- The paper introduces HSA-DINO, leveraging a multi-scale prompt bank and semantic-aware router to efficiently transfer pre-trained open-vocabulary models to domain-specific tasks.
- It utilizes LoRA-based parameter-efficient fine-tuning and dynamic prompt selection to maintain robust performance across both general and specialized domains.
- Experimental results demonstrate significant improvements in harmonic mean mAP and minimal catastrophic forgetting compared to previous state-of-the-art methods.
Parameter-Efficient Semantic Augmentation for Open-Vocabulary Object Detection
Introduction
"Parameter-Efficient Semantic Augmentation for Enhancing Open-Vocabulary Object Detection" (2604.04444) addresses the pronounced performance degradation of open-vocabulary object detection (OVOD) models when adapted from general domains (e.g., COCO) to domain-specialized downstream tasks with limited and fine-grained annotations. The authors propose HSA-DINO, a framework built upon DINO and OV-DINO, that deploys a multi-scale prompt bank (MSPB) and a semantic-aware router (SAR) to efficiently transfer pre-trained OVOD models into new domains without catastrophic loss of open-vocabulary capacity.
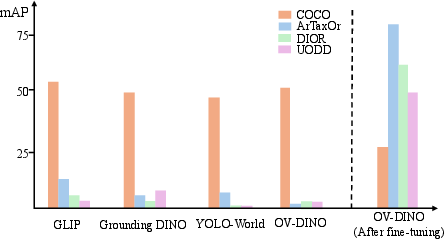
Figure 1: Pre-trained OVOD models perform well on general-domain datasets but lose performance and suffer from catastrophic forgetting when fine-tuned on domain-specific downstream tasks.
Problem Setting and Motivation
Conventional OVOD systems—pre-trained on large-scale image-text corpora—are adept on benchmarks like OV-COCO, but exhibit severe drops in target domain mAP (e.g., ArTaxOr for arthropod species, DIOR for remote sensing, UODD for underwater detection) due to semantic scarcity and misalignment between visual and textual cues inherent to fine-grained domain labels. Existing prompt-based methods fail to bridge this semantic gap, as they rely on static templates or globally-learned prompt vectors that do not leverage the hierarchical and context-rich structure encoded in visual feature pyramids.
The downstream adaptation problem is nontrivial, as naively fine-tuning on target data improves target-domain performance at the cost of open-vocabulary generalization (see Figure 1). The motivation for parameter-efficient semantic augmentation is to learn supplemental semantics that can be dynamically fused into the text encoder, enhancing cross-modal alignment on specialized domains, while safeguarding the foundational open-vocabulary knowledge.
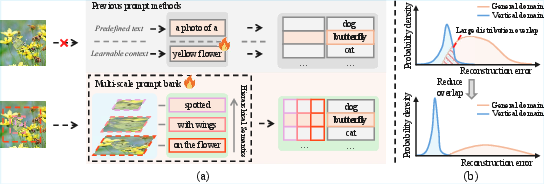
Figure 2: Previous approaches (left) prepend generic prompts or vectors to category labels, while the proposed approach (right) selects auxiliary prompts using a hierarchical feature pyramid and introduces explicit routing across domains with reduced reconstruction error overlap.
The HSA-DINO Framework and Multi-Scale Prompt Bank
HSA-DINO leverages the backbone structure of OV-DINO, incorporating Low-Rank Adaptation (LoRA) into the image encoder to facilitate domain adaptation with minimal parameter update. The central semantic augmentation module—MSPB—extracts multi-scale feature maps from intermediate backbone layers. These are used to index a bank of learnable prompt vectors paired with visual keys, enabling the selection of semantically-relevant prompts for each sample and scale.
For a given image x, multi-scale feature tensors {zs}s=1S are pooled and matched, via cosine similarity, with N learnable keys K, yielding the selection of corresponding prompts to form a concatenated semantic descriptor. This prompt is prepended to each class label and passed to the text encoder, thus enriching textual representation with hierarchical, image-aware semantics. The design allows the text encoder to produce representations that are both contextually grounded and domain-adaptive for category queries.
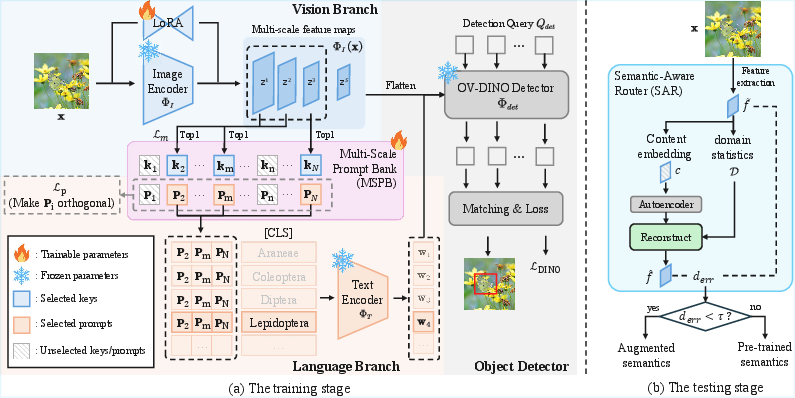
Figure 3: Overview of the HSA-DINO framework—including LoRA-based PEFT, multi-scale prompt bank for semantic augmentation, and a semantic-aware router for adaptive inference-time strategy selection.
Semantic-Aware Routing
To prevent the performance collapse observed when adaptation mechanisms are statically applied, SAR decides at inference-time whether to utilize domain-specific semantic augmentation. Instead of relying solely on domain-specific autoencoder reconstruction errors (as in dynamic routing approaches), SAR decomposes the feature into content and domain statistics and reconstructs the normalized content embedding, thus reducing error overlap between source and target domains. With a task-specific threshold τ, SAR dynamically activates semantic augmentation only for downstream samples, maintaining open-vocabulary generalization across input domains.
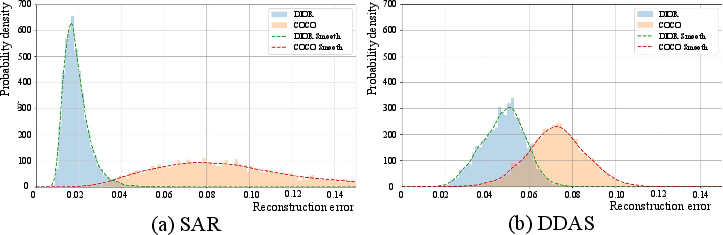
Figure 4: Probability distribution of reconstruction errors across domains, demonstrating that SAR yields reduced overlap and improved discrimination between domain classes compared to prior routing models.
Experimental Validation
HSA-DINO is empirically benchmarked on OV-COCO, ArTaxOr, DIOR, UODD, and the merged benchmark OV-COCO+. Key findings include:
- Superior H (harmonic mean of mAPs): HSA-DINO consistently yields the highest H across downstream domains, outperforming prior SOTA (e.g., H= 60.5 on ArTaxOr, +3.3 over the next best).
- Preservation of open-vocabulary capacity: Unlike other PEFT and FFT baselines, HSA-DINO maintains mAPcoco at near zero-shot levels even after intensive downstream adaptation, indicating minimal forgetting.
- Scalability: On OV-COCO{zs}s=1S0 (joint evaluation across all domains), HSA-DINO achieves 52.3 mAP with ArTaxOr, substantially surpassing all baselines.
- Ablations reveal that removing either the prompt bank or SAR impairs either cross-domain generalization or in-domain adaptability, underscoring the necessity of both modules.
- Prompt heatmap and detection visualizations confirm that MSPB aligns prompts to salient object regions and maintains robust detection capability for both general and domain-specific samples.
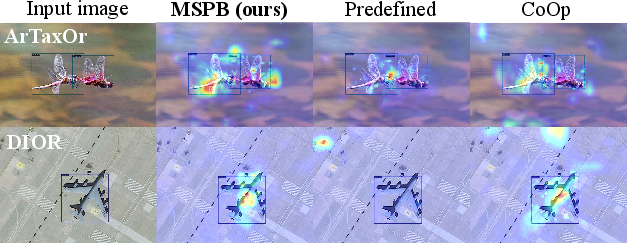
Figure 5: Grad-CAM visualizations confirm that MSPB-attended prompts yield spatially coherent and semantically focused activations.

Figure 6: Visual comparison of detection results: HSA-DINO (bottom row) maintains performance on both general-domain (COCO) and in-domain (ArTaxOr) images after training, compared to baseline OV-DINO.
Theoretical and Practical Implications
This work introduces a methodologically sound and rigorous approach for parameter-efficient transfer and continual learning in OVOD, achieving a high degree of adaptability without memory expansion or full parameter re-training. The MSPB paradigm demonstrates that prompt selection at multiple visual scales (rather than static or single-scale prompts) improves visual-textual grounding and domain alignment. The SAR extends the routing literature by providing content-domain disentanglement and thresholded augmentation, improving the reliability of input domain estimation.
Practically, these advances enable the deployment of robust, generalizable detectors in specialized settings (biological microanalysis, remote sensing, underwater exploration) with minimal risk of catastrophic forgetting. The proposed architecture can be generalized to broader continual learning settings in large-scale vision-LLMs (VLMs).
Future Directions
Several extensions are anticipated: unified or modular SAR for cross-domain or task-agnostic deployment, bank expansion with compositional attribute representation, and integration with stronger backbone architectures and decoders. Furthermore, leveraging MSPB for incremental category expansion and investigating scaling trends with foundation models and LLMs is a promising avenue.
Conclusion
HSA-DINO (2604.04444) establishes a new benchmark for parameter-efficient, robust adaptation of open-vocabulary detectors, combining hierarchical semantic augmentation with dynamic, content-aware routing. The results reaffirm the centrality of multi-scale, grounded prompt engineering and advanced adaptation policies for balancing downstream specificity and general-domain robustness in vision-LLMs.