- The paper introduces an uncertainty-aware deferral mechanism that routes decisions from a small LLM to a large LLM when uncertainty exceeds a calibrated threshold.
- Empirical evaluations on ALFWorld and MiniGrid show near-large-model performance with only ~15% large-model calls, yielding significant cost savings.
- The framework leverages action-level information-theoretic metrics—achieving PRR > 0.39 and ROC-AUC > 0.68—to ensure robust sequential decision-making.
Uncertainty-Aware Deferral in Sequential LLM Agents: The ReDAct Framework
LLM-based agents are increasingly deployed for complex sequential decision-making tasks in embodied environments where hallucinations can have catastrophic impact, compounding irreversibly through the trajectory. Larger LLMs exhibit lower hallucination rates but incur prohibitive computational expense per token. The paper introduces ReDAct, a framework leveraging uncertainty-aware selective deferral to balance trajectory reliability with inference costs by equipping agents with a dual-model mechanism: a small, efficient LLM and a large, robust LLM. At each decision step, if the small model’s uncertainty exceeds a calibrated threshold, action selection is deferred to the large model, enabling cost-efficient execution without sacrificing reliability. The architecture aligns with agentic paradigms such as ReAct but augments decisionmaking with uncertainty quantification.
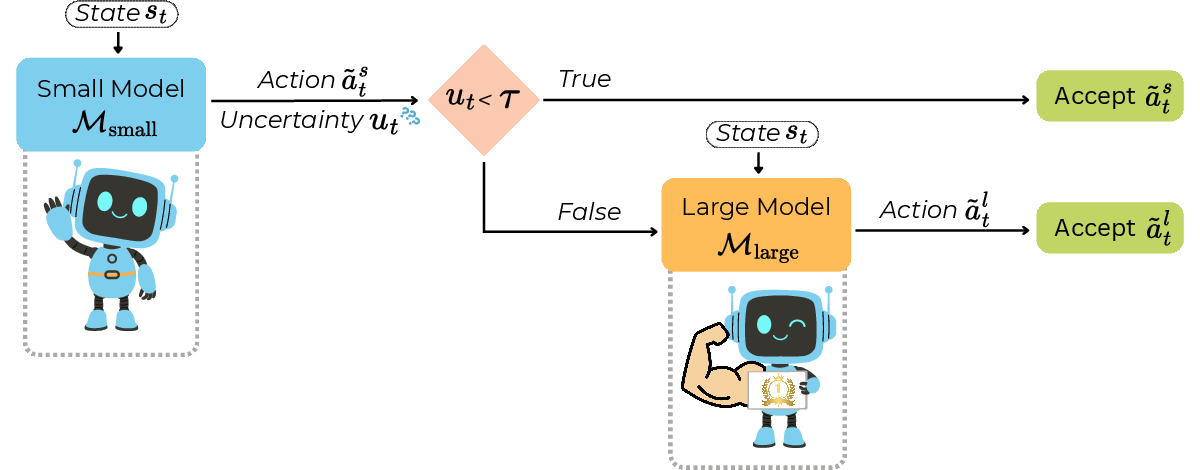
Figure 1: Overview of the ReDAct framework; small model proposes an action and uncertainty estimate, deferring to large model if uncertainty exceeds threshold τ.
Uncertainty Quantification and Deferral Criteria
ReDAct’s central insight is the use of action-level information-theoretic uncertainty metrics computed from token-level probabilities. The framework considers Sequence Probability (SP), Perplexity (PPL), and Mean Token Entropy (MTE) as effective uncertainty signals:
- Sequence Probability: Negative log-probability of the generated action sequence.
- Perplexity: Average negative log-probability per token.
- Mean Token Entropy: Average token-wise output entropy.
These metrics are calibrated on a holdout set to achieve target rates of large-model invocation per episode. Empirical analysis confirms that action-level metrics substantially outperform reasoning-level uncertainty scores, achieving PRR>0.39 and ROC-AUC>0.68 on ALFWorld, indicating high discrimination between correct and incorrect actions.
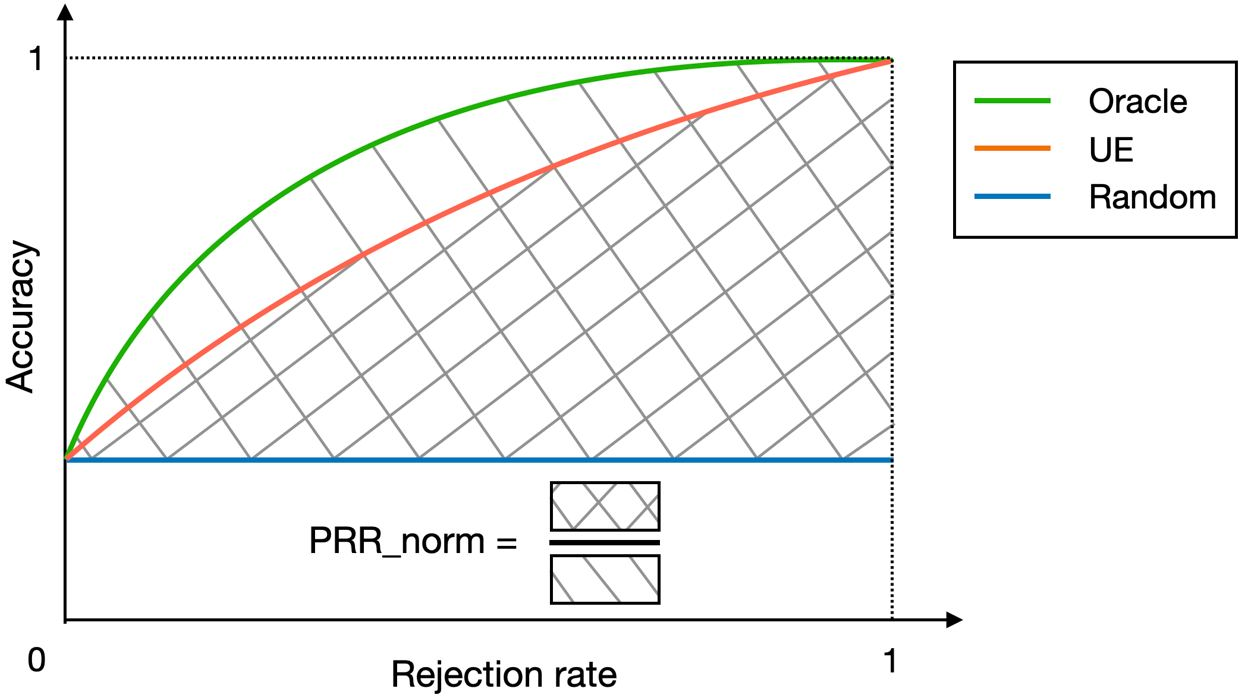
Figure 2: Prediction-Rejection Ratio (PRR) curve, quantifying discriminative power of uncertainty scores over rejection thresholds.
Experimental Evaluation
The paper evaluates ReDAct in ALFWorld and MiniGrid, both text-based embodied environments with irreversible state changes.
Models: Small models include Qwen3-80B, Llama3.3-70B, Llama4-Maverick. Large models include GPT-5.2, Qwen3-480B, Qwen3-235B (≥70B parameters).
Metrics: Primary metric is episode success rate. Cost is measured in USD via token usage per model.
On ALFWorld, PPL-based deferral matches the success rate of full large-model deployment (≈0.78) while invoking the large model for only 15% of decisions—attaining strong Pareto-optimality in the trade-off between performance and cost.
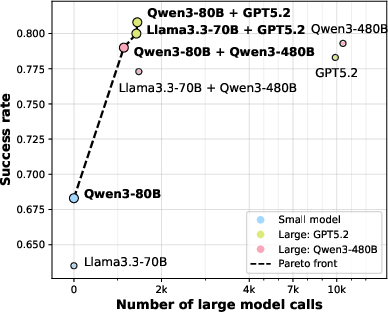
Figure 3: Pareto front of success rate vs. large model calls on ALFWorld with PPL-based deferral; ReDAct achieves near-large-model performance at ~15% call rate.
Similar trends are observed in MiniGrid, with success rates nearly equal to exclusive large-model usage while maintaining low invocation frequencies.
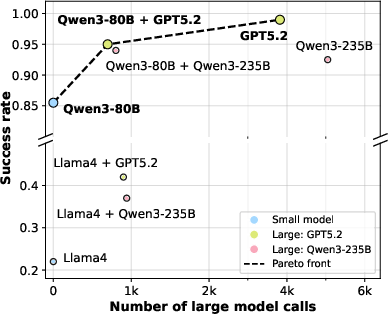
Figure 4: Pareto front of success rate vs. large model calls on MiniGrid with PPL-based deferral; identical cost/performance trade-off as ALFWorld.
Large-model invocation is non-uniform, concentrated at late steps or in episodes where the small model is increasingly uncertain—manifesting adaptive error correction via UQ-guided routing.
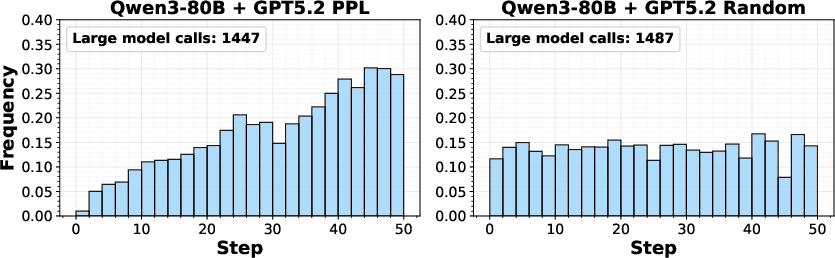
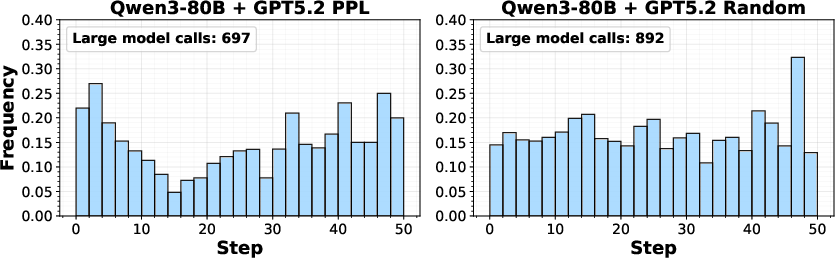
Figure 5: Invocation frequency of large models by step in ALFWorld (top) and MiniGrid (bottom); higher rates in later steps or complex states.
ReDAct consistently outperforms random deferral baselines and achieves substantial savings on inference costs (e.g., $16.25 vs.$45.21 per 400 ALFWorld episodes for PPL-based Qwen3-80B + GPT-5.2 deployment).
Comprehensive cost analyses demonstrate that ReDAct achieves Pareto-optimality, shifting agent performance toward high success rates at modest incremental cost relative to pure small-model deployment, while avoiding the exponential cost of full large-model deployment.
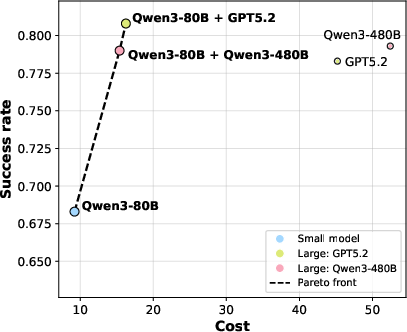
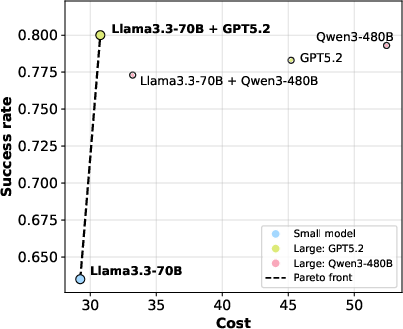
Figure 6: Pareto front of success rate vs. computational cost on ALFWorld for major model pairings.
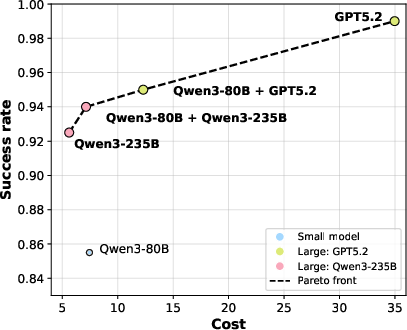
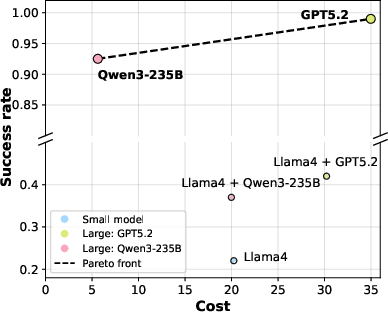
Figure 7: Pareto front of success rate vs. computational cost on MiniGrid; demonstrates effectiveness across architectures.
Theoretical and Practical Implications
ReDAct exposes the criticality of stepwise uncertainty quantification for agentic environments, where error accumulation and irreversible state transitions make selective prediction indispensable. The empirical finding that action-level information-theoretic uncertainty dominates free-form reasoning-level UQ is robust and potentially extends to multimodal agentic domains.
From a practical perspective, ReDAct unlocks frontier-scale LLM agent deployment in cost-constrained environments by reducing reliance on expensive models without loss of reliability. The framework is modular and can be readily adapted to visual-linguistic or real-world control scenarios where sequential error correction is non-trivial.
Future Directions
The work motivates several directions:
- Integration of multimodal uncertainty measures for agents operating in environments beyond text (e.g., vision-language navigation tasks).
- Online or continual calibration of deferral thresholds to mitigate distributional shifts in agent-environment interaction.
- Exploration of hierarchical agentic frameworks involving more than two models, enabling dynamic routing across heterogeneous LLM pools.
- Adaptation of uncertainty-guided deferral mechanisms to adversarial or out-of-distribution settings, leveraging recent advances in LLM uncertainty propagation (2604.07036).
- Application to cost-limited autonomous systems and real-time decisionmaking where computational resources are strictly regulated.
Conclusion
ReDAct establishes a formal uncertainty-aware agentic framework for stepwise deferral in sequential LLM environments. By leveraging action-level information-theoretic uncertainty, ReDAct achieves near-optimal trajectory success rates using only a fraction of large-model calls. The approach is validated across diverse embodied benchmarks and model architectures, demonstrating significant cost-performance improvements and practical deployability for autonomous agents requiring robust planning under uncertainty.