- The paper introduces the Explanation Stability Score (ESS) that quantifies the consistency of post-hoc attributions under label-preserving perturbations.
- It applies the ESS metric to transformer models like BERT, RoBERTa, and DistilBERT on sentiment datasets, revealing differences in rationale stability and class-wise discrepancies.
- The results highlight that controlled paraphrasing significantly lowers ESS, exposing attribution instability that traditional fidelity metrics do not capture.
Empirical Assessment of Rationale Stability via Explanation Consistency for Pattern Recognition Models
Introduction
Auditing explanation consistency—especially under label-preserving perturbations—is critical for trustworthy AI deployment. The paper "Empirical Characterization of Rationale Stability Under Controlled Perturbations for Explainable Pattern Recognition" (2604.04456) systematically addresses explanation stability at a population level, introducing the Explanation Stability Score (ESS) as a metric for quantifying the consistency of post-hoc attributions across similar input instances. The core claim is that population-level attribution consistency is under-addressed in current post-hoc XAI literature, preventing systematic discovery of feature bias, reasoning instability, and model misalignment.
The following essay details the formal contributions, experimental findings, and practical implications of the proposed framework, emphasizing technical subtleties in the evaluation pipeline and the behavior of widely adopted Transformer models.
Methodology: Consistency Metric and Evaluation Framework
The proposed methodology defines a pipeline for assessing attributional consistency in transformer-based sequence classifiers. The core metric, ESS, is the average cosine similarity between SHAP value vectors computed for pairs of examples sharing the same label. The rationale is that for trustworthy models, explanations (as measured by SHAP attributions) should be invariant—or at least highly similar—across instances of the same class. This is explicitly measured for datasets containing both original and controlled paraphrased (label-preserving) inputs.
The evaluation employs the following steps:
- Model and Dataset Selection: BERT, RoBERTa, and DistilBERT are fine-tuned on SST-2 and IMDB sentiment datasets.
- Explanation Generation: SHAP KernelExplainer is used for post-hoc token-level attribution.
- Consistency Computation: Pairs of same-label samples are compared via cosine similarity of their attribution vectors.
- Robustness Assessment: Controlled paraphrasing via WordNet synonym replacement tests the stability of attributions against surface-level perturbations.
- Comparison with Fidelity: ESS is orthogonally compared to standard masking-based fidelity metrics.
The methodology establishes a reproducible pipeline for population-level consistency verification.
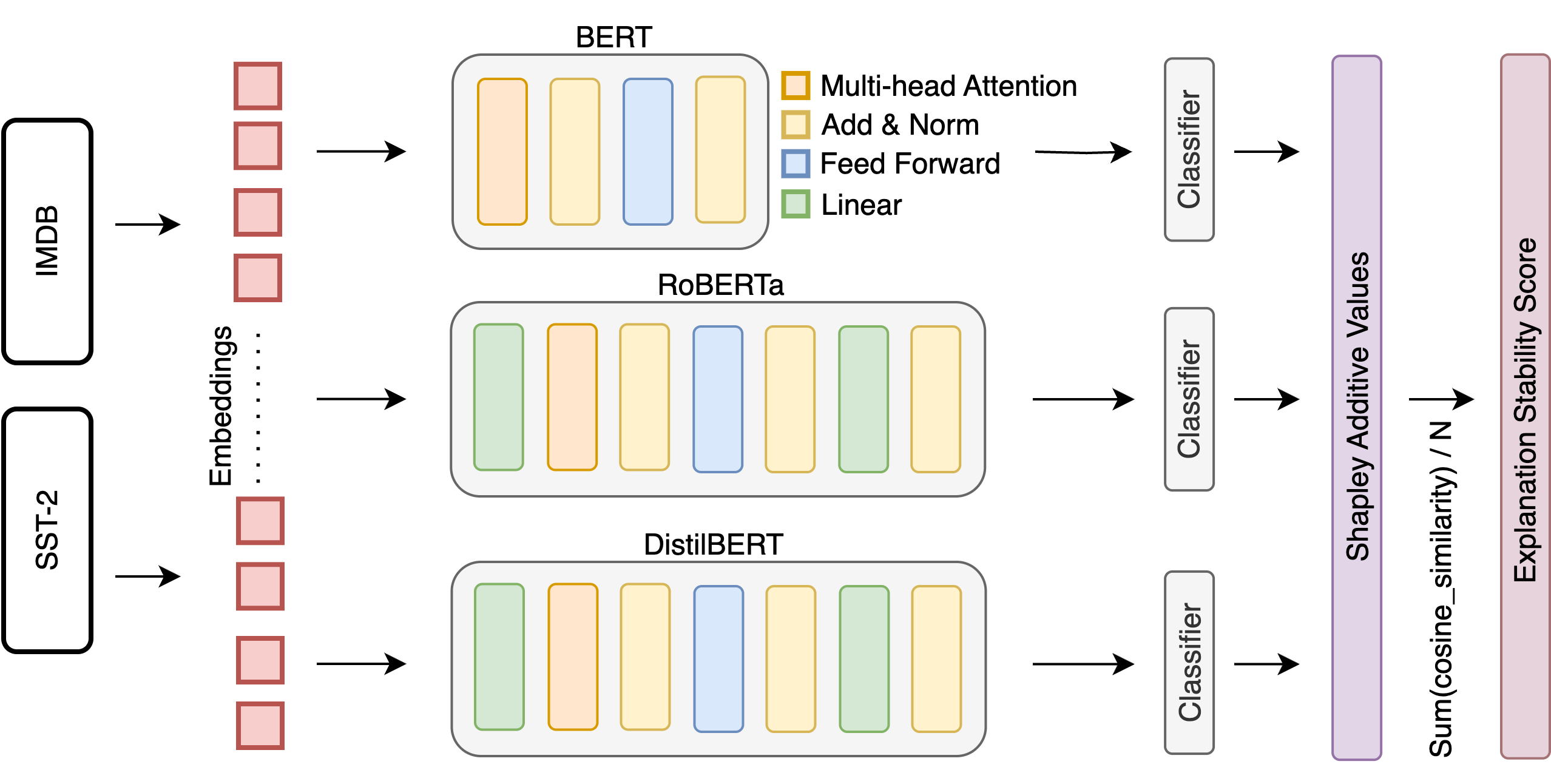
Figure 1: The evaluation pipeline for rationale-stability: input encoding, model inference, SHAP-based post-hoc attribution, and aggregation into the ESS Score.
Experimental Results
Empirical analyses focus on quantifying both the absolute levels of explanation stability and their response to controlled paraphrasing. The key findings are as follows:
- Transformer Variance: RoBERTa yields the highest mean ESS values (e.g., 0.1995 on SST-2 test), indicating the greatest consistency in rationales, followed by BERT (0.1097–0.1797). DistilBERT underperforms significantly, with mean ESS of 0.0053–0.0149.
- Dataset Effects: ESS values are consistently higher on IMDB than SST-2 for BERT and RoBERTa, suggesting that the explanation stability may depend on inherent dataset variation or the nature of the fine-tuning task.
- Perturbation Sensitivity: Across all models, paraphrased input variants consistently reduce mean ESS, with BERT showing a drop of 11–14% and RoBERTa 10–12%. A t-test on BERT/SST-2 test ESS (original 0.1097 vs. paraphrased 0.0945, p=0.021) confirms statistical significance.
- Fidelity Contrasts: Standard "fidelity at k" metrics (confidence drop on masking top SHAP features) do not track ESS values. Notably, RoBERTa's high ESS is not reflected in increased fidelity, suggesting orthogonality between consistency and output faithfulness.
- Class-wise Discrepancies: ESS is higher for negative sentiment classes compared to positive, indicating that model explanations are less reliable for positive predictions.
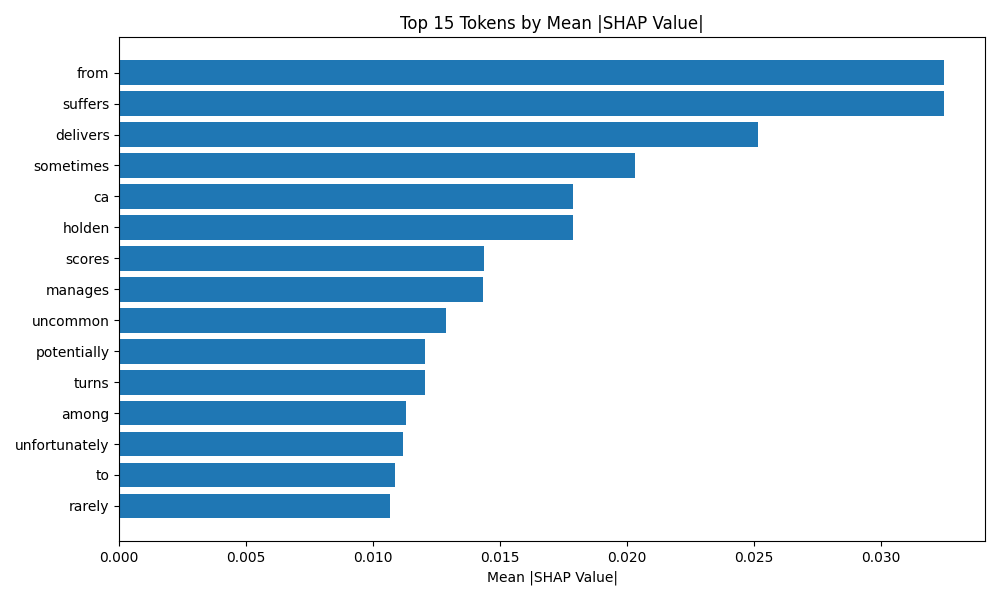
Figure 2: Top SHAP-based feature importances for BERT on SST-2 test split, pinpointing salient tokens driving sentiment classification.
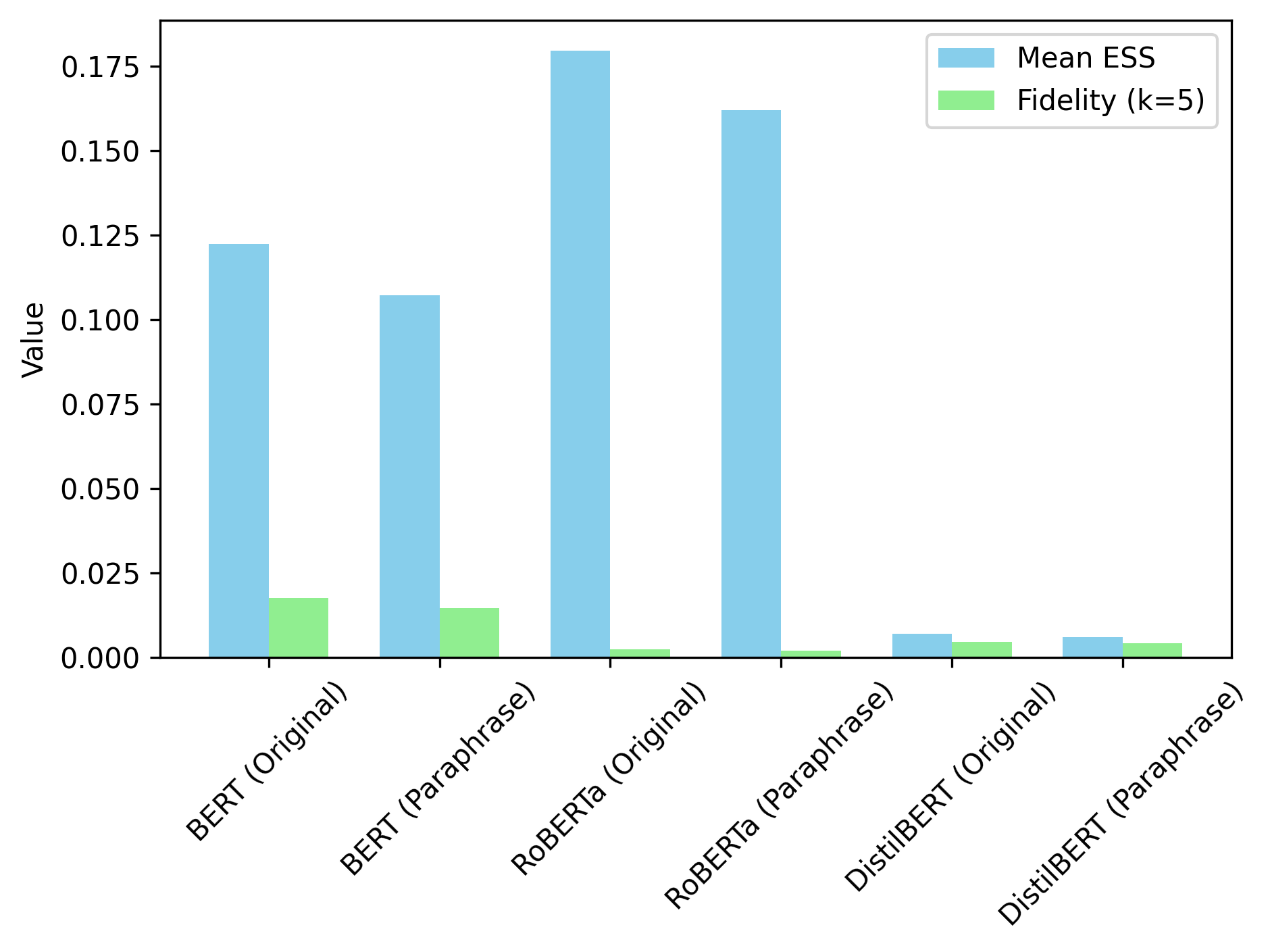
Figure 3: Bar chart of mean ESS and fidelity across models (BERT, RoBERTa, DistilBERT) and conditions (original, paraphrased), illustrating attribution stability variations.
Analysis and Implications
The empirical analysis exposes several structural weaknesses in current XAI workflows:
- Metric Orthogonality: ESS does not correlate with output fidelity, implying it captures complementary facets of explanation "quality." This means that faithfulness to the model output does not guarantee consistency across a label manifold, exposing a vulnerability in current evaluation paradigms.
- Model Complexity Effects: Compact models like DistilBERT show both low ESS and low variance, likely due to reduced attributional richness and lower feature dependency. This may appear to improve interpretability, but risks producing trivial rationales.
- Paraphrase Robustness: The statistically significant drop in ESS after paraphrasing underlines the instability of current explanations with respect to superficial lexical variation, a critical flaw for high-stakes domains where input variability is unavoidable.
- Human Interpretability Alignment: Stable, population-level explanations are a prerequisite for human trust. Inconsistent attributions across similar scenarios degrade explanation validity, contradicting interpretability requirements in regulated environments.
The ESS metric addresses a longstanding gap in practical XAI by enabling systematic audits of explanation stability at the class level, potentially surfacing feature biases, spurious correlations, or non-robust reasoning that might escape instance-level inspection.
Future Directions
The paper suggests several avenues for further work:
- Metric Integration in Training: Direct incorporation of ESS (or related population-level stability losses) into model objectives could lead to more robust, inherently interpretable models.
- Extension Beyond SHAP: While SHAP is used throughout, alternative attribution techniques—especially those with different inductive biases—could be analyzed under the ESS framework.
- Broader Benchmarking: Application to multimodal pattern recognition, out-of-domain generalization, or debiased training datasets would reveal the boundary conditions for population-level rationale stability.
- Explainer Robustness: As ESS is partly a function of explainer properties, enhancing explainer robustness or combining attributions from multiple methods may improve measurement quality.
Conclusion
This paper presents a rigorous, systematic methodology for quantifying the stability of post-hoc explanations across controlled input perturbations. By introducing the Explanation Stability Score and benchmarking widely-used transformer models across two sentiment analysis tasks, it empirically demonstrates that attribution stability is neither guaranteed by model architecture nor by conventional fidelity metrics. Consistency-aware explanation auditing, as enabled by the ESS framework, is a vital step toward trustworthy, human-aligned AI, especially under realistic input variation. Future developments may leverage population-level consistency regularization to enforce robust, stable rationales during training, broadening the operational reliability of XAI toolchains.