- The paper introduces negative early exit and adaptive boosting to prune fruitless rollouts, thereby reducing tail latency in MCTS-based LLM inference.
- It combines sequential MCTS’s token efficiency with dynamic parallelism to achieve up to 2.83× lower p99 latency and a 2.44× increase in throughput.
- The system dynamically reallocates compute resources through a Parallelism Degree Control Policy, maintaining accuracy under high-load, production-scale conditions.
Adaptive Parallel Monte Carlo Tree Search for Efficient Test-time Compute Scaling
Introduction and Problem Setting
Test-time compute scaling (TTCS) is increasingly central to enhancing LLM reasoning, enabling dynamic allocation of inference compute to meet task complexity. Among TTCS strategies, Monte Carlo Tree Search (MCTS) remains the most effective for process-reward-model (PRM)-guided reasoning, consistently outperforming parallel candidate expansion approaches due to its principled exploration–exploitation dynamics and capacity for trajectory reevaluation. However, the intrinsic sequential dependency in MCTS yields highly variable, often prohibitive, end-to-end latency—especially problematic for production-scale, latency-sensitive LLM serving. Prior mitigation strategies—early exit based on confidence thresholds and parallel rollout variants—only partially address this long-tail latency, leaving a substantial portion of compute wasted on fruitless searches.
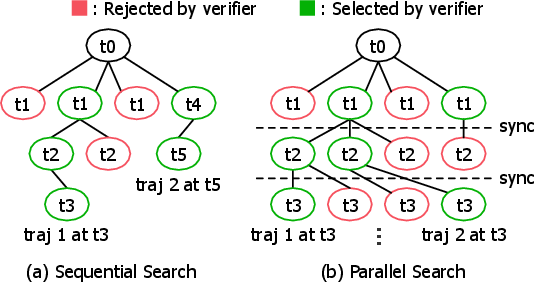
Figure 1: Two representative paradigms for TTCS: (a) sequential search (e.g., MCTS), (b) parallel search (e.g., Beam Search).
This paper presents a system-centric reimagining of MCTS-based TTCS, with new algorithmic constructs—negative early exit and adaptive boosting—that together transform latency and efficiency profiles for practical deployment without sacrificing reasoning accuracy (2604.00510).
Analysis of Sequential vs. Parallel Search Efficiency
The dichotomy between sequential search (MCTS) and parallel search (Beam Search) underpins the methodology. Sequential MCTS judiciously generates candidates by exploiting statistics from prior rollouts, minimizing redundant token generation, while Beam Search mandates simultaneous candidate expansion at every step regardless of intermediate success, leading to computation waste. Empirical analysis validates that, for equivalent or superior accuracy, MCTS generates significantly fewer tokens than Beam Search. The token savings become amplified by positive early exit: when the search terminates upon meeting quality criteria, only sequential search structurally benefits from abandoning large unexplored subtrees, while Beam Search pays unavoidable costs for all candidates per step.
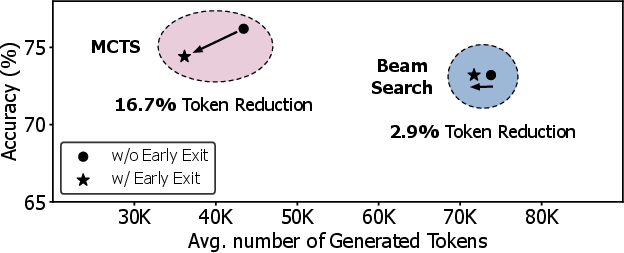
Figure 2: Beam Search incurs higher token costs compared to MCTS; benefits of early exit are more pronounced for MCTS.
Latency and Parallelization Dynamics
Despite efficiency, MCTS suffers from sequential bottlenecks—tree traversal and trajectory dependency preclude efficient parallel rollout—manifesting in broad, heavy tails in latency.
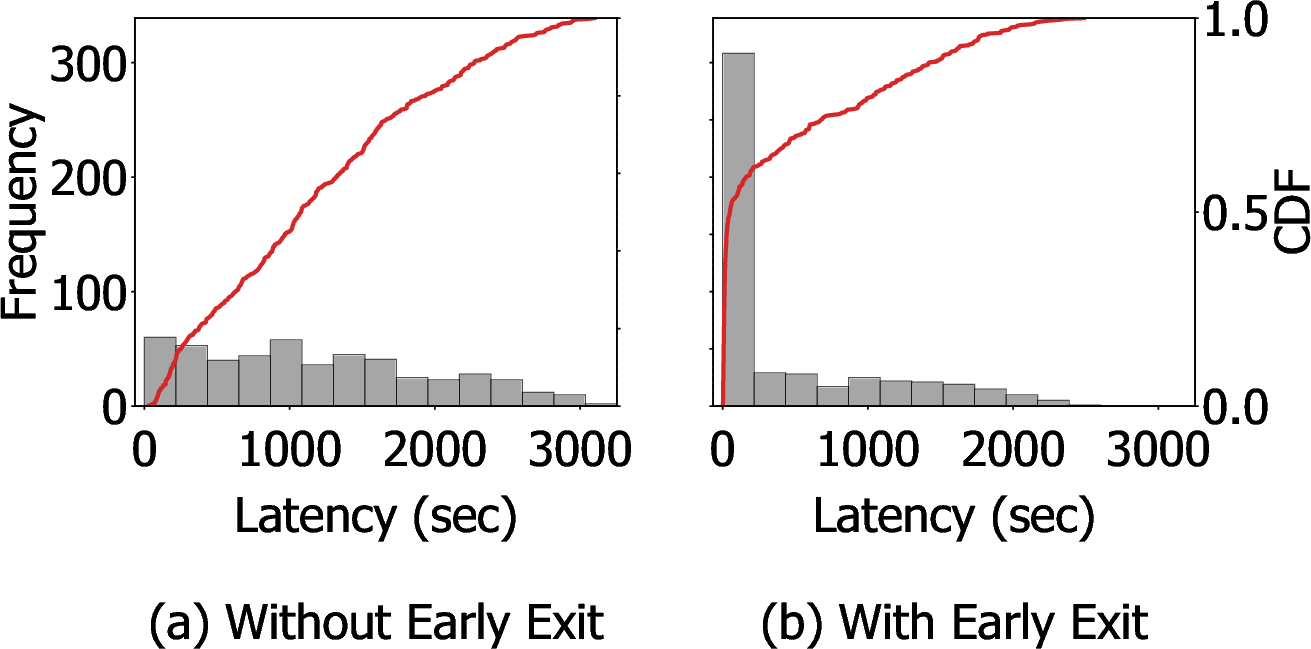
Figure 3: End-to-end latency distribution for sequential MCTS, with and without early exit; positive early exit shortens average latency but outliers persist due to requests unsatisfied by exit condition.
WU-UCT–style parallel MCTS offers wall-clock latency reduction (for high-token tasks) by launching concurrent rollouts using in-flight statistics, enabling softened serial dependencies. However, early root-stage search limits actual parallelism, while modest accuracy fluctuations arise from statistical estimation and floating-point non-determinism in parallel GPU pipelines.
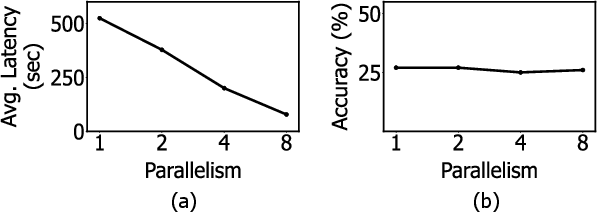
Figure 4: Latency decreases with parallelism, but diminishing returns set in (panel a); accuracy remains stable with minor variations across parallelism degrees (panel b).
Principle of Negative Early Exit
Positive early exit is insufficient: long-tail requests persist when rollouts fail to converge, with cumulative work spent on trajectories already demonstrably futile. The negative early exit criterion leverages the upper-bounded nature of PRM-aggregated leaf scores (e.g., cumulative product/minimum): if all leaves in the current MCTS tree fall below the acceptance threshold, no further rollout can meet the necessary quality. Hence, the search can be provably and safely terminated early in these cases, releasing system resources immediately.
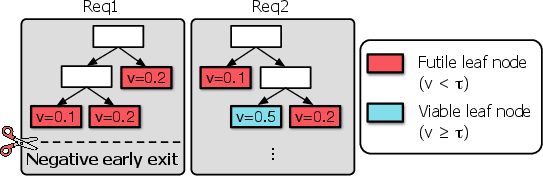
Figure 5: Schematic of the negative early exit: branches that cannot achieve threshold are pruned as soon as this mathematical futility is detected.
The authors further introduce a selective futility check, relaxing the stringent all-leaves criterion by exploiting statistical correlation between low first-depth PRM scores and final trajectory futility. This relaxation enables a practical trade-off between pruning aggressiveness and search completeness, yielding up to 5% effective early terminations on datasets like Math500.
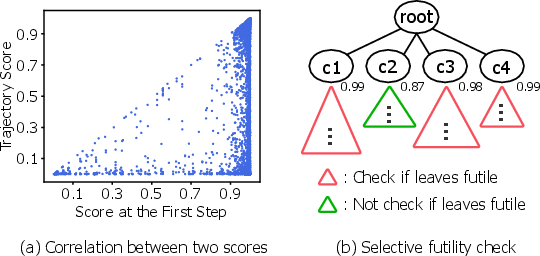
Figure 6: Empirical evidence for the selective futility check – early (first-step) rewards strongly predict final outcome.
Dynamic Parallelism and Resource Scheduling
A dynamic Parallelism Degree Control Policy modulates per-task resource allocation based on elapsed time (“seniority”) and proximity to the positive exit threshold (“score-based urgency”), encoded via a logarithmic scoring transformation. Tasks nearing acceptance receive temporary “boosting,” i.e., increased parallel rollout, accelerating completion to reduce queueing contention and p99 latency. Job admission staging and in-flight preemption further allow for robust assignment and cancellation, with system elasticity prioritized: under diminishing returns, parallel slots are rapidly redirected toward more urgent or promising requests.
Empirical Evaluation
Experiments demonstrate that this integrated scheme provides quantifiable improvements on math reasoning benchmarks (Math500, AMC23) using Llama-3.1 and Qwen2.5 models with strong PRMs. Compared to baseline Beam Search and Vanilla MCTS, as well as MCTS augmented with positive early exit, the full system (PE+NE+Boosting) achieves:
- Up to 2.83× lower p99 end-to-end latency versus serial MCTS (latency decrease from 1,886 ms to 1,277 ms in worst-case)
- Lower p99 and p50 latency under increased arrival rates compared to all baselines
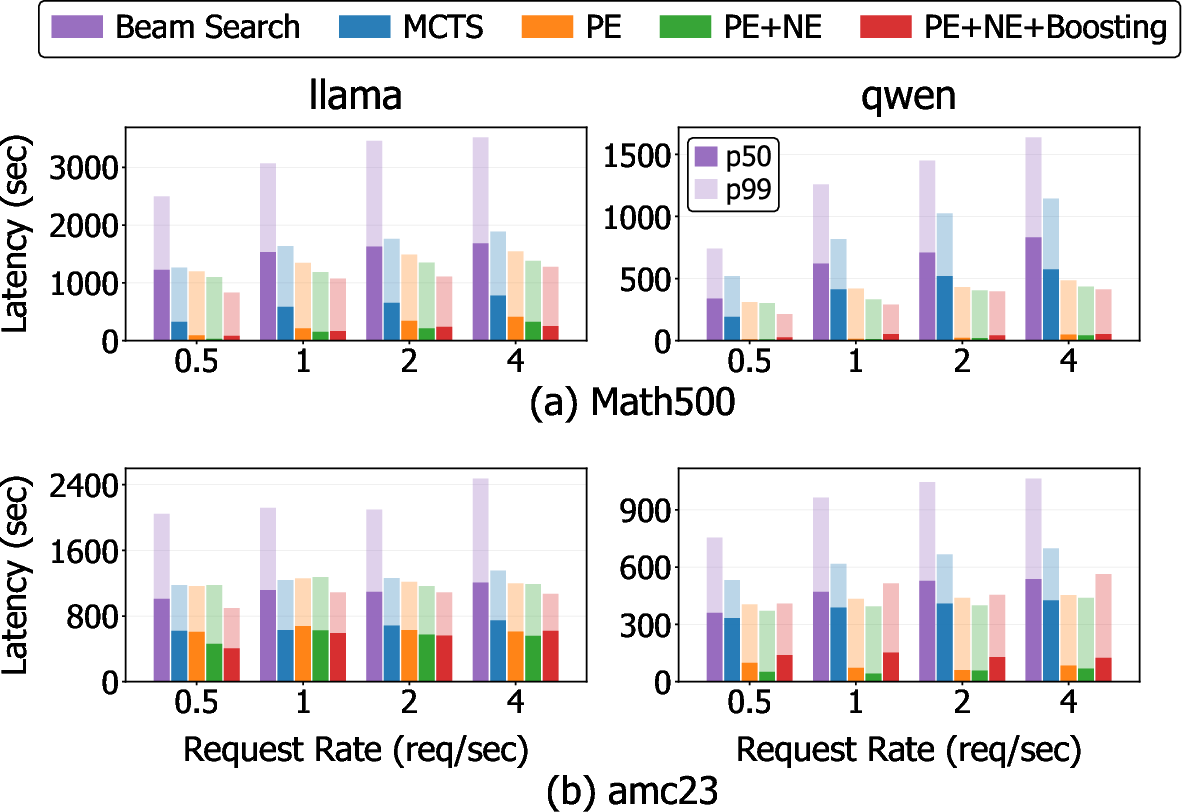
Figure 7: Influence of request arrival rate on p50/p99 latency: the proposed methods, especially with boosting, suppress latency tail and stabilize system behavior as load increases.
- Up to 2.44× increase in throughput, with PE and NE directly improving on sequential variants and boosting maximizing resource yield under high parallel demand
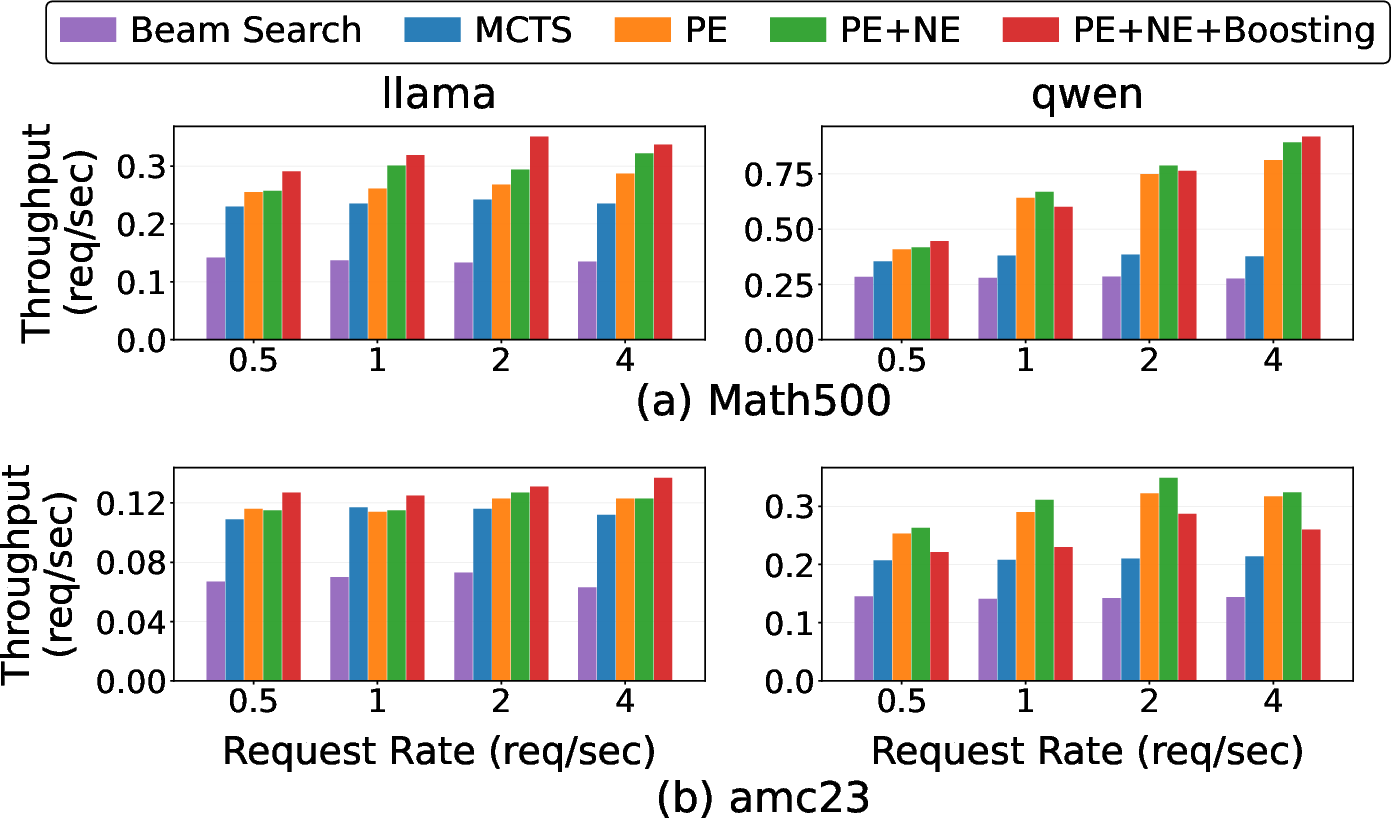
Figure 8: Throughput analysis: all proposed techniques surpass Beam Search and Vanilla; boosting provides the largest gains under compute-bound conditions.
Accuracy on both Math500 and AMC23 remains stable and competitive, with minor variations attributable to non-deterministic floating-point accumulation in high-parallel settings and small sample size effects on AMC23.
Practical and Theoretical Implications
The results underscore the criticality of system-aware resource management for MCTS-based LLM reasoning. Pure search acceleration or early exit via positive signals does not address the dominant system cost: computation expended on provably unproductive rollouts. By reframing MCTS as a consumer of constrained compute budget, with adaptive resource reallocation and analytically justified negative exit, large-scale deployments can achieve low tail latency and high throughput without relaxing accuracy guarantees.
For future developments, extensions might explore:
- Integration with fine-grained progress predictors or cost models for more granular pruning
- Optimization under multi-tenant, heterogeneous task mixes
- Tight theoretical bounds on statistical futility under broader PRM distributions
- Application beyond math reasoning, to domains where stepwise PRM signals are present (e.g., program synthesis, scientific discovery, structured planning)
Conclusion
This work establishes that the primary deployment barrier for MCTS-based TTCS is not in marginal accuracy, but rather system-level variability stemming from unproductive or under-constrained search. Introduction of negative early exit and compute boosting, dynamically scheduled, rectifies this by minimizing tail latency and maximizing effective throughput. The proposed system operationalizes MCTS-based TTCS as a controllable, scalable inference engine for reasoning tasks, enabling practical deployment in real-world LLM serving infrastructures.