- The paper introduces a novel explicit mapping from spectrogram bins to learnable 3D Audio Gaussians for accurate binaural synthesis.
- It employs dual spherical harmonic modulation and phase correction to model magnitude and interaural time differences.
- Experimental results show over 14% reduction in magnitude error and a 25% improvement in perceptual quality compared to visual-dependent baselines.
Explicit Sound Field Modeling for Novel-View Binaural Synthesis: The AudioGS Framework
Introduction
AudioGS proposes an explicit, visual-free methodology for reconstructing 3D sound fields capable of high-fidelity binaural synthesis at arbitrary listener poses. Unlike existing systems that depend on visual inputs or implicit representations, AudioGS directly parameterizes the sound field as a set of learnable 3D Audio Gaussians, each corresponding to a specific spectrogram bin. This explicit mapping enables interpretable, geometry-aware control of both magnitude and phase properties in spatial audio.
Methodological Innovations
AudioGS adapts the Gaussian Splatting paradigm—originally successful in visual radiance field synthesis—to spatial audio. Each time-frequency bin from the input spectrogram is linked to an Audio Gaussian with learnable 3D coordinates, dual spherical harmonic (SH) coefficients, and an adaptive decay parameter. The Audio Gaussians act as isotropic acoustic radiators with directionality modeled through SHs, as depicted below.
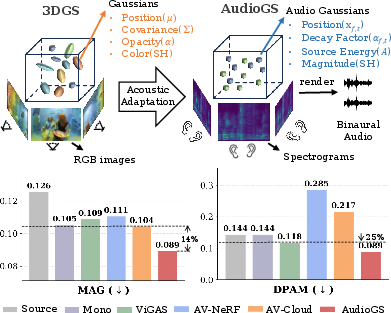
Figure 1: The AudioGS pipeline and performance benchmarks versus implicit and visual-dependent baselines.
The explicit rendering process consists of two stages:
- Magnitude Modulation: SH basis functions encode directionally dependent magnitude, while a physics-driven decay term models distance attenuation from source to listener. This design allows for accurate interpolation of energy distribution, interpolating spatial cues even with sparse input observations.
- Phase Correction: To achieve correct binaural cues, AudioGS computes interaural time differences (ITD) by modeling wave propagation delays as a function of the geometric relationship between each Gaussian and the listener's pose. This corrects for the common deficiency of prior works, which either ignore or inaccurately transfer phase information between viewpoints.
The binaural spectrogram is synthesized by combining modulated magnitudes and corrected phases for each ear, then transformed to the time domain via inverse STFT for waveform reconstruction.
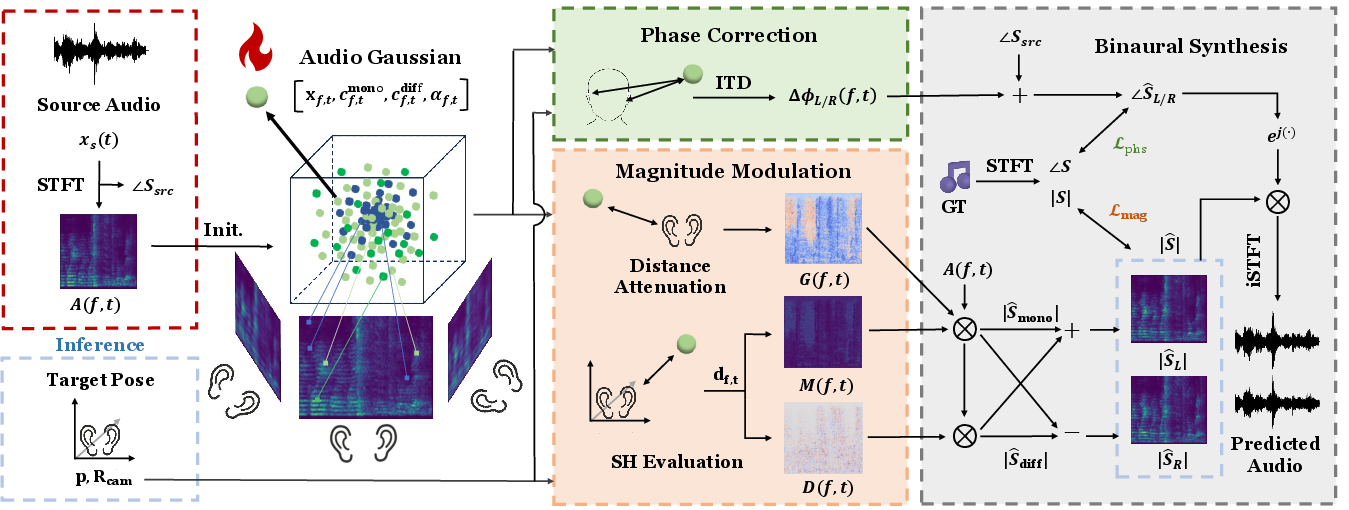
Figure 2: Detailed depiction of the AudioGS architecture, including dual streams for magnitude and phase synthesis.
Experimental Evaluation
The framework is evaluated on the Replay-NVAS dataset, focusing on real-world scenes with up to eight synchronous RGB and binaural audio captures. A challenging scenario is adopted: synthesis for fully held-out listener positions, demanding the interpolation of the sound field from sparse observations. Comparisons are made against five methods, including ViGAS, AV-NeRF, and AV-Cloud, which all utilize visual priors and/or implicit representations.
AudioGS demonstrates robust improvements:
- Magnitude error (MAG): Reduced by over 14% relative to the closest visual-dependent model.
- Perceptual metric (DPAM): Improved by approximately 25%, establishing superior subjective realism.
- Spatial accuracy (LRE/ENV): Either outperforms or remains competitive with all baselines.
Crucially, these results are obtained without using any visual data, highlighting the efficacy of the explicit acoustic modeling in AudioGS.
Figure 1: AudioGS achieves consistently lower MAG and DPAM than all visual-dependent competitors on the Replay-NVAS dataset.
Qualitative and Subjective Analysis
Waveform analyses reveal AudioGS’s ability to faithfully reproduce transient events and high-frequency details commonly lost in over-smoothed neural approaches. This is evident in time-domain signal envelopes and high-frequency transient regions.
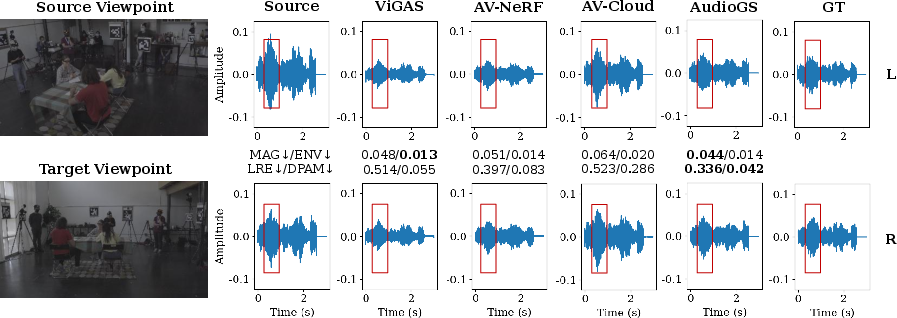
Figure 3: Qualitative comparison of synthesized binaural waveforms; AudioGS preserves fine structure, unlike the smoothed output from ViGAS and AV-NeRF.
A controlled MUSHRA listening test with 12 expert and lay participants further validates these findings, with AudioGS obtaining the highest mean Basic Audio Quality rating consistently across representative novel-view cases.
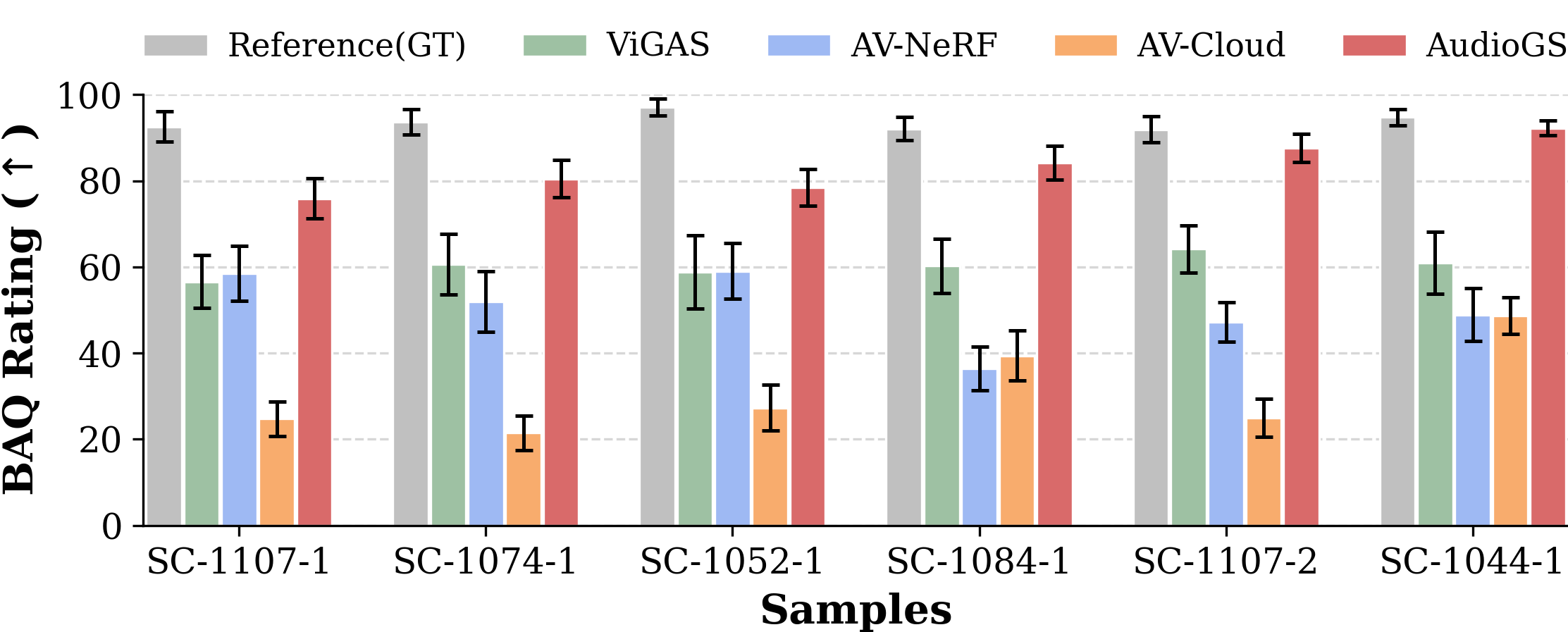
Figure 4: Subjective MUSHRA ratings for six challenging test scenes; error bars report SEM.
Finally, the learned spatial distribution of Audio Gaussians reflects the framework's capacity for physically plausible localization: low-magnitude Gaussians cluster near initialization (mapping to silence/noise), while high-energy Gaussians spatially span the scene, capturing the structure of the directional sound field.
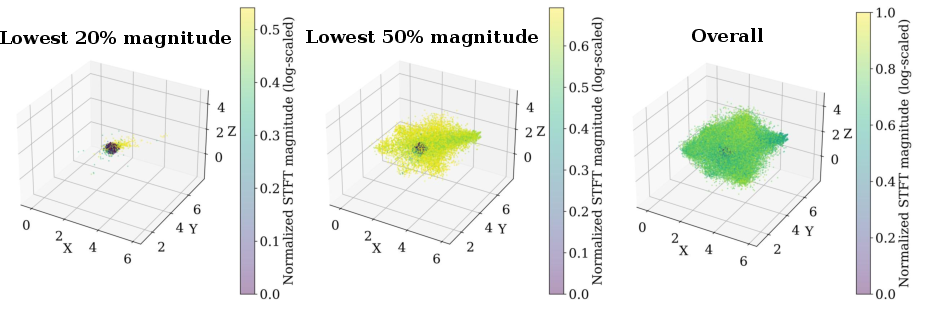
Figure 5: Spatial arrangement of Audio Gaussians; high-energy primitives radiate out, encoding sound field directivity and spread.
Ablation Studies
Component-wise removals demonstrate the necessity of each explicit modeling choice:
- Omitting distance attenuation most harms spatial accuracy.
- Removing SH modulation degrades reconstruction quality.
- Ignoring phase correction misaligns ITDs, reducing spatialization.
This confirms that the framework's design is critical for achieving its observed performance benefits.
Practical and Theoretical Implications
AudioGS removes the dependence on visual priors for novel-view spatial audio synthesis, enabling deployment in scenarios lacking robust camera calibration or textural scenes. The explicit mapping from spectrogram bins to 3D Gaussians renders the system interpretable, facilitates modularity (e.g., for source separation tasks), and bridges the gap toward fully joint audio-visual scene representations. The demonstrated spatial distribution learning suggests promise for extending this model to dynamic, time-evolving sound fields using higher-dimensional splatting techniques.
Conclusion
AudioGS establishes an explicit, interpretable, and visual-free paradigm for dense 3D sound field reconstruction. By directly optimizing Audio Gaussians over spectrogram bins and integrating principled magnitude and phase modeling, it achieves state-of-the-art fidelity and perceptual quality in novel-view binaural synthesis. The implications for immersive audio rendering, AR/VR/XR system robustness, and next-generation neural acoustics are substantial, indicating several routes for future research—particularly via unification with geometric vision models and extension to dynamic scene synthesis.