- The paper introduces OVS-DINO, which fuses SAM’s structural cues with DINO’s semantic features using a structure-aware encoder and preservation gate.
- The method significantly enhances boundary precision and fine-grained segmentation, achieving an average mIoU increase of 2.1% across eight benchmarks.
- It eliminates the need for heavy SAM inference by transferring learned structure, offering efficient zero-shot segmentation in complex, multi-object scenes.
OVS-DINO: Structure-Aligned SAM-DINO for Open-Vocabulary Segmentation
Introduction
This work introduces OVS-DINO, an architecture for Open-Vocabulary Segmentation (OVS) that fuses structure-rich inductive priors from Segment Anything Model (SAM) into the semantic feature space of DINO, with text guidance via CLIP. OVS aims to expand segmentation from closed, labeled datasets to more general categories, leveraging vision-language alignment. While CLIP provides strong text-visual correspondence, its global alignment and lack of pixel-level supervision limit fine-grained segmentation. Contemporary models such as DINO offer spatially expressive features but suffer progressive spatial detail attenuation due to high-level abstraction in deep ViT layers. OVS-DINO bridges this gap, proposing structure-to-semantic space alignment and decoding strategies to explicitly enhance boundary precision and fine-grained region discrimination in dense prediction tasks.
Spectral and Representational Analysis: DINO and SAM
The paper presents a spectral analysis of DINO's internal representations. Frequency-domain decomposition reveals that deep DINO layers suppress high-frequency components, leading to the loss of edge sensitivity as features transition from low-level to high-level abstraction. This is evidenced by a monotonically decreasing high-to-low frequency energy ratio and azimuthally averaged power spectrum decay in deeper layers, demonstrating that fine structural details are primarily encoded in shallow DINO layers, while semantic abstraction dominates in deeper layers.
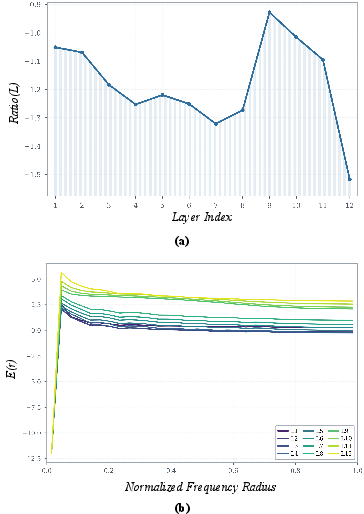
Figure 1: Progressive attenuation of high-frequency (detail, edge) content in DINO layers, motivating the need for structural re-activation.
PCA visualizations further confirm DINO's early-layer contour-awareness, suggesting that structural sensitivity is present but not utilized in final outputs.
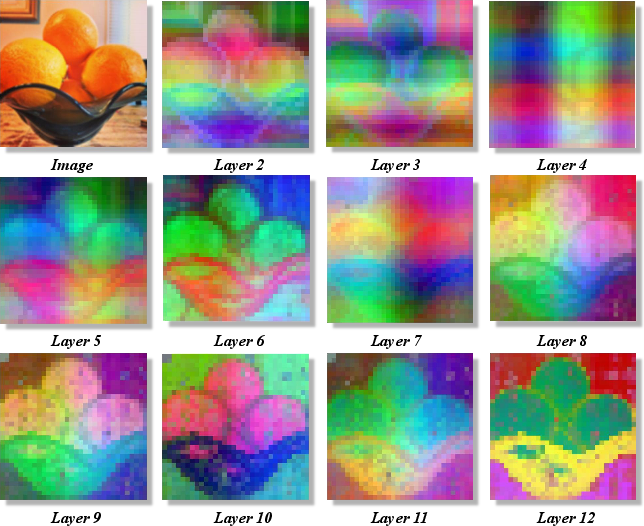
Figure 2: Early DINO layers exhibit clear object contour extraction, indicating latent boundary-awareness capability.
By contrast, SAM is fully supervised for instance segmentation and encodes explicit edge and contour information. CKA (Centered Kernel Alignment) similarity heatmaps between DINO and SAM on the COCO dataset quantify the substantial representational discrepancy between the two, particularly in deeper layers, justifying the need for non-trivial alignment rather than naive feature fusion.
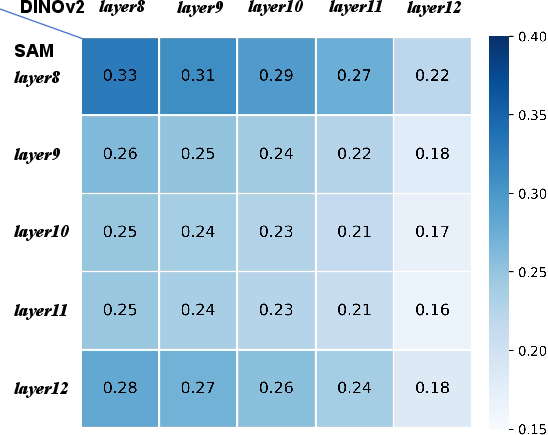
Figure 3: CKA analysis highlighting the representational gap between DINO and SAM, necessitating dedicated alignment modules.
Architecture: Structure-Aware Encoding and Semantic Preservation
The proposed pipeline aligns multi-level DINO features with SAM structural features using a dedicated Structure-Aware Encoder (SAE). This module aggregates and refines shallow and intermediate DINO outputs (layers 2,4,6,8,10,12), projecting them into a common latent space. A structure-modulated decoder (SMD) projects these features back into DINO's original space, incorporating learned structural cues without degrading text-visual semantic alignment, ensured via the Preservation Gate (PG). This decoupled design prevents catastrophic semantic drift while selectively injecting boundary information.
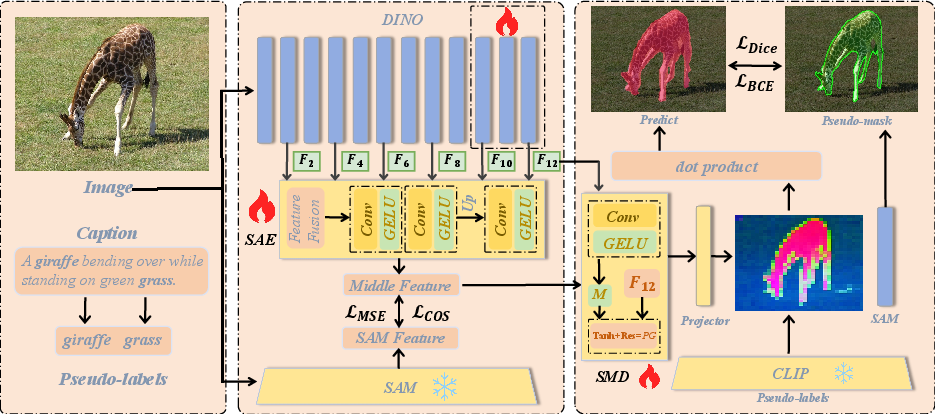
Figure 4: The OVS-DINO architecture: SAE projects DINO multi-level features to the SAM structural space, with SMD mapping back and a PG safeguarding semantic alignment for downstream text-guided segmentation.
Training objectives combine semantic and structural cosine/MSE alignment losses, with segmentation loss supervised by SAM-generated pseudo-masks. At inference, the architecture leverages the refined DINO features, removing the need for computationally heavy SAM, increasing deployment efficiency.
Empirical Results
State-of-the-art mIoU is achieved on eight OVS benchmarks, with an average performance gain of 2.1% (from 44.8% to 46.9%), and strong improvements on challenging, cluttered benchmarks like Cityscapes (+6.3%) and COCO-Stuff (+6.1%). The model is especially robust in dense, multi-object scenes, addressing previous limitations in boundary delineation and region specificity.
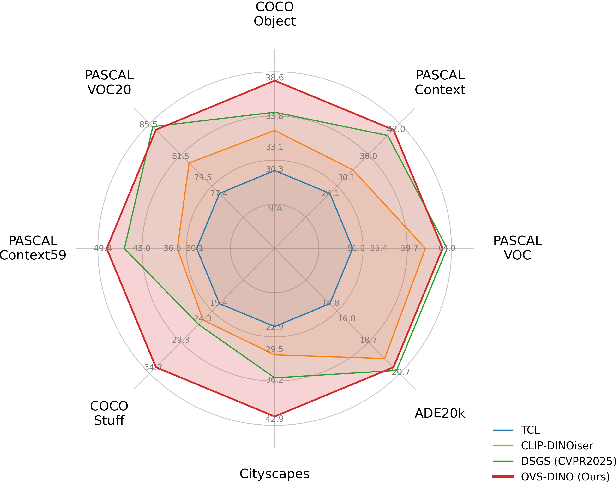
Figure 5: OVS-DINO delivers substantial improvement over prior weakly-supervised OVS methods, especially in complex real-world datasets with high object density.
Qualitative results indicate clear advances in mask contiguity and coherence, as well as reduction of over-segmentation and confusion in adjacent or semantically similar regions.

Figure 6: Visual comparison of segmentation masks, with OVS-DINO producing substantially cleaner boundaries and better correspondence to ground truth.
Ablation and Analysis
Ablation studies underscore the critical role of structural alignment with SAM and the PG, both in terms of numerical performance and qualitative outputs. Removal of SAM alignment leads to marked performance degradation on all tested datasets, particularly in complex scenes. Omission of the PG (semantic preservation mechanism) results in pronounced inconsistency, confirming that boundary enhancement must be mediated rather than directly injected to avoid semantic drift.
Layerwise analysis reaffirms that dense sampling from early DINO layers is indispensable for capturing high-frequency information; freezing DINO during training or shallow feature aggregation substantially reduces segmentation quality.
Additional experiments demonstrate that once trained, the system does not require SAM at inference – the knowledge transfer is effective and stable, validating the sample-efficient, practical advantage of the method.
Implications and Future Work
OVS-DINO demonstrates that structured injection of contour information into self-supervised visual models can remediate the loss of spatial precision typical in open-vocabulary dense prediction. By integrating strong boundary priors without semantic drift, substantial advances in zero-shot segmentation generalization and robustness in challenging, real-world scenes are realized. The SAM-to-DINO transfer mechanism is modular and may extend to other VLMs, suggesting future research directions in leveraging supervised or domain-specific priors for improved vision-language alignment, multi-scale representation, and fine-grained region discrimination, especially in resource- or annotation-scarce domains.
Conclusion
OVS-DINO presents a principled method for enhancing boundary and contour awareness in open-vocabulary segmentation, combining the semantic strengths of DINO with the spatial fidelity of SAM through structured architectural and loss design. The approach achieves top-tier performance across benchmarks, efficiently distills structure-awareness during training, and maintains text-visual alignment at inference. The broader implication is that modular structure-semantics fusion offers a pathway for scalable, fine-grained, and practical OVS in open-set environments (2604.08461).