- The paper introduces a two-stage SFT and DPO pipeline that reduces catastrophic VLM error rates from 47.75% to 23% while improving spatial and attribute precision.
- It employs a robust 100K image pair dataset combining automated captioning, EditScore filtering, and human refinement to produce semantically rich editing instructions.
- Experimental results on Eval-400, ByteMorph-Bench, and HQ-Edit benchmarks validate its effectiveness against leading models in precise image transformation tasks.
EditCaption: Human-Aligned Instruction Synthesis for Image Editing via Supervised Fine-Tuning and Direct Preference Optimization
Introduction and Motivation
EditCaption systematically addresses the intrinsic challenges in synthesizing image editing instructions from source-target image pairs using vision-LLMs (VLMs). Unlike semantic captioning for single images, editing instruction generation demands a precise, structured description of transformations. The paper demonstrates that generic VLMs are systematically insufficient for this task, exhibiting three principal failure modes: orientation inconsistency (left/right confusion), viewpoint ambiguity, and omission of fine-grained attributes. Human studies substantiate that more than 47% of VLM-generated instructions are critically unusable in downstream settings.
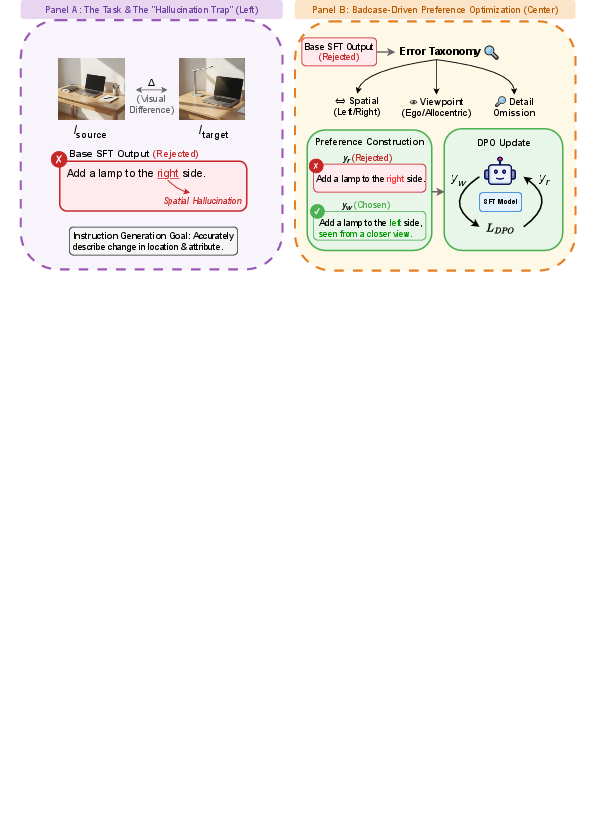
Figure 1: The EditCaption methodology: (a) illustrates primary VLM failure modes on image editing instruction synthesis (directional confusion, viewpoint ambiguity, and missing fine-grained detail). (b) shows the DPO-based alignment process using human-identified failure cases.
Two-Stage Alignment Pipeline
Supervised Fine-Tuning (SFT)
EditCaption initiates with construction of a high-quality 100K-image-pair supervised fine-tuning dataset. The process comprises three steps:
- Automated Caption Generation: GLM is employed to provide initial editing descriptions for image pairs, ensuring scalability.
- EditScore Filtering: An EditScore-based reward model quantitatively filters out syntactically fluent but semantically or spatially misaligned captions.
- Human Refinement: Human annotators revise the filtered set for semantic fidelity, explicit spatial relationships, and fine-grained attribute inclusion.
The constructed SFT dataset is taxonomized into semantic, stylistic, and structural edits, with the latter comprising 50% to emphasize structural and viewpoint transformations.

Figure 2: Training data distribution across Semantic, Stylistic, and Structural editing types.
Figure 3: Visualization of the three-step SFT data pipeline: automated captioning, EditScore filtering, and human refinement.
Direct Preference Optimization (DPO)
Despite extensive SFT, systematic VLM failures persist. The authors construct a 10K preference dataset by sampling model-generated instructions on challenging pairs, annotating human-preferred alternatives that focus on spatial and viewpoint distinctions and fine-grained details. DPO is then used to directly optimize the model towards human preferences by contrasting chosen (human) versus rejected (VLM failure) outputs, effectively targeting and correcting residual, systematic errors.
Experimental Results
The evaluation comprises objective (automatic) and subjective (human) assessments:
- Benchmarks: In-house Eval-400 (diverse edits), ByteMorph-Bench (non-rigid motion, viewpoint changes), HQ-Edit (high-res, detailed annotations).
- Metrics: Weighted combinations of Accuracy, Completeness, and Clarity.
Numerical results establish substantial performance gains for EditCaption’s SFT+DPO models, especially at the large (235B-parameter) scale:
| Model |
Eval-400 Score |
ByteMorph-Bench |
HQ-Edit |
Critical Error Rate (P0) |
Correct Rate |
| Qwen3-VL-235B (SFT+DPO) |
4.712 |
4.588 |
4.630 |
23% |
66% |
| Gemini-3-Pro (closed, 2024) |
4.706 |
4.522 |
4.658 |
21% |
66% |
| GPT-4.1 (closed, 2024) |
4.220 |
3.412 |
4.507 |
42% |
48.75% |
| Kimi-K2.5 |
4.111 |
3.679 |
4.310 |
– |
– |
| GLM4.5V |
3.970 |
3.448 |
3.384 |
51.2% |
38.6% |
| Qwen3-VL-235B (untuned) |
3.880 |
3.462 |
4.397 |
47.75% |
41.75% |
- The SFT+DPO model reduces catastrophic error (P0) from 47.75% to 23%, matching Gemini-3-Pro and halving error rates of open-source baselines.
- The method yields notable gains on the challenging ByteMorph-Bench, with 4.588 vs. the next best 4.522 (Gemini-3-Pro) and a large gap over GPT-4.1.
- Improvements are strongest in spatial accuracy and completeness, indicating effective mitigation of systematic failure modes.
Qualitative results highlight that EditCaption provides structurally precise, spatially unambiguous, and attribute-dense descriptions where strong VLMs like GLM4.5V omit or confuse core transformation details.

Figure 4: Qualitative comparisons of generated instructions demonstrating the EditCaption model’s precision and completeness over Gemini-3-Pro and GLM4.5V; green highlights key advantages, red marks errors/omissions in baselines.
Ablations and Model Analysis
An ablation on training regimes reveals:
- SFT-only produces strong but not optimal outputs (4.44 Eval-400), already surpassing untuned Qwen3-VL-235B and open baselines.
- DPO-only yields inferior factual grounding, establishing that preference alignment is only effective in tandem with SFT.
- SFT+DPO is strictly superior on all metrics, consolidating the pipeline’s complementarity, particularly under spatially challenging evaluation.
Implications and Future Directions
Practically, EditCaption’s data-efficient, scalable alignment pipeline enables robust, high-density construction of instruction-image editing datasets. Its methodology can seamlessly integrate with future VLM-generation pipelines, reducing reliance on expensive manual annotation for complex spatial reasoning tasks.
Theoretically, the results underscore that the failure modes of VLMs are largely systematic and not mitigated by scaling or prompt engineering alone. Directly incorporating structured human supervision and preference signals is indispensable to achieve production-grade precision for composition-sensitive vision tasks.
The approach is, however, still constrained by modest dependence on post-hoc filtering (EditScore) to maintain high data quality, and may show limitations on under-represented, highly abstract, or multi-step edits in its present form. Future work should investigate integrated quality-aware generation, extended compositional scene understanding, and end-to-end downstream system validation.
Conclusion
EditCaption establishes a formalized, empirically validated framework for human-aligned instruction synthesis in image editing, explicitly addressing spatial, viewpoint, and attribute granularity deficiencies endemic to standard VLMs. By leveraging a two-stage SFT+DPO alignment pipeline, the method achieves open-source state-of-the-art results, closely rivaling the strongest available proprietary models in both quantitative benchmarks and human evaluation. The work provides a scalable foundation for future instruction-centric dataset construction and VLM post-training in fine-grained visual reasoning applications.

