- The paper introduces a novel transformer-based dual-head attention mechanism that leverages visual cues to generate left/right binaural audio outputs.
- It integrates visual features into an audio U-Net via FiLM conditioning and employs a soft spatial prior, enhancing spatial channel separation.
- Experimental results on FAIR-Play and MUSIC-Stereo demonstrate significantly lower STFT errors and improved SNR performance over previous methods.
Introduction
SIREN addresses the challenge of reconstructing binaural audio from monaural recordings in the context of consumer video, where true binaural capture is generally infeasible. Spatial cues in binaural audio, critical for immersive applications such as VR/AR and gaming, are typically absent due to hardware constraints. Existing mono-to-binaural frameworks fall short in terms of accurate left/right (L/R) channel formation and often rely on hand-crafted spatial heuristics or suboptimal aggregation strategies during inference, resulting in timbral drift and unstable spatialization.
Methodology
SIREN introduces a Vision Transformer (ViT)-based visual encoder leveraging DINOv3, engineered with dual self-attention heads. This design allows for end-to-end learning of shared and channel-specific visual features, eliminating the dependence on fixed L/R output masks. The dual-head self-attention mechanism inherently produces spatially selective feature maps, which serve as soft directional cues for subsequent audio processing.
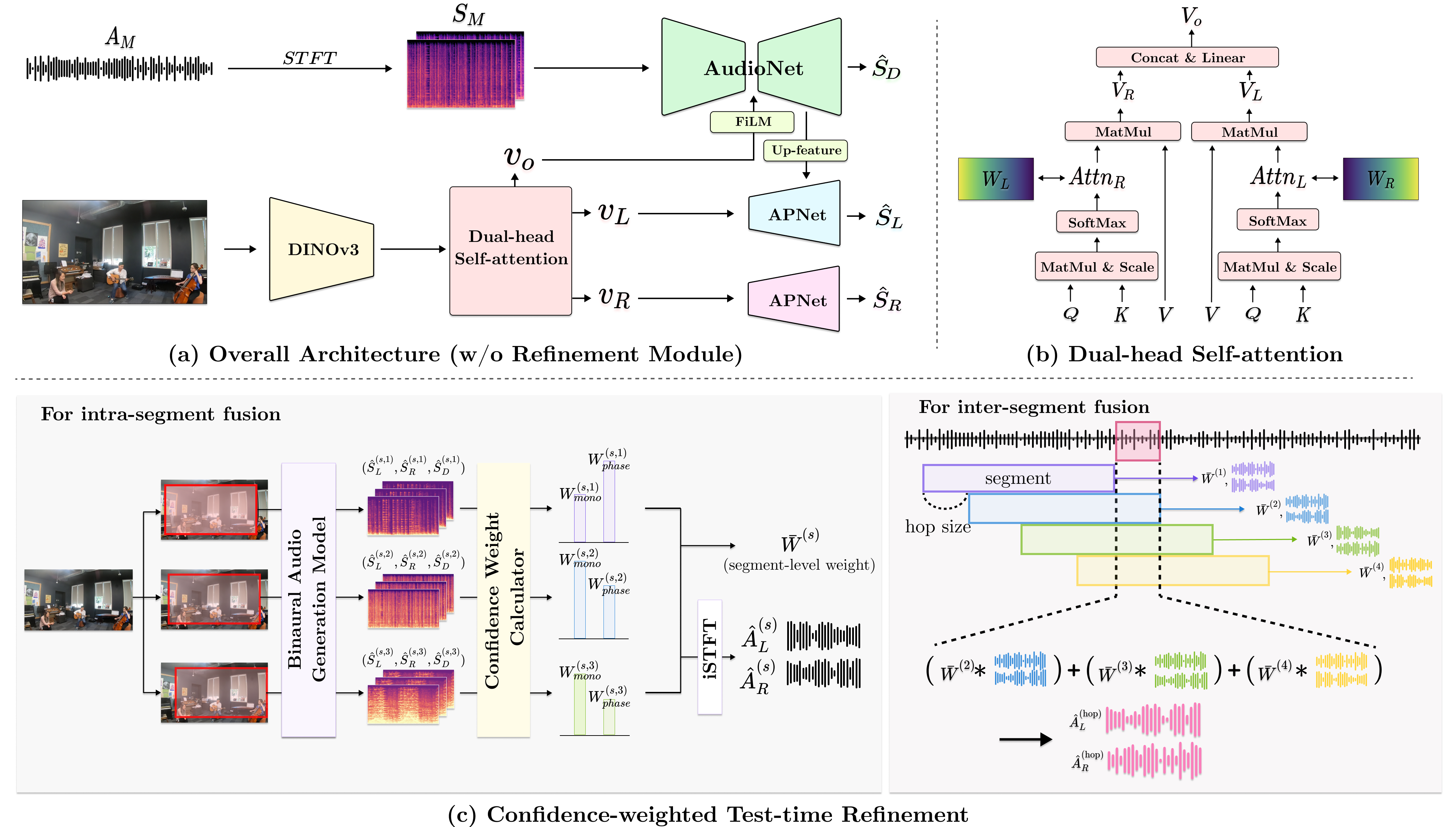
Figure 1: The SIREN pipeline employs ViT-based dual-head attention to produce L/R-selective visual features that FiLM-condition an audio U-Net, yielding direct L/R channel outputs and a difference spectrogram for auxiliary consistency.
FiLM-Conditioned Audio Generation
Visual features are integrated into the audio U-Net via Feature-wise Linear Modulation (FiLM) layers at each decoder stage. The U-Net receives the complex mono STFT, and visual features (both shared and channel-specific) condition the activations, enabling finer alignment between visual context and spectrotemporal audio structures. The decoder yields both direct L/R complex spectrograms and a difference branch to reinforce spatial reconstruction learning.
Soft Spatial Prior
A soft spatial prior is imposed on the attention maps at early training stages, constructed as logistic ramp targets. This prior encourages the model to initially assign left and right selectivity in a spatially coherent manner, easing optimization toward physically plausible solutions. The prior's influence decays to zero over training, allowing the model to ultimately prioritize content-driven signals.
Confidence-Weighted Test-Time Fusion
A major practical barrier in mono-to-binaural systems is leakage and inconsistency when aggregating overlapping and multi-crop predictions across time windows. SIREN resolves this by scoring each candidate output with product-of-experts confidence weights, derived from the physical mono-reconstruction error and interaural phase consistency. The two-stage scheme fuses candidates intra-segment (across visual crops) and then inter-segment (across overlapping temporal windows), using the normalized weights to suppress low-confidence, artifact-prone outputs.
Experimental Evaluation
SIREN is evaluated on FAIR-Play and MUSIC-Stereo. Both are challenging, large-scale, consumer-relevant datasets with time-aligned video and high-fidelity binaural audio. The proposed method is benchmarked against Mono2Binaural, Sep-Stereo, CMC, and CC-Stereo on key metrics: STFT L2, envelope L2, phase L1, and SNR.
On MUSIC-Stereo, SIREN achieves the lowest errors on STFT (0.417), ENV (0.091), and phase (1.006), signifying robust magnitude, envelope, and phase reconstruction. On FAIR-Play, SIREN yields the lowest STFT and highest SNR of evaluated systems. The explicit L/R attention mechanism, combined with principled inference refinement, mitigates crosstalk and timbral artifacts, though a slight phase error gap to CMC is noted, traceable to SIREN's direct L/R architecture and aggregation strategy.
Ablation studies confirm that the dual-head attention mechanism and FiLM conditioning both substantially enhance perceptual quality, and that the soft prior and inference fusion each contribute complementary gains—improving channel separation and reducing aggregation-induced distortion.
Implications
SIREN demonstrates that transformer-native attention heads, in conjunction with confidence-based test-time refinement, can scale mono-to-binaural reconstruction beyond handcrafted heuristics and legacy modality alignment methods. The modular framework, which does not require task-specific annotations, is compatible with diverse front-end vision backbones (DINOv3 ViT) and standard spectrotemporal audio-lifting protocols (U-Net). This design aligns well with future integration into AR/VR, telepresence, and consumer media editing pipelines, where spatial fidelity and robustness against L/R leakage under varying aggregation schemes are paramount.
On the theoretical side, SIREN presents a strong case for end-to-end visual grounding and fusion procedures in cross-modal spatial audio generation, offering a template for further investigation into task-specific visual representations, content-adaptive priors, or learned inference-time ensembling regimes. Its reliance on physically-grounded, yet data-driven, fusion metrics suggests broader applicability to other spatialized audio generation tasks, including ambisonic synthesis or environmental auralization conditioned on video.
Conclusion
SIREN delivers a modular, vision-driven framework for mono-to-binaural audio generation with explicit left/right channel prediction, transformer-native spatial attention, and a physically-motivated, confidence-weighted inference regime. Strong empirical results demonstrate its ability to synthesize spatially coherent binaural audio, outperforming or matching prior systems on both time–frequency and perceptual metrics. The approach offers a principled foundation for future research and deployment in audio-visual scene understanding and immersive media synthesis.