- The paper introduces the SSR framework, which explicitly enforces sparsity by filtering noisy input features using both static (SSR-S) and dynamic (SSR-D) mechanisms.
- It demonstrates significant performance improvements, with SSR-D achieving up to 3.5% gains in GMV and efficient scaling on billion-scale platforms.
- Ablation studies highlight that multi-view decomposition and the dynamic ICS mechanism are critical for isolating noise and maintaining smooth gradient flow.
Explicit Sparsity for Scalable Recommendation: The SSR Framework
Motivation and Empirical Evidence of Sparsity
Scaling deep recommendation models using dense MLPs has not yielded the same performance improvements observed in other domains, such as NLP. The paper "Beyond Dense Connectivity: Explicit Sparsity for Scalable Recommendation" (2604.08011) conducts an empirical analysis of industrial CTR models, showing that the learned weight matrices are intrinsically sparse, with over 92% of connections suppressed to near-zero and 80% of weight mass concentrated within the top 4% of input dimensions.
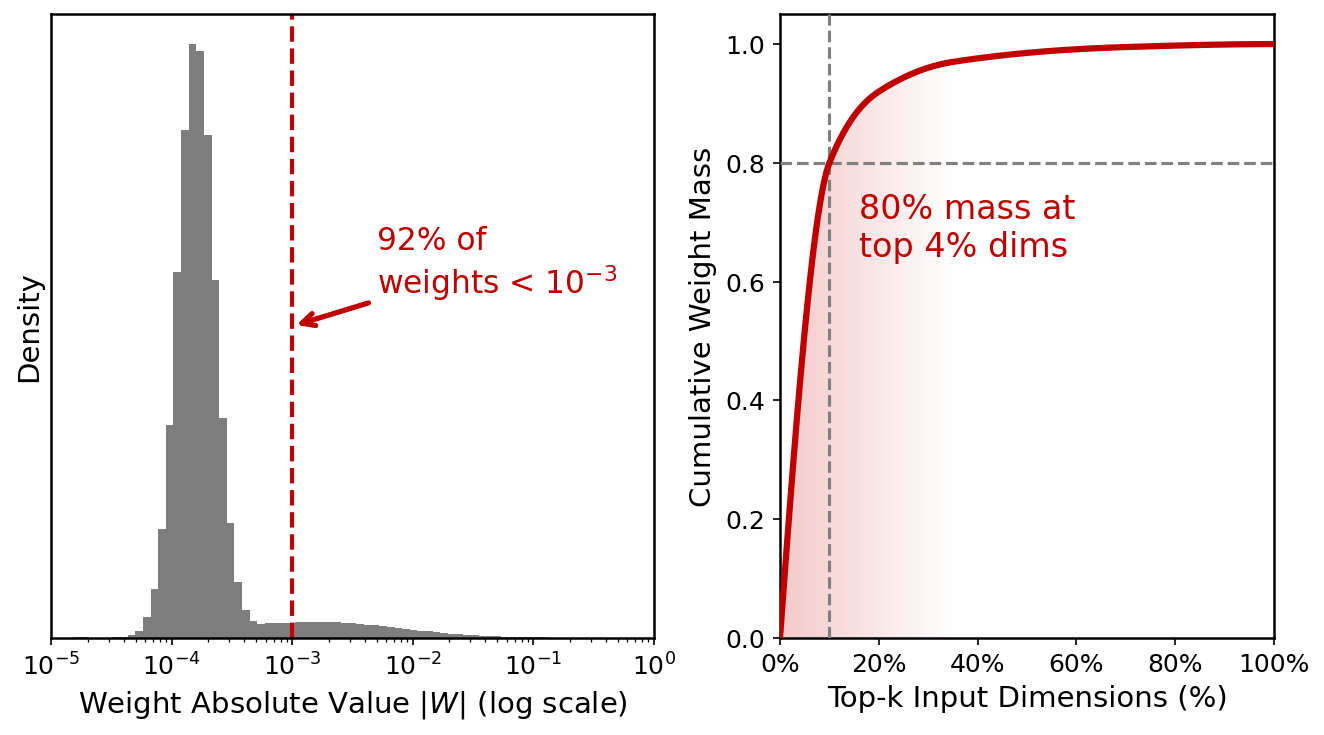
Figure 1: Sparsity analysis of hidden layers in an online CTR backbone, indicating pervasive implicit sparsity despite dense connectivity.
This strong implicit sparsity highlights a core architectural limitation: dense layers indiscriminately mix high-dimensional, sparse data, compelling models to waste capacity suppressing a majority of noisy or irrelevant signal. The mismatch between globally dense connectivity and inherently sparse input signals in recommendation tasks is thus underscored as a bottleneck for modeling fidelity and scalability in large-scale systems.
The SSR Framework: Design and Mechanisms
The paper introduces SSR (Explicit Sparsity for Scalable Recommendation), an architectural framework for large-scale recommendation that implements explicit sparsity at the computational graph level to match the data characteristics of the recommendation domain.
SSR proceeds by decomposing the input into multiple parallel "views," each performing explicit, dimension-level sparse filtering via one of two mechanisms—Static Random Filter (SSR-S) or Iterative Competitive Sparse (ICS, SSR-D)—followed by dense nonlinear fusion within each view. The overall process follows a "filter-then-fuse" paradigm:
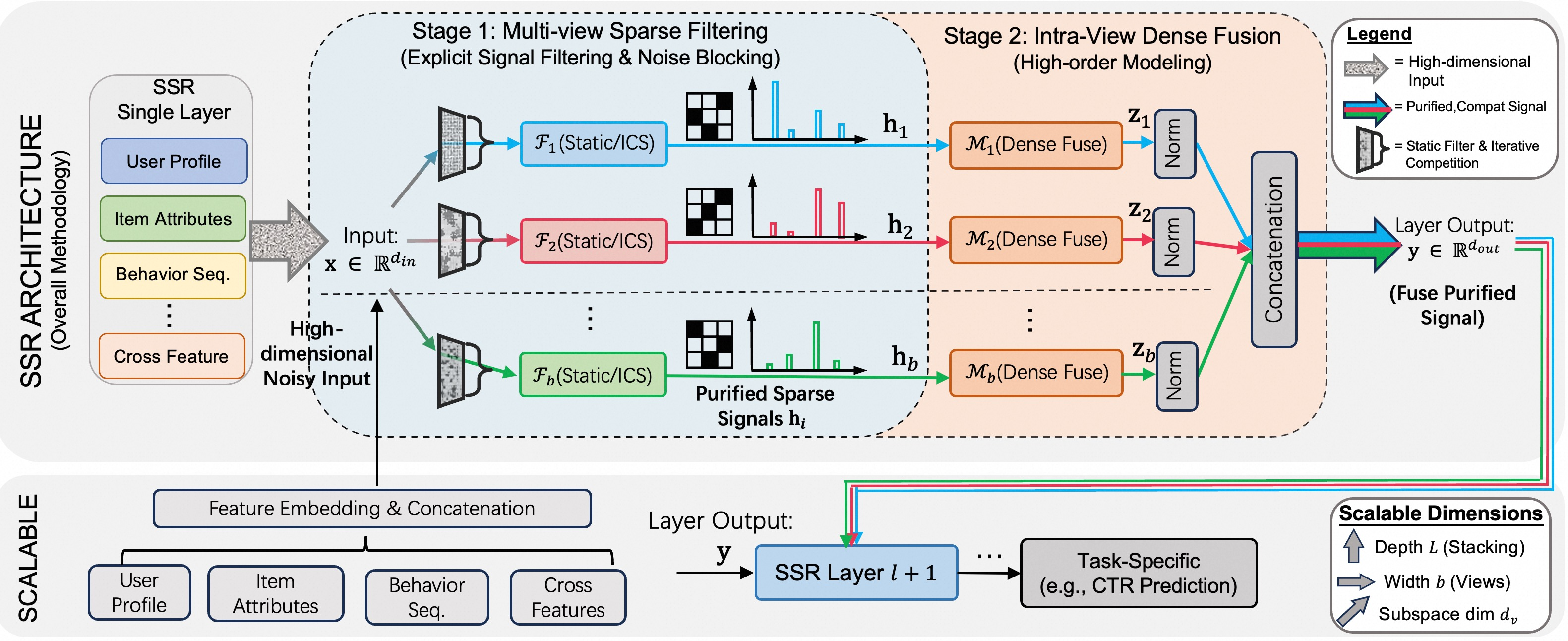
Figure 2: The SSR Framework leverages multi-view sparse filtering followed by intra-view dense fusion to maintain information density and minimize noise propagation.
- SSR-S (Static Random Filter): Applies fixed, randomly-sampled binary selection matrices for hard structural sparsity. This achieves statically enforced dimension reduction with minimal computational overhead, blocking irrelevant features at the source.
- SSR-D (Iterative Competitive Sparse): Implements a differentiable, dynamic mechanism that applies progressive, global inhibition and competition to filter dimensions based on sample-specific context, leading to hard, context-dependent truncation while retaining differentiability.
After filtering, each view is processed independently by a block-diagonal dense transformation. The outputs from all views are concatenated to form the layer output, maximizing diversity and information content while enforcing local semantic isolation within each view.
Dynamic Differentiable Sparsity via ICS
The ICS mechanism is a differentiable alternative to hard top-k selection. By treating feature intensities as populations in a dynamic system and applying adaptive extinction rates across multiple rounds, ICS produces true zeros, ensuring effective sparsity, smooth gradient flow, and efficient computation (complexity O(TN), with T iterations and N dimensions).
Ablation studies confirm significant performance drops when replacing ICS with non-differentiable or stochastic top-k alternatives, highlighting the unique effectiveness of the global inhibition and competitive dynamics central to ICS.
Empirical Scaling and Efficiency
SSR demonstrates superior performance and scalability over both classic (DeepFM, DCN v2) and advanced baselines (MMOE, AutoFIS, RankMixer, Wukong) on massive-scale industrial data (AliExpress) and public benchmarks (Avazu, Criteo, Alibaba). The SSR-D variant achieves the highest reported performance, with gains persisting as model size increases, while dense baselines saturate much earlier.
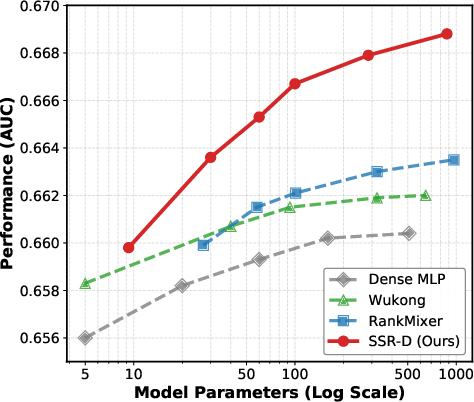
Figure 3: SSR maintains a steeper AUC improvement trajectory as model parameters grow, surpassing dense and mixture-based baselines at all scales.
SSR's explicit filtering outperforms and yields a lower computational footprint than dense or gating-heavy architectures. Static sparsity (SSR-S) achieves leading efficiency and strong accuracy, while dynamic sparsity (SSR-D, with learnable extinction and rescaling) further optimizes context adaptation and high-order interaction discovery.
Architectural Ablation and Representation Analysis
Extensive ablation demonstrates:
- Removal of sparse filtering causes the largest degradation, confirming that pre-fusion noise isolation is critical.
- Multi-view decomposition (parallel views) is key for capturing diverse feature dependencies, and the learned projections are verifiably diverse (orthogonal).
- ICS significantly outperforms dropout, static filtering, non-differentiable top-k, and stochastic selection.
The internal dynamics of ICS across layers show increasing selectivity and convergence stability, with deeper layers exhibiting higher sparsity.
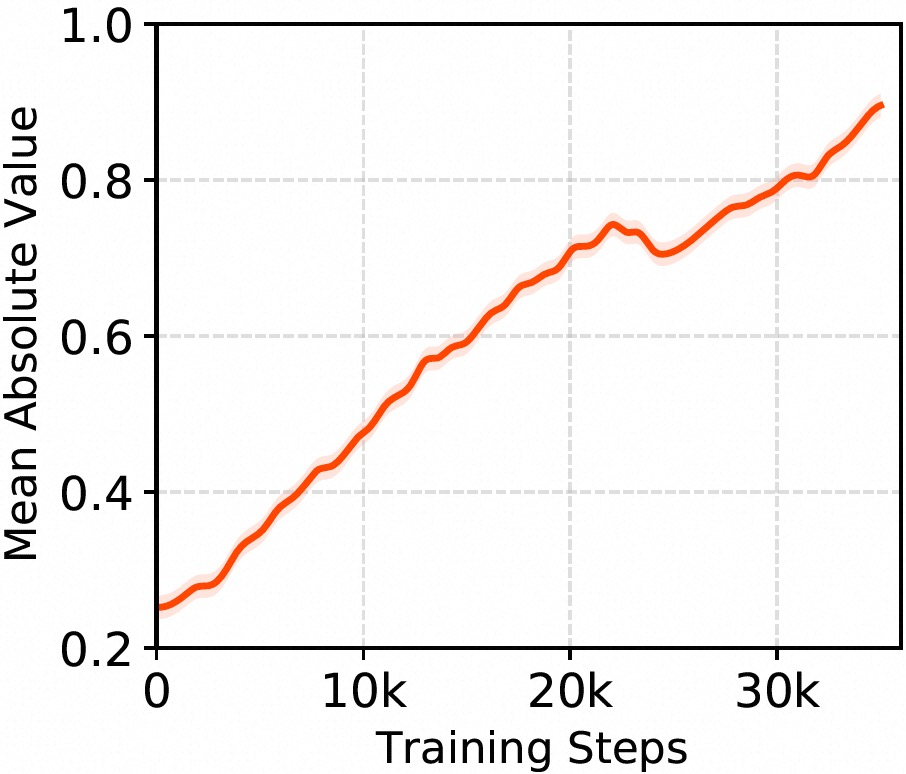
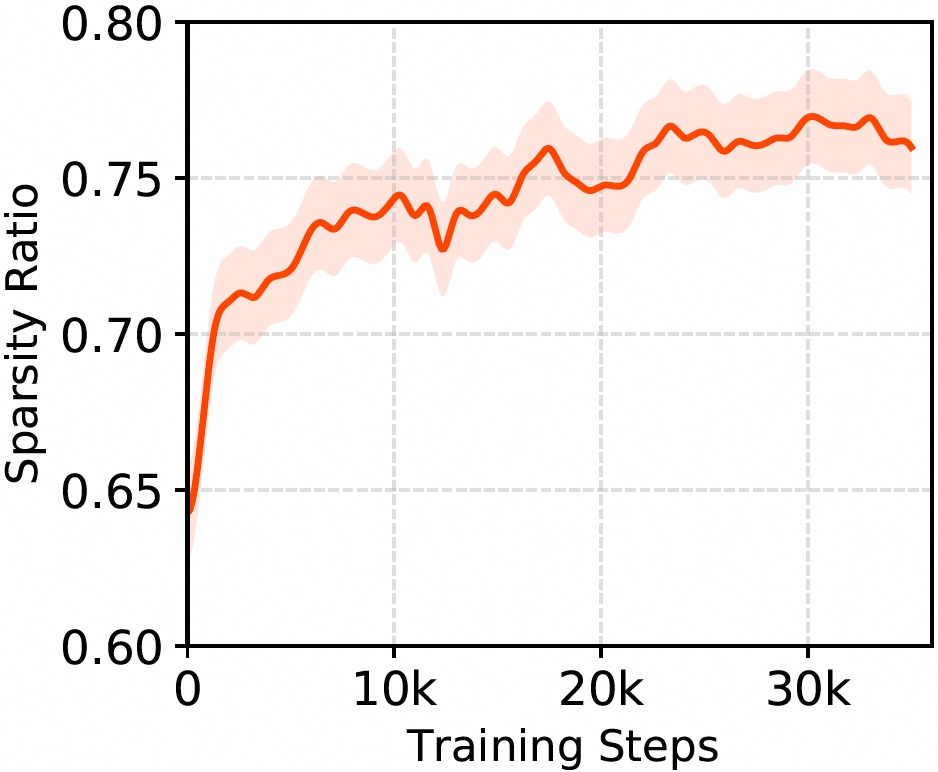
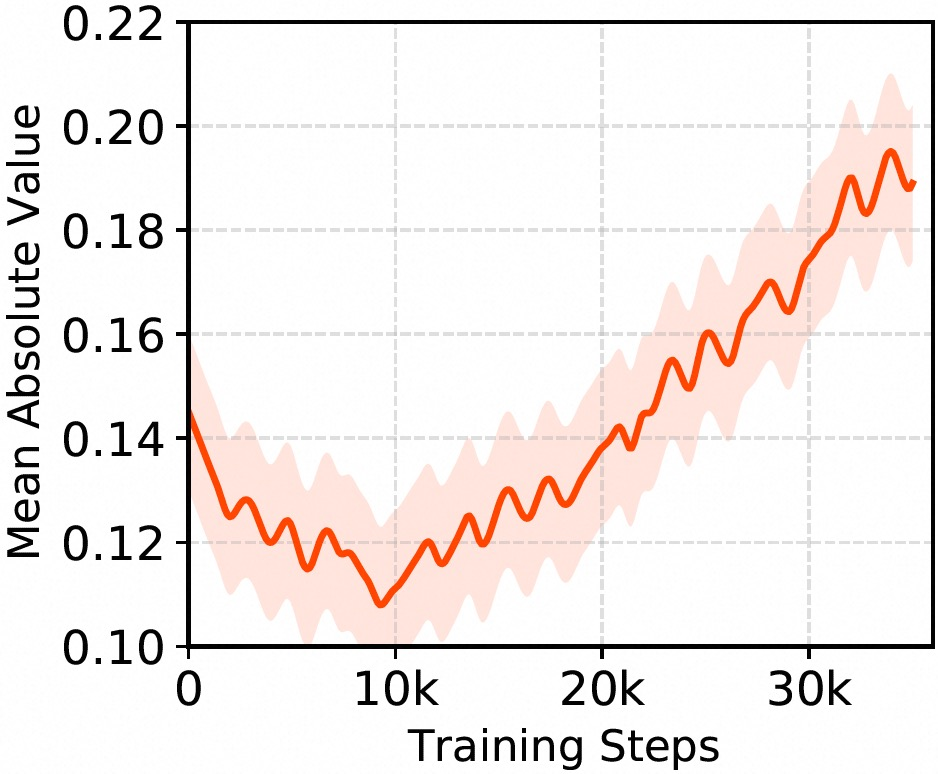
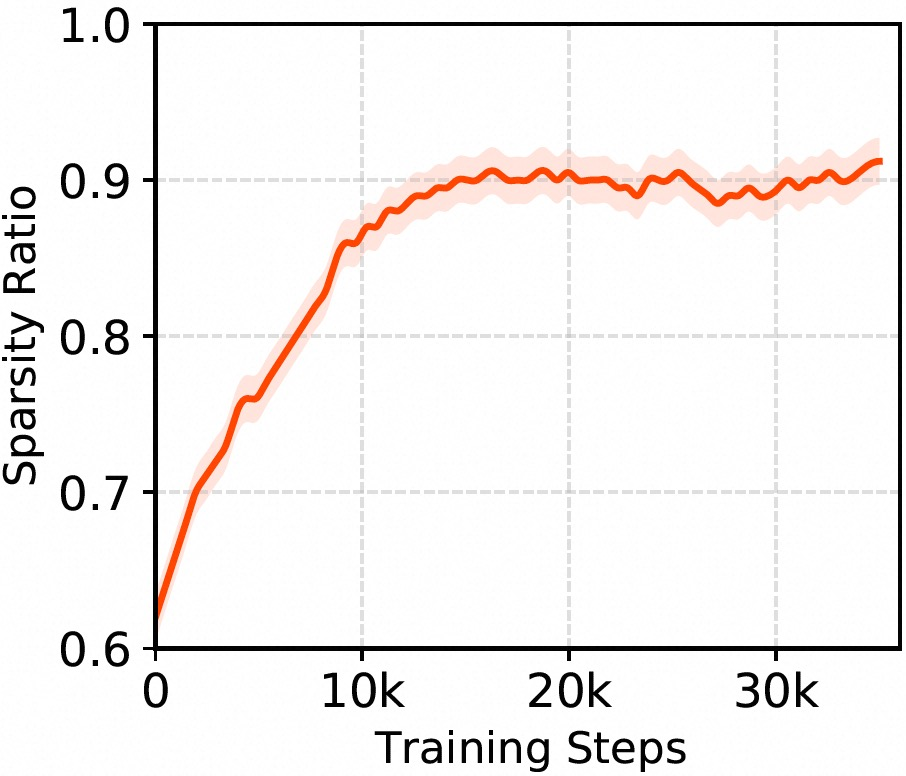
Figure 4: Mean absolute activations within a single view reveal temporal adaptation and learning of signal magnitude.
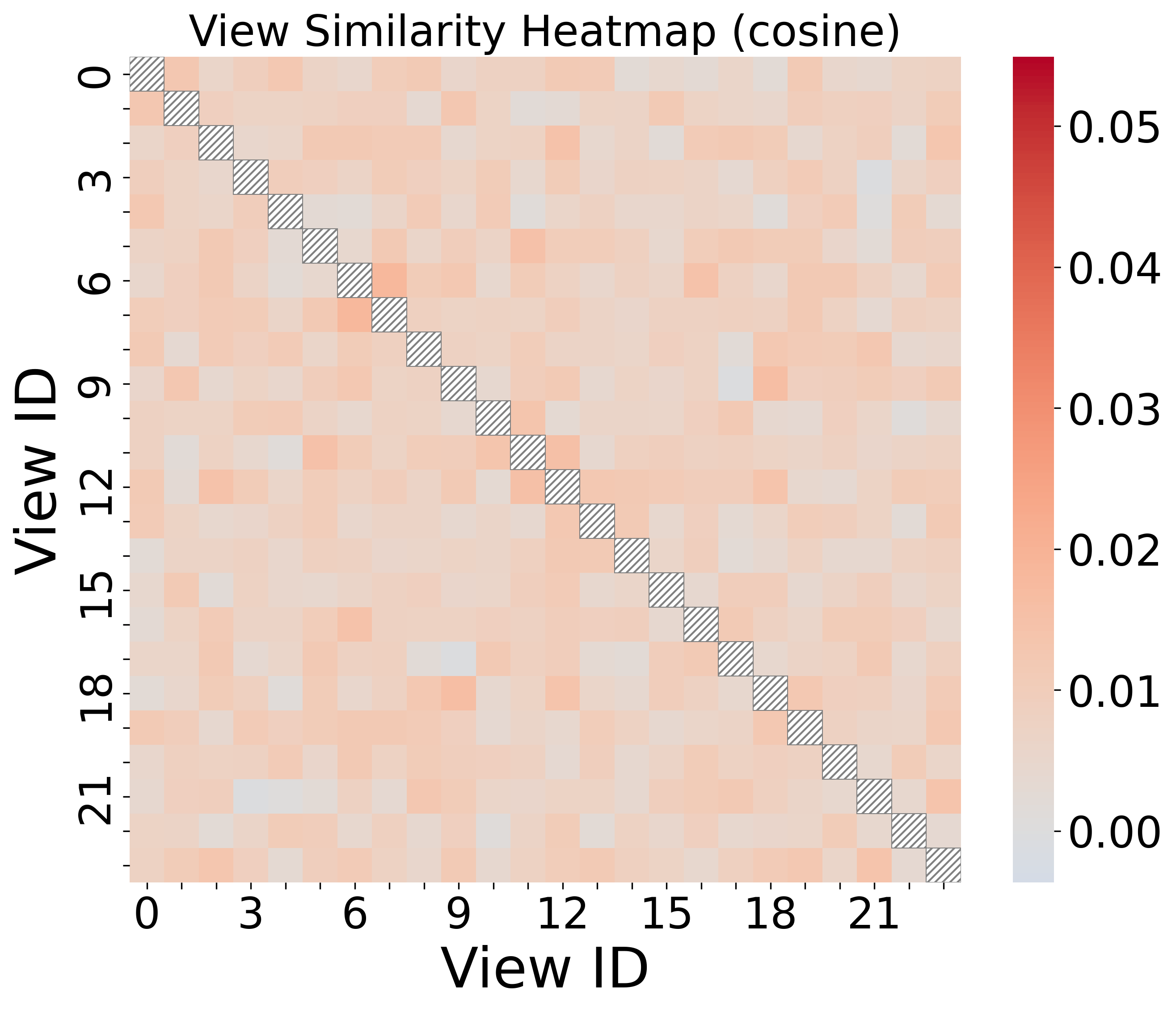
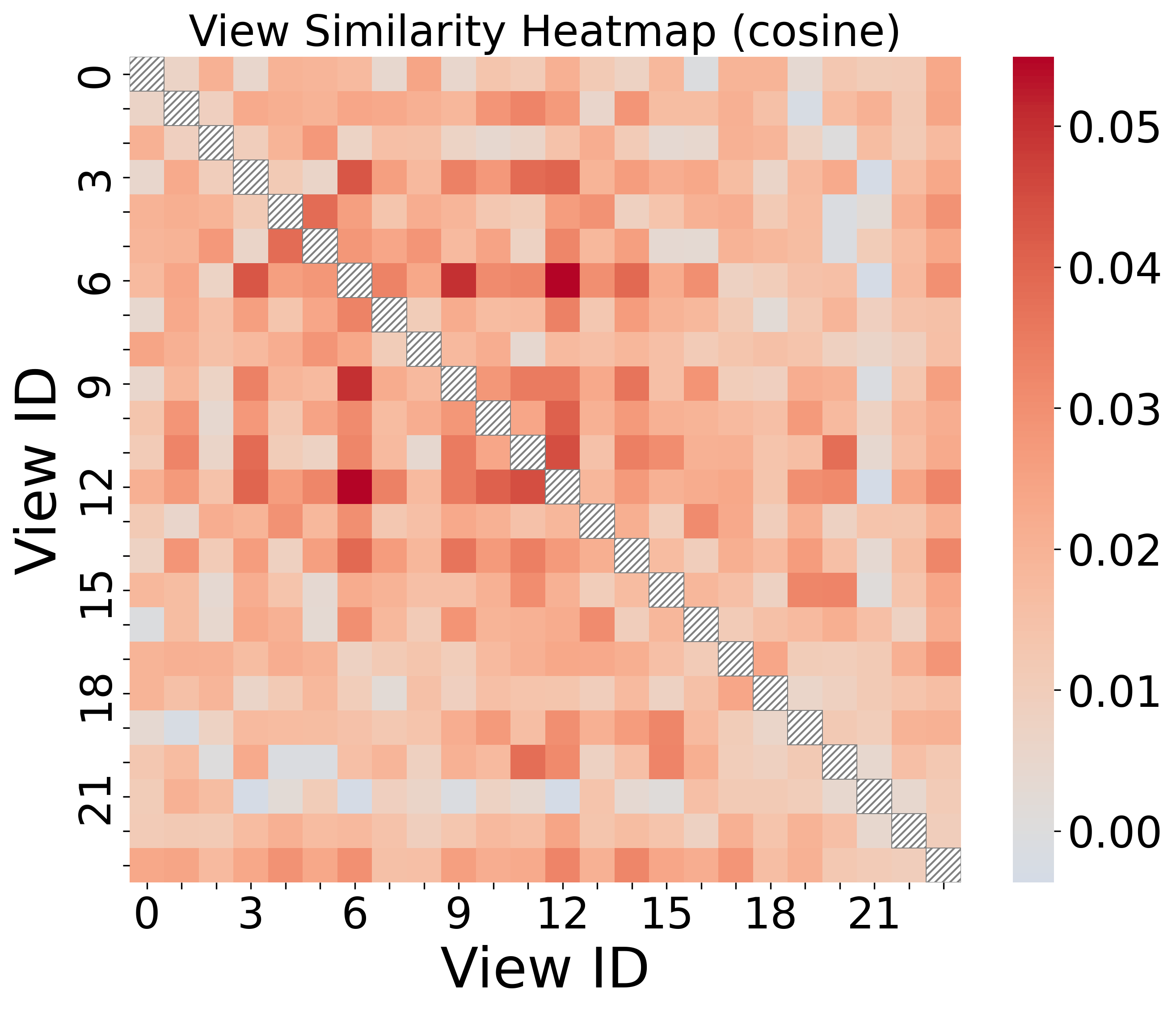
Figure 5: Cosine similarity heatmap across projection matrices in Layer 1 demonstrates low redundancy and strong view diversity.
Real-World Evaluation
Online A/B tests on a billion-scale recommendation platform confirm that SSR-D improves CTR by 2.1%, orders by 3.2%, and GMV by 3.5% with only a +1ms latency overhead compared to an optimized production RankMixer baseline.
Implications and Future Directions
SSR's paradigm—transforming implicit, inefficient sparsity into architectural signal filtering, and combining static and dynamic mechanisms—provides a reproducible method for aligning network capacity with the underlying statistics of recommendation data. By blocking noise propagation before nonlinear fusion, SSR dramatically improves scaling efficiency, breaking the saturation bottleneck that plagues dense networks.
Practically, SSR delivers substantial gains under tight latency budgets and in data-rich environments where parameter efficiency and continuous scaling are critical. The framework suggests new research directions in explicit architectural sparsity, dynamic signal selection, and compositional model design for recommendation and beyond.
Conclusion
SSR advances the state of the art in deep recommendation by enforcing explicit, dynamic sparsity at the architectural level, translating into both superior empirical performance and significantly improved scalability under industrial constraints. The framework's signal-filtering and multi-view composition principles will likely generalize to related real-world domains with high-dimensional, sparse data distributions and motivate further investigation into the interplay between structural design and sample-adaptive sparsification for large-scale learning systems.