- The paper introduces a novel multi-scale attention mechanism that hierarchically factors computations to capture both local and global dependencies.
- It employs kernel theory and symmetric-antisymmetric score decomposition to provide explicit error bounds and improved representational capacity.
- Empirical results demonstrate HKT’s superior accuracy gains across tasks with minimal computational overhead compared to standard attention.
Introduction
The "Hierarchical Kernel Transformer" (HKT) introduces a multi-scale attention architecture designed to extend the representational power of standard self-attention by embedding explicit hierarchical structure across multiple resolutions. The motivation is to overcome the scale-blind limitation of conventional Transformers, where all pairwise token relationships are treated identically, often leading to suboptimal performance and quadratic complexity on tasks requiring both short-range and long-range dependencies. HKT achieves efficient multi-level modeling with strictly bounded computational overhead, while providing new theoretical insight into the structure and approximation properties of hierarchical attention mechanisms.
Model Architecture and Theoretical Contributions
HKT hierarchically factors attention computation by operating the input sequence through a stack of learnable, causal downsampling modules. At each level, attention scores are computed independently among compressed representations and subsequently fused via learned convex weights. This configuration allows distinct levels to specialize in capturing frequency bands in the input, reflecting both local correlations and global dependencies.
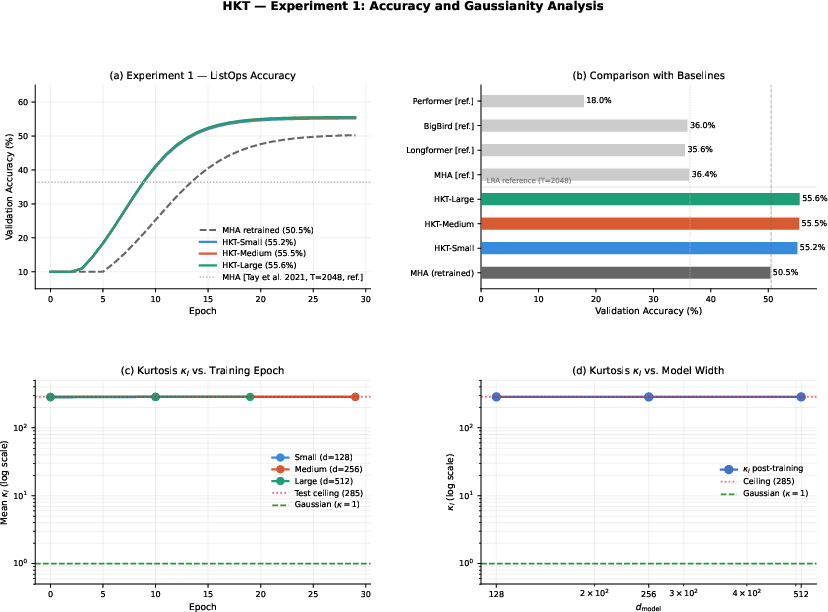
Figure 1: Experiment 1 (top) and kurtosis analysis (bottom). Top left: validation accuracy vs.\ epoch. Top right: comparison with the same-setting MHA baseline and contextual LRA figures.
At the core, HKT provides four main theoretical advances:
- Kernel Property: The hierarchical scoring function is shown to define a sum of positive semidefinite (PSD) kernels under an explicit symmetry condition, generalizing kernel approaches to multi-scale settings.
- Symmetric-Antisymmetric Score Decomposition: The operational score matrix at each level decomposes uniquely into symmetric (reciprocal) and antisymmetric (directional) components, directly analyzing non-symmetrized (asymmetric) attention used in practice.
- Approximation Error Analysis: The approximation error admits a three-term decomposition: a hierarchical kernel error with explicit non-Gaussian correction, a downsampling quantization error, and finite-sample optimization error, with geometric decay in the hierarchical error as levels increase.
- Expressivity: HKT strictly subsumes single-head attention and causal convolutions (for suitable choices of parameters), demonstrating that the hierarchical synthesis provides strictly greater representational capacity in the limit.
The summation mechanism, coupled with hybrid convolution/attention heads and input-dependent fusion, results in strictly bounded complexity growth: the overall computational cost is at most $4/3$ (e.g., 1.3125× for 3 levels) that of standard multi-head attention (MHA), independent of the number of hierarchy levels.
The HKT error analysis employs RKHS theory and information-theoretic bounds. Critically, the information reduction at each level is bounded by terms involving both the linear correlation of the score and output and the non-Gaussianity (as measured by Mardia’s kurtosis statistic) of the score distribution. Experimental evidence shows that the kurtosis in practical models significantly exceeds the Gaussian regime, making the non-Gaussian correction the dominant factor in the information bound.
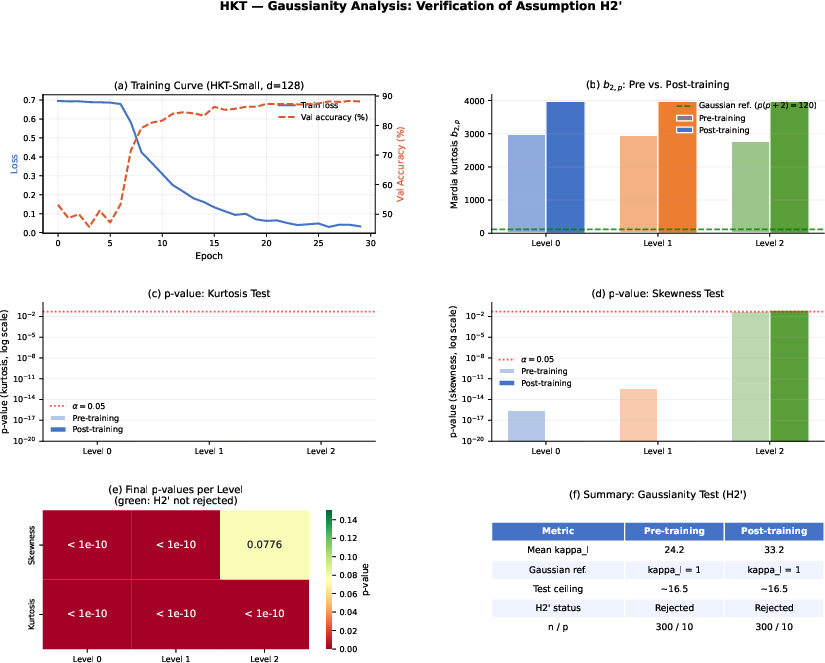
Figure 2: Evolution of Mardia’s kurtosis during training (d=128, 30 epochs), showing strong deviation from Gaussianity in practical models.
Theoretically, the hierarchical kernel admits a Gram matrix decomposition as a non-negative sum of per-level PSD matrices, leading to a rank bound dependent on the sum of projection dimensions per level. Moreover, a unique decomposition of each level’s score matrix into symmetric (reciprocal attention magnitude) and antisymmetric (directional asymmetry) parts reveals that HKT allocates more directional capacity to higher (global) levels, facilitating scalable long-range modeling.
Empirical Results
Extensive experiments demonstrate that HKT consistently surpasses retrained MHA baselines, with the following strong results:
- ListOps (synthetic, T=512): HKT achieves +4.77pp higher accuracy (55.10±0.29% vs 50.33±0.12%) with a 1.31× cost.
- Sequential CIFAR-10 (T=1,024): HKT yields +1.44pp improvement (35.45±0.09% vs 1.3125×0).
- IMDB Character-level Sentiment (1.3125×1): HKT achieves a 1.3125×2pp gain (1.3125×3 vs 1.3125×4).
- Gains are robust to the choice of hierarchical depth and stride and largely attributed to the hierarchical architecture, as ablation studies show that parameter count has minor influence compared to hierarchical structure.
Ablation experiments confirm the dominance of hierarchy in the observed accuracy improvements. Notably, transitioning from hierarchical to flat attention reduces accuracy more than removal of the convolution or dynamic fusion branches.
Empirical analysis of the learned score matrices demonstrates a monotonic reduction in the ratio of symmetric to antisymmetric energy with increasing scale, consistent with the theory that long-range attention should be more directional (asymmetric).
HKT’s computational and memory overhead closely tracks theoretical predictions, remaining practically efficient even at long sequence lengths.
Theoretical Implications and Structural Insights
HKT’s multi-scale architecture provides an explicit mechanism to encode inductive bias for hierarchical dependencies, which flat attention configurations cannot efficiently express. The kernel-theoretic analysis distinguishes contributions across scales and establishes unique representational structure at each level. The symmetric-antisymmetric decomposition provides operational interpretability of attention patterns, with the antisymmetric (directional) component growing in importance at larger spatial scales.
The information-theoretic approximation error bounds, which rigorously account for non-Gaussianity in real models, highlight the criticality of matching theory with empirical score distributions; classical Gaussian process limits are not accurate at moderate width, which the experiments confirm.
Practical Implications and Future Directions
Practically, HKT offers a scalable, more expressive alternative to standard attention for long-sequence modeling and tasks where both localization and global structure matter (e.g., language, vision, sequential decision). Its hierarchical inductive bias, efficient implementation, and empirically validated error bounds suggest its suitability for challenging tasks with hierarchical data dependencies.
Future research will benefit from:
- Full evaluation on large-scale benchmarks (e.g., LRA with 1.3125×5).
- Data-driven calibration of per-level fusion weights based on observed information gain.
- Experimental exploration of high-width, high-depth regimes to empirically investigate the convergence towards Gaussianity and implications for information-theoretic bounds.
The framework directly complements structured state-space models (SSMs) such as Mamba, indicating potential for hybrid architectures combining hierarchical attention and state-space modeling.
Conclusion
HKT demonstrates that the single-scale design of standard attention is an architectural constraint rather than a theoretical necessity. Explicit multi-scale attention via hierarchical kernels introduces measurable, theoretically interpretable improvements with strictly bounded complexity. The combination of kernel theory, symmetric-antisymmetric decomposition, and non-Gaussianity-aware approximation establishes HKT as a principled, efficient alternative for sequence modeling tasks that require both local and global structure. Empirical results, supported by comprehensive analysis, indicate that multi-scale attention mechanisms such as HKT will play a foundational role in the future evolution of deep sequence models.
Reference: "Hierarchical Kernel Transformer: Multi-Scale Attention with an Information-Theoretic Approximation Analysis" (2604.08829).