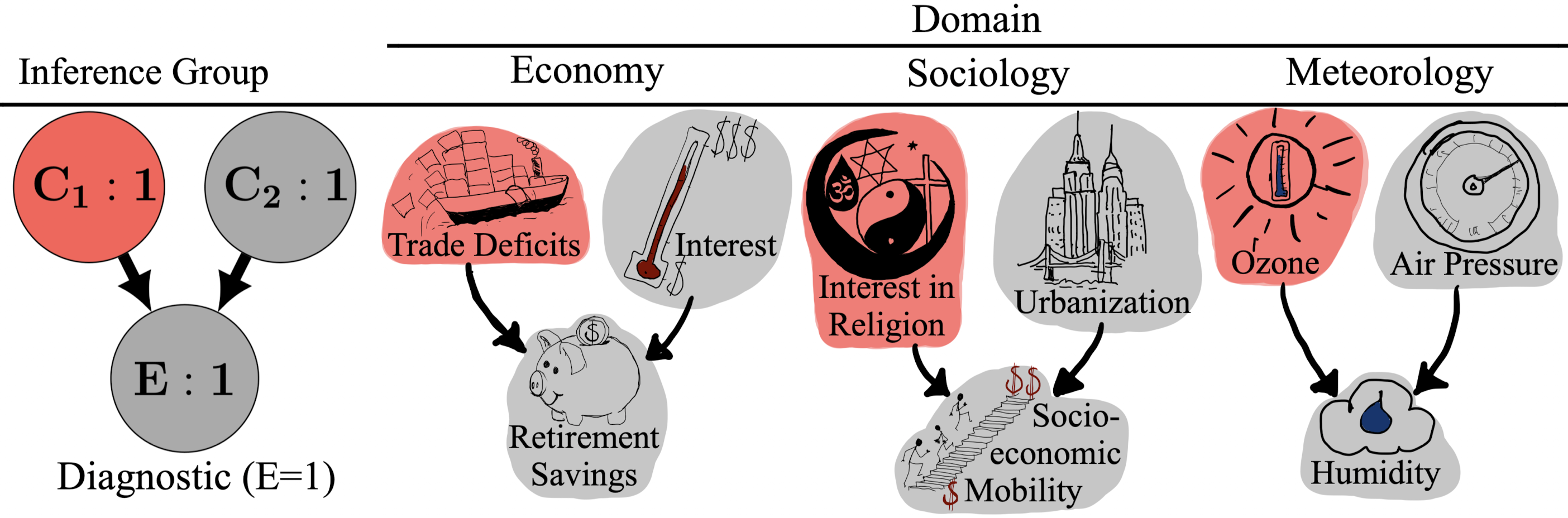
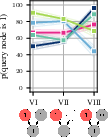
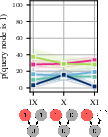
The team focused on a simple cause-and-effect setup called a “collider.” Think of it like this:
- Two different causes, C1 and C2, can both lead to the same effect, E.
- Example: Rain (C1) and the sprinkler (C2) can both make the grass wet (E).
From this setup, four types of questions were asked:
- Predictive: If we know which causes are happening, how likely is the effect?
- Example: If the sprinkler is on and it’s raining, how likely is wet grass?
- Independence of causes: Before looking at the effect, the two causes shouldn’t affect each other.
- Example: Just knowing the sprinkler is on shouldn’t make rain more or less likely.
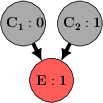
- Diagnostic (effect present): If the effect is happening (the grass is wet), learning that one cause happened (sprinkler was on) should make the other cause less likely (rain). This is called “explaining away.”
- In everyday words: If you know the grass is wet and you also know the sprinkler was on, you don’t need rain to explain the wetness, so rain becomes less likely.
- Diagnostic (effect absent): If the effect is not happening (grass is dry), both causes become less likely, and “explaining away” isn’t expected.
What did participants do?
- Humans: In a past study, college students learned short stories from three areas (weather, economy, society) describing these cause-effect links. Then they rated how likely something was (0–100).
- AIs: The same stories and questions were given to the four LLMs via their APIs. The models were asked to reply with a single number from 0 to 100. The test used temperature 0.0 (the “most consistent” setting) so the outputs didn’t vary randomly.
What is the “math model” they compared to?
- A causal Bayes net (think: a formal calculator for cause-and-effect). It tells you the “normative” answer—what you should conclude if you follow the rules of probability exactly.
- They also tried a psychology-inspired model called the “mutation sampler,” which imitates how people might take a few mental “samples” instead of doing perfect math, leading to human-like shortcuts and mistakes.
What they found and why it matters
Here are the main takeaways:
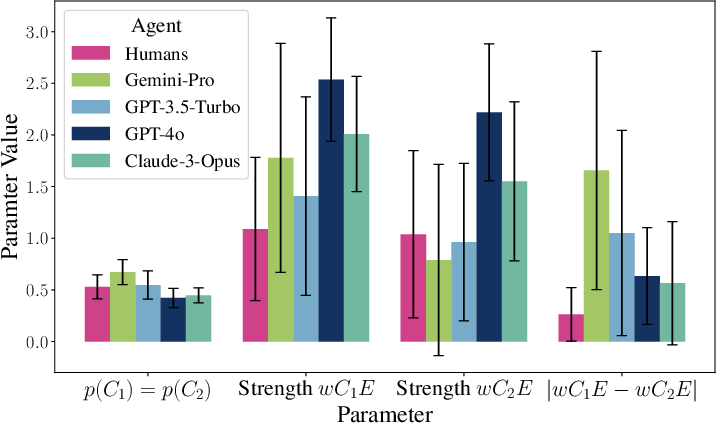
- All models did the basics: They understood that more causes make the effect more likely (predictive reasoning worked).
- Explaining away (diagnostic with effect present):
- GPT-4o and Claude showed strong “explaining away” (very close to what the math predicts).
- Gemini-Pro and GPT-3.5 didn’t explain away—they sometimes did the opposite, treating causes as if they made each other more likely.
- Independence of causes (before seeing the effect, causes shouldn’t influence each other):
- Humans often break this rule a bit (a known human bias).
- Gemini-Pro and GPT-3.5 also broke it, and even more than humans.
- Claude violated it the least.
- GPT-4o showed a small violation in the opposite direction.
- How close were the models to humans overall?
- Claude and GPT-4o lined up most with human answer patterns.
- How close were the models to the “correct math” answers?
- GPT-4o and Claude matched the math model best (even better than the average human in this study).
- GPT-3.5 and Gemini-Pro were worse than humans by this measure.
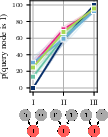
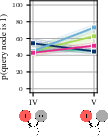
- Do models use background knowledge?
- Humans were trained to ignore their prior knowledge and just use the given story, and their answers didn’t change much across domains.
- The AIs did vary more by topic (weather vs. economy vs. society), suggesting they pulled in outside knowledge from training.
- Are AI answers too extreme?
- The AIs used the full 0–100 range more than humans did. One practical reason: humans used a slider that started at 50, which nudged them toward the middle.
- Human-like mistakes in AIs:
- A psychology-inspired “shortcut” model (mutation sampler) fit humans well and also fit three of the four AIs better than the pure math model. This suggests many AIs show human-like associative shortcuts—except GPT-4o, which stayed closest to the math.
Why this is important
- Good news: Some AI models (GPT-4o and Claude) can reason about cause and effect in ways that are both human-like and close to the correct math.
- Caution: Other models (GPT-3.5 and Gemini-Pro) showed biases like people do—sometimes even stronger—such as failing to explain away or treating independent causes as if they go together.
- Big picture: As AIs help with real decisions (health, policy, safety), we need to know their strengths and biases in cause-and-effect reasoning, not just their ability to sound fluent.
What this means for the future
- Testing matters: We should routinely check AIs for causal reasoning biases, because these can change by model, topic, and even prompt settings.
- Better design: Insights from this work can guide training and prompting so models follow causal rules more reliably.
- More to explore: This study focused on one simple network (a collider). Future work could test more complex cause-and-effect patterns, actions and interventions, and how prompting (like chain-of-thought) or temperature settings change performance.
In short: Some LLMs can reason about causes impressively well—sometimes even more “by-the-book” than people—while others still fall into common human-like traps. Knowing the difference helps us use AI more safely and wisely.
Collections
Sign up for free to add this paper to one or more collections.

