- The paper demonstrates that refined prompting improves descriptive fit of LLMs, yet fails to ensure accurate causal effect estimation.
- It reveals that despite lower mean errors and higher rank correlations, LLM-derived causal estimates have nearly doubled errors compared to regression baselines.
- The study uncovers structural biases where demographic and methodological disparities lead to unreliable intervention forecasts using LLMs.
Divergence Between Descriptive Fit and Causal Fidelity in LLM Behavioral Simulation
Overview and Motivation
LLMs have been rapidly adopted for behavioral simulation tasks, allowing researchers to produce synthetic estimates of human responses to interventions across broad populations using natural language prompts. This paper, "When simulations look right but causal effects go wrong: LLMs as behavioral simulators" (2604.02458), interrogates the reliability of LLMs in forecasting intervention-induced changes, specifically within the domain of climate psychology. The authors leverage three LLMs (GPT-4o-mini, Gemini 2.5 Flash Lite, Claude 3 Haiku) and evaluate their outputs against cross-national experimental datasets comprising more than 59,000 participants across 62 countries, further replicating results in additional datasets. The analysis systematically decomposes descriptive fit and causal fidelity, emphasizing their divergence in empirical accuracy and error structure.
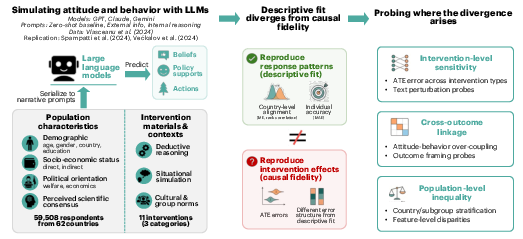
Figure 1: Roadmap outlining the evaluation framework, datasets, and methodological sequence of the study.
Descriptive Fit Versus Causal Fidelity
LLMs exhibit competent recovery of population-level attitudes and cross-national descriptive statistics such as means and distributional profiles. Baseline prompting produces modest mean errors for attitudinal outcomes, with prompting refinements (KNN-based few-shot and VBN-based chain-of-thought) further elevating descriptive alignment, as measured by decreases in mean absolute error (MAE), increases in country-level Spearman correlations, and reduced Jensen-Shannon divergences. Notably, variance compression is observed: model predictions consistently undershoot the full population variance observed in empirical data, indicating central tendency fit but diminished coverage of heterogeneity.
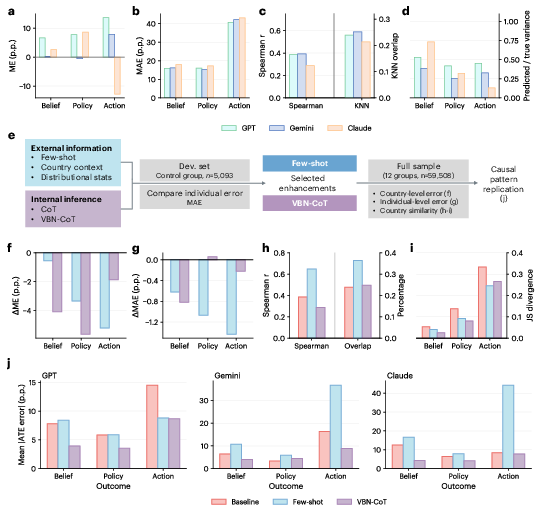
Figure 2: Descriptive fit metrics (mean error, MAE, rank correlation, variance ratio) and pipeline for prompting enhancement; the improvement in descriptive metrics with refined prompting.
Contrastingly, causal fidelity—quantified as the accuracy in predicting average treatment effects (ATEs) following interventions—remains substantially weaker. LLM absolute ATE error nearly doubles that of supervised regression baselines, despite comparable descriptive MAE. Furthermore, prompting techniques that optimize descriptive fit do not necessarily minimize causal ATE error; in specific domains (notably behavioral outcomes), certain prompting refinements exacerbate causal bias, challenging the assumption that descriptive alignment equates to intervention forecasting reliability.
Structural Divergence in Error Patterns
Error decomposition reveals that descriptive inaccuracies are dominated by outcome type (e.g., belief vs. behavior), with little effect from method or country. In contrast, causal errors redistribute variance across method, country, and their interactions; outcome type becomes secondary. Mixed-effects modeling indicates amplified country-level heterogeneity in causal evaluation (intraclass correlation coefficients escalating from ~1% in descriptive to >13% in causal error), a pattern robustly replicated across datasets.
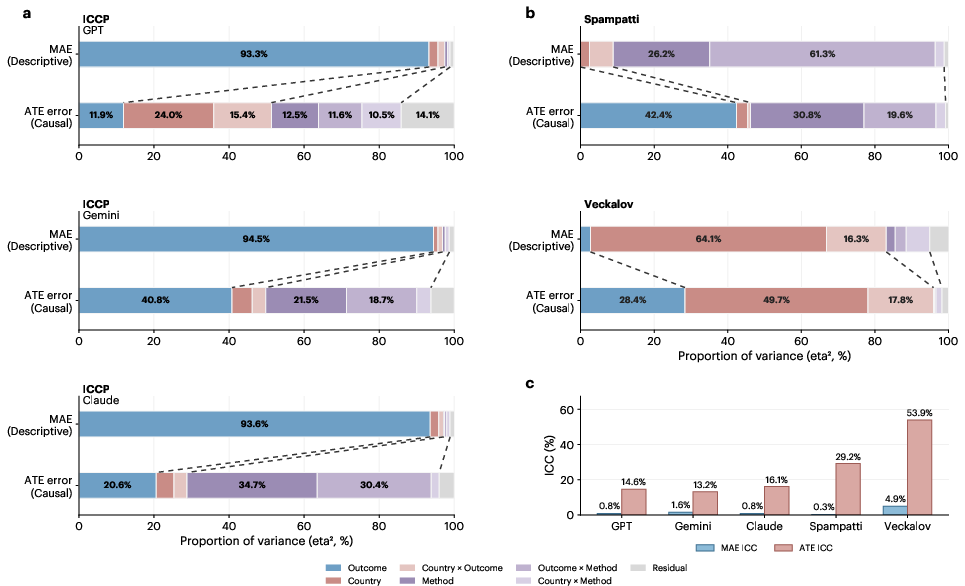
Figure 3: Structural variance decomposition; outcome type governs descriptive error, but method and country dominate causal error with increased heterogeneity.
Intervention-level analysis highlights category-specific sensitivity: situational simulation mechanisms yield largest causal overestimation and instability, especially for behavioral outcomes, while group norms induce minimal bias. Additionally, LLMs enforce stronger attitude-behavior coupling than documented in empirical human data; model-generated correlations for belief-action and policy-action surpass those witnessed experimentally, subverting the observed intention-behavior gap. Perturbation probes show attitudinal estimates are modifiable via intervention text editing, but behavioral estimates resist coherent adjustment, even with explicit instruction to decouple attitudes and behaviors.
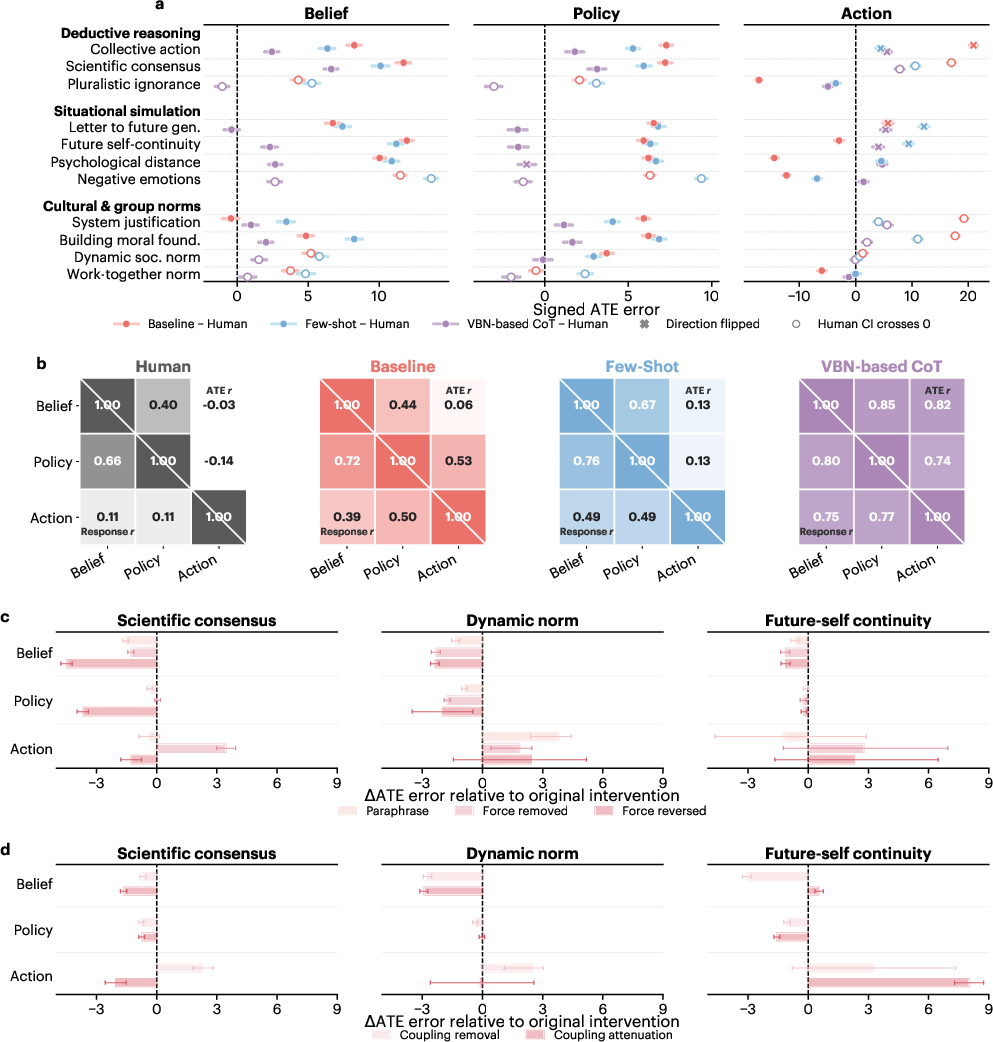
Figure 4: Intervention-level causal bias, cross-domain coupling in human vs. model simulations, sensitivity to intervention content, and impact of attitude-behavior coupling prompts.
Population-Level Implications and Inequality Structuring
At the country and subgroup level, descriptive and causal errors are weakly correlated. Rank-ordering by MAE and ATE error produces divergent lists: the countries or groups best matched descriptively are often not those with accurate causal inference. Descriptive gains cluster in OECD nations and high-internet countries, but these structural advantages do not transfer to causal fidelity. Demographically, descriptive improvement is largest for age and gender, whereas causal disparities emerge along political orientation and socioeconomic status. This divergence reshapes fairness analysis—descriptive validation masks structured inequalities in causal reliability and potentially deepens population-level misrepresentation.
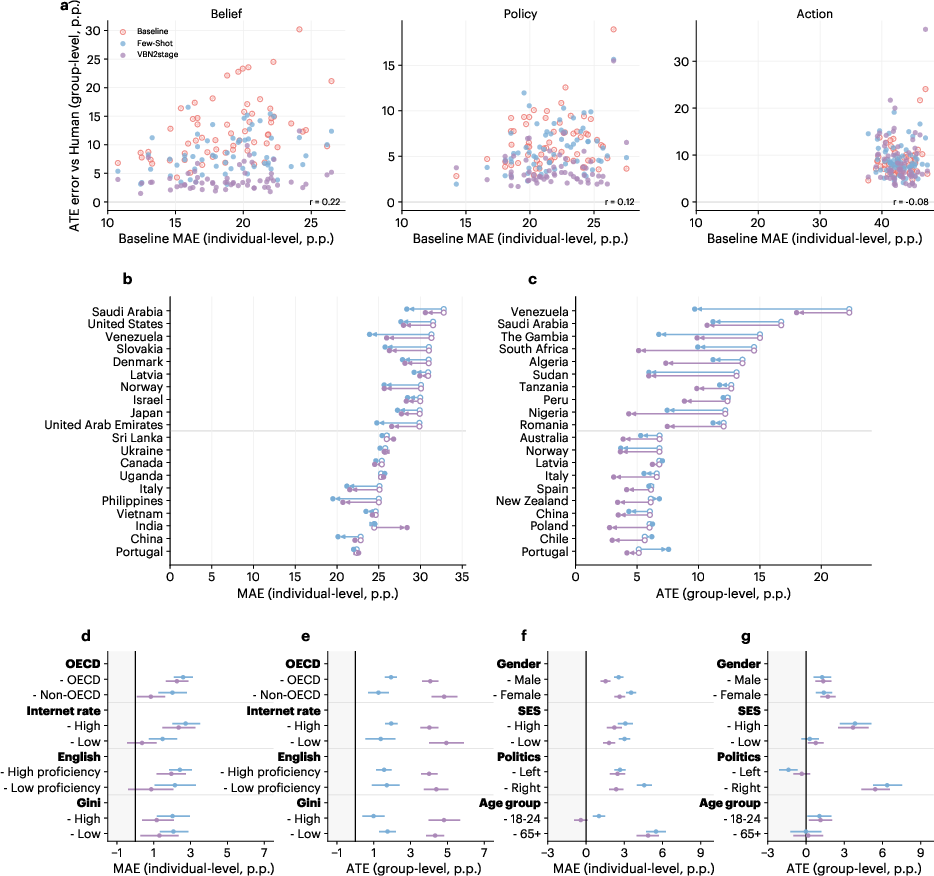
Figure 5: Comparison of countries and demographic groups ranked by descriptive and causal error, demonstrating minimal overlap and altered inequality profiles with prompting enhancements.
Feature importance analysis (SHAP) further distinguishes drivers: statistical properties like outcome mean and historic MAE dominate descriptive error changes, whereas causal error changes are linked more closely to socioeconomics (e.g., Gini coefficient, internet penetration), elucidating different correspondence between enhancement-induced error shifts and underlying population attributes.
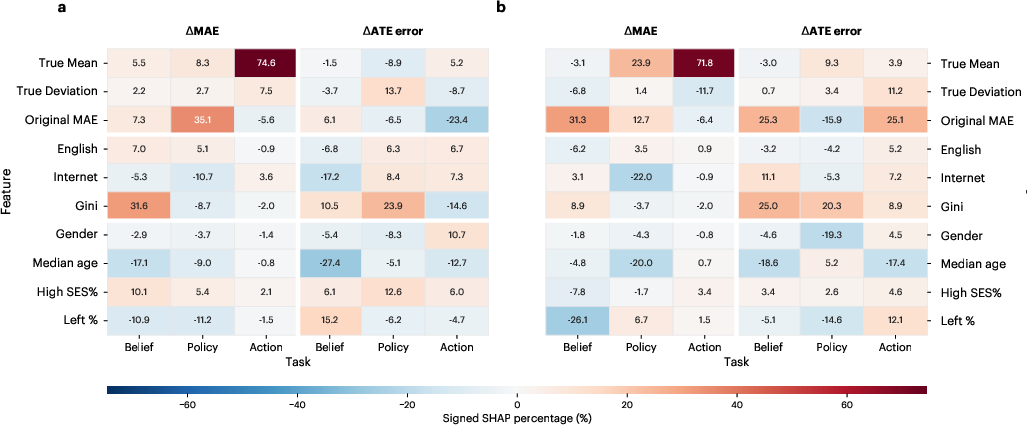
Figure 6: SHAP feature importance profiles illustrating statistical vs. socioeconomic drivers for descriptive and causal error.
Practical and Theoretical Implications
These findings underscore the necessity for independent causal evaluation in LLM behavioral simulation, invalidating the current practice of relying on descriptive fit as proxy for intervention forecasting. The results also elucidate the mechanism by which LLMs, via their training corpus and next-token prediction objective, encode an unrealistically strong attitude-behavior coupling, especially when textual representations favor narratively coherent and inline behavioral outcomes. Certain intervention logics (imagination/simulation-based vs. direct reasoning) are more prone to causal bias due to their mode of representation in natural language corpora.
For fairness analysis, descriptive evaluations are inadequate: they do not flag population-level causal disparities, failing to identify demographic or cross-national risk profiles. As LLMs proliferate in multi-agent simulations and policy modeling, the descriptive-causal divergence compounds along causal chains, risking erroneous inference in downstream applications.
Future Directions
Future research should extend this analysis to additional behavioral domains, larger or fine-tuned models, and recovery of heterogeneous or dynamic causal effects. The study recommends designing benchmarks explicitly targeting causal fidelity and outcome heterogeneity, rather than relying on descriptive validation.
Conclusion
Behavioral simulation via LLMs demonstrates a systematic divergence between descriptive fit and causal fidelity. The former neither guarantees nor closely predicts the latter, with structural inequalities and outcome domain-specific failures. The results challenge prevailing assumptions about LLMs as reliable substitutes for human respondents in intervention forecasting. Explicit causal evaluation, careful population-level benchmarking, and domain-sensitive prompting are required to avoid misleading social-science or policy conclusions, especially as LLMs see increased deployment in agent-based modeling and synthetic behavioral research.

