- The paper introduces a decouple-and-rectify framework that partitions CLIP features into semantic and structure-dominated subspaces.
- It employs a prior-driven graph rectification and uncertainty-guided fusion to enhance boundary sharpness and overall segmentation accuracy.
- Empirical evaluations show significant gains in mIoU and mACC across eight remote sensing benchmarks compared to traditional methods.
Semantics-Preserving Structural Enhancement for Open-Vocabulary Remote Sensing Segmentation: An Expert Synthesis of DR-Seg
Introduction and Motivation
Open-vocabulary segmentation in remote sensing (RS) demands pixel-level categorization across both seen and unseen classes, necessitating robust semantic alignment and spatially precise structural delineation. Leading approaches use vision-LLMs (VLMs) like CLIP, but CLIP’s inherent global semantic alignment and weak spatial priors limit its applicability to RS, where objects are densely packed and spatial precision is critical. Simple fusion of CLIP with structural encoders such as DINO has been shown to degrade semantic integrity, as prior works inject structural cues non-selectively across the feature space, disregarding internal heterogeneity in CLIP representations.
DR-Seg introduces a decouple-and-rectify paradigm explicitly designed for open-vocabulary RS segmentation. This framework first decouples CLIP features into semantics- and structure-dominated subspaces, then applies prior-driven structural rectification only to the latter, followed by an adaptive fusion of the linguistically robust original and the structurally enhanced refined branches. This approach directly addresses integration failures in previous paradigms by exploiting channel-wise functional heterogeneity.
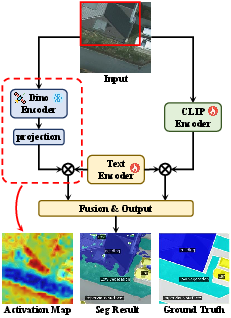
Figure 1: Qualitative comparison of existing (a) and the proposed DR-Seg (b) fusion paradigms, highlighting the benefits of selective subspace-targeted rectification for boundary sharpness and semantic preservation.
Method: Decoupling and Selective Structural Rectification
Channel-wise Functional Heterogeneity in CLIP
Empirical analysis on the Potsdam dataset demonstrates that CLIP’s feature channels are functionally heterogeneous. Channel-wise ablation reveals that masking “positive” channels (with high semantic selectivity) severely impacts mIoU, while others ("negative") are relatively redundant or even detrimental. Activation map visualizations show that retaining only the most semantically critical channels preserves discriminative potential, while discarding the least essential ones sharpens spatial responses, indicating that they are more structurally oriented.
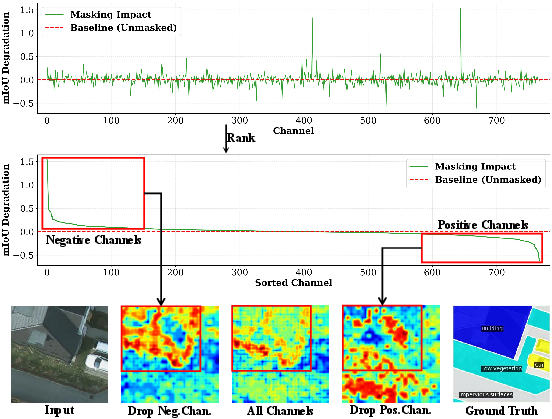
Figure 2: Channel impact analysis shows that only a subset of CLIP channels is vital for semantic discrimination, underpinning the need for explicit feature subspace partitioning.
Semantics-Preserving Subspace Decoupling (SPSD)
A central innovation is SPSD, where CLIP channels are ranked and partitioned into semantics-dominated and structure-dominated subspaces. Semantic importance is quantified per channel using a composite criterion: prototype-level class selectivity (low entropy across category activations) and inter-class discriminability (low mean activation similarity for different classes). A tunable semantic ratio ρ selects the top-ρC channels for the semantic subspace, passing the remainder to the structure pathway.
Prior-Driven Graph Rectification (PDGR)
PDGR constructs a sparse affinity graph over the structure-dominated subspace, with edge weights determined by RS-DINO feature similarity and spatial proximity. A learnable GCN propagates DINO-guided corrections across the graph, selectively enhancing structural fidelity where needed, while preserving the untouched semantics-dominated subspace. Ablations show that both SPSD and PDGR are individually beneficial, and their combination is synergistic.
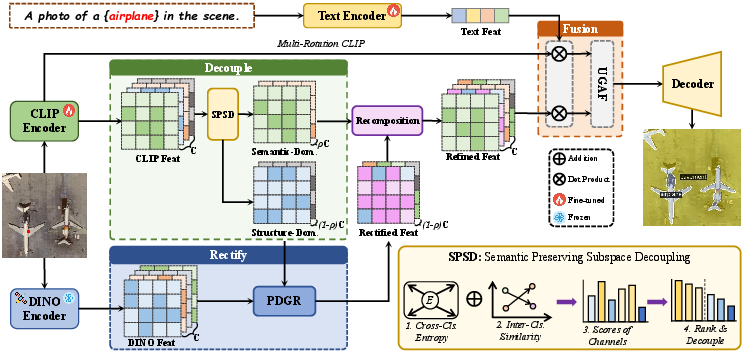
Figure 3: DR-Seg's architecture, illustrating sequential decoupling, DINO-guided graph rectification, and uncertainty-adaptive fusion for final prediction.
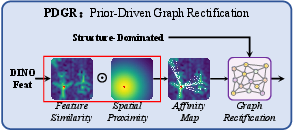
Figure 4: PDGR uses DINO-based affinities to perform targeted rectification in the structure-dominated subspace.
Uncertainty-Guided Adaptive Fusion (UGAF)
The final prediction is produced via pixel-wise adaptive fusion of the original multi-rotation CLIP branch and the refined branch using a normalized entropy-derived uncertainty gate. Regions with low semantic uncertainty retain CLIP predictions, while ambiguous regions are enhanced with the structurally rectified branch. This mechanism provides spatial adaptivity, outperforming mean-based or naive concatenation fusion.
Experimental Validation
State-of-the-Art Results and Generalization
DR-Seg sets a new state-of-the-art across eight RS benchmarks, including DLRSD, iSAID, Potsdam, Vaihingen, LoveDA, UAVid, UDD5, and VDD. With a ViT-L backbone and DLRSD training, it reaches 49.01% m-mIoU and 64.90% m-mACC, surpassing RSKT-Seg by substantial margins. The gains are particularly pronounced for challenging cross-domain benchmarks, as the decoupled representation modulates domain invariance and spatial granularity effectively.
Ablation Analysis
Component-wise ablation demonstrates that each module (SPSD, PDGR, UGAF) provides non-trivial improvements, and their combination yields the strongest results (m-mIoU: +6.18 over baseline). Notably, the performance gap between simple and advanced fusion strategies underscores the necessity of spatially adaptive integration.
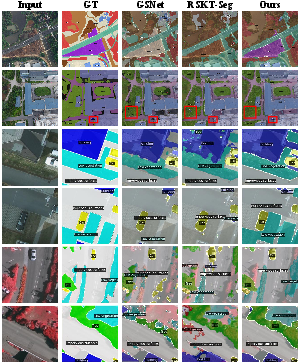
Figure 5: Qualitative segmentation results showing DR-Seg's superior boundary accuracy and recovery of small objects over competitive baselines.
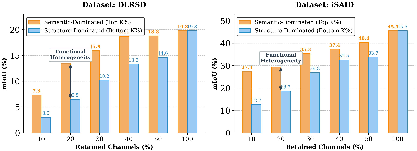
Figure 6: Zero-shot segmentation of top- and bottom-ranked CLIP channels, validating the functional decoupling via semantic selectivity.
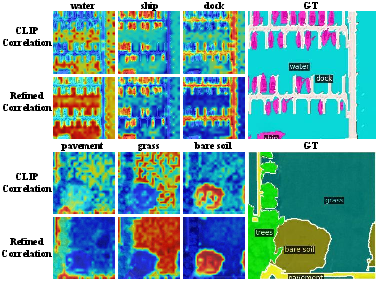
Figure 7: Visualization of class-wise correlation maps; the refined branch exhibits markedly improved localization and contour sharpness.
Robustness to Design Choices
Sensitivity analyses reveal that ρ=0.5 (splitting channels evenly) yields optimal subspace balance, while a graph sparsity parameter k=75 in PDGR best supports spatial structure without over-propagation. Performance persists with either DINOv1 or advanced DINOv3 priors, indicating that DR-Seg's architectural innovations, rather than encoder strength alone, drive the gains.
Implications and Outlook
DR-Seg fundamentally advances the architectural design for open-vocabulary RS segmentation by abandoning holistic feature enhancement in favor of targeted, semantics-preserving structural rectification. The demonstration of channel-wise functional heterogeneity in VLMs suggests future research directions in adaptive subspace modeling and selective adaptation, both for RS and broader dense prediction tasks. The general framework is compatible with stronger or emerging vision-linguistic priors, and its modularity suggests applicability to other dense labeling settings with similar requirements for boundary fidelity and semantic scope.
Conclusion
DR-Seg establishes that semantics-preserving, subspace-targeted structural enhancement via decoupling and uncertainty-guided rectification significantly improves open-vocabulary segmentation in remote sensing. The clear channel-wise functional heterogeneity in CLIP, exploited by targeted DINO-driven correction and adaptive fusion, yields robust advances in spatial precision and domain generalization, setting a new performance benchmark and laying the groundwork for more nuanced cross-modal dense prediction architectures (2604.02010).