Why not Collaborative Filtering in Dual View? Bridging Sparse and Dense Models
Published 14 Jan 2026 in cs.IR and cs.AI | (2601.09286v1)
Abstract: Collaborative Filtering (CF) remains the cornerstone of modern recommender systems, with dense embedding--based methods dominating current practice. However, these approaches suffer from a critical limitation: our theoretical analysis reveals a fundamental signal-to-noise ratio (SNR) ceiling when modeling unpopular items, where parameter-based dense models experience diminishing SNR under severe data sparsity. To overcome this bottleneck, we propose SaD (Sparse and Dense), a unified framework that integrates the semantic expressiveness of dense embeddings with the structural reliability of sparse interaction patterns. We theoretically show that aligning these dual views yields a strictly superior global SNR. Concretely, SaD introduces a lightweight bidirectional alignment mechanism: the dense view enriches the sparse view by injecting semantic correlations, while the sparse view regularizes the dense model through explicit structural signals. Extensive experiments demonstrate that, under this dual-view alignment, even a simple matrix factorization--style dense model can achieve state-of-the-art performance. Moreover, SaD is plug-and-play and can be seamlessly applied to a wide range of existing recommender models, highlighting the enduring power of collaborative filtering when leveraged from dual perspectives. Further evaluations on real-world benchmarks show that SaD consistently outperforms strong baselines, ranking first on the BarsMatch leaderboard. The code is publicly available at https://github.com/harris26-G/SaD.
The paper demonstrates that dual-view fusion of weakly correlated sparse and dense models creates a strictly superior global SNR for recommendations.
The SaD framework employs a bidirectional alignment mechanism, using sparse-to-dense augmentation and dense-to-sparse regularization to improve learning for long-tail items.
Empirical analysis on multiple benchmarks shows up to 25% improvement on unpopular items and robust performance even under severe data sparsity.
Dual-View Collaborative Filtering: Bridging Sparse and Dense Models with SaD
Motivation and Theoretical Foundations
Dense embedding-based collaborative filtering (CF) models, including classic MF and recent GNNs, are known for their ability to capture intricate high-order semantics. However, under substantial data sparsity, their signal-to-noise ratio (SNR) on unpopular (“long-tail”) items fundamentally collapses due to noisy, poorly estimated embeddings. Theoretical analysis reveals a hard SNR ceiling scaling with N, where N is item interaction count, which cannot be circumvented solely via normalization or @@@@3@@@@. Sparse models, in contrast, operate directly on co-occurrence in the user–item interaction graph and prove more robust in the tail regime due to variance reduction from neighborhood aggregation (Equation~\eqref{eq:sparse-variance}).
Crucially, the paper provides a rigorous SNR-based diagnosis and demonstrates, both analytically and empirically, that dense and sparse models are weakly correlated estimators. This weak correlation ensures that their convex fusion, if appropriately aligned, yields strictly superior global SNR—an observation quantified by Theorem 3 (Equation~\eqref{eq:snr-fusion}). Therefore, the optimality frontier for CF demands a dual-view paradigm where structural robustness of sparse models and semantic capacity of dense models are aligned and fused. This insight directly motivates the design of the SaD (Sparse and Dense) framework.
Model Design: SaD Architecture and Dual Alignment
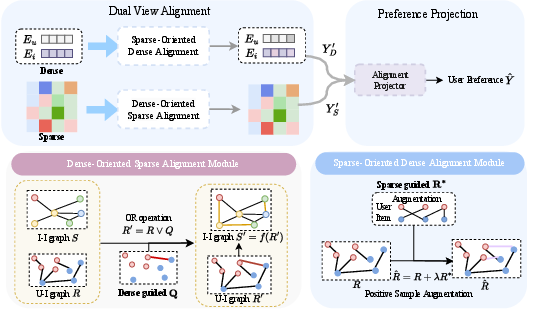
The SaD framework orchestrates explicit interaction between two conceptually distinct CF paradigms (Figure 1). The Dense View models users/items via latent embeddings and typically outputs predictions using inner products. The Sparse View leverages item–item co-occurrence structure, often instantiated via methods such as slim, and produces predictions via explicit aggregation over observed interactions.
Figure 1: Schematic of the SaD dual-view collaborative filtering architecture, illustrating cross-view alignment and integration via the Alignment Projector.
To bridge their gap, SaD implements a bidirectional information alignment:
Sparse-to-Dense Augmentation: The sparse model generates a high-confidence pseudo-positive matrix; top-K candidate interactions inferred from the sparse module are injected into the dense model’s training set, broadening learning signals especially for tail items and reducing embedding variance (Equation~\eqref{eq:dense-var-reduce}). These pseudo-positives are weighted by a tunable confidence parameter λ.
Dense-to-Sparse Regularization: Conversely, the trained dense embeddings serve as a “teacher,” expanding the sparse model’s neighborhood via top-K predictions. The sparse model is thus retrained on a matrix union of observed and dense-inferred interactions (Equation~\eqref{eq:sparse-var-reduce}).
Alignment Projector: Final recommendations are rendered by a learned projection of the two views’ output scores, weighted by a factor β that controls the dense/sparse mix (Equation~\eqref{eq:011}), enabling seamless trade-off between semantic and structural signals.
Empirical Analysis and Component Ablation
Systematic evaluations on four public benchmarks (Yelp, Gowalla, Amazon-Book, Movielens) demonstrate SaD’s universal superiority. It consistently achieves state-of-the-art Recall@20 and NDCG@20, with relative improvements up to 5.4% (Amazon-Book), and ranks first on the BarsMatch public leaderboard.
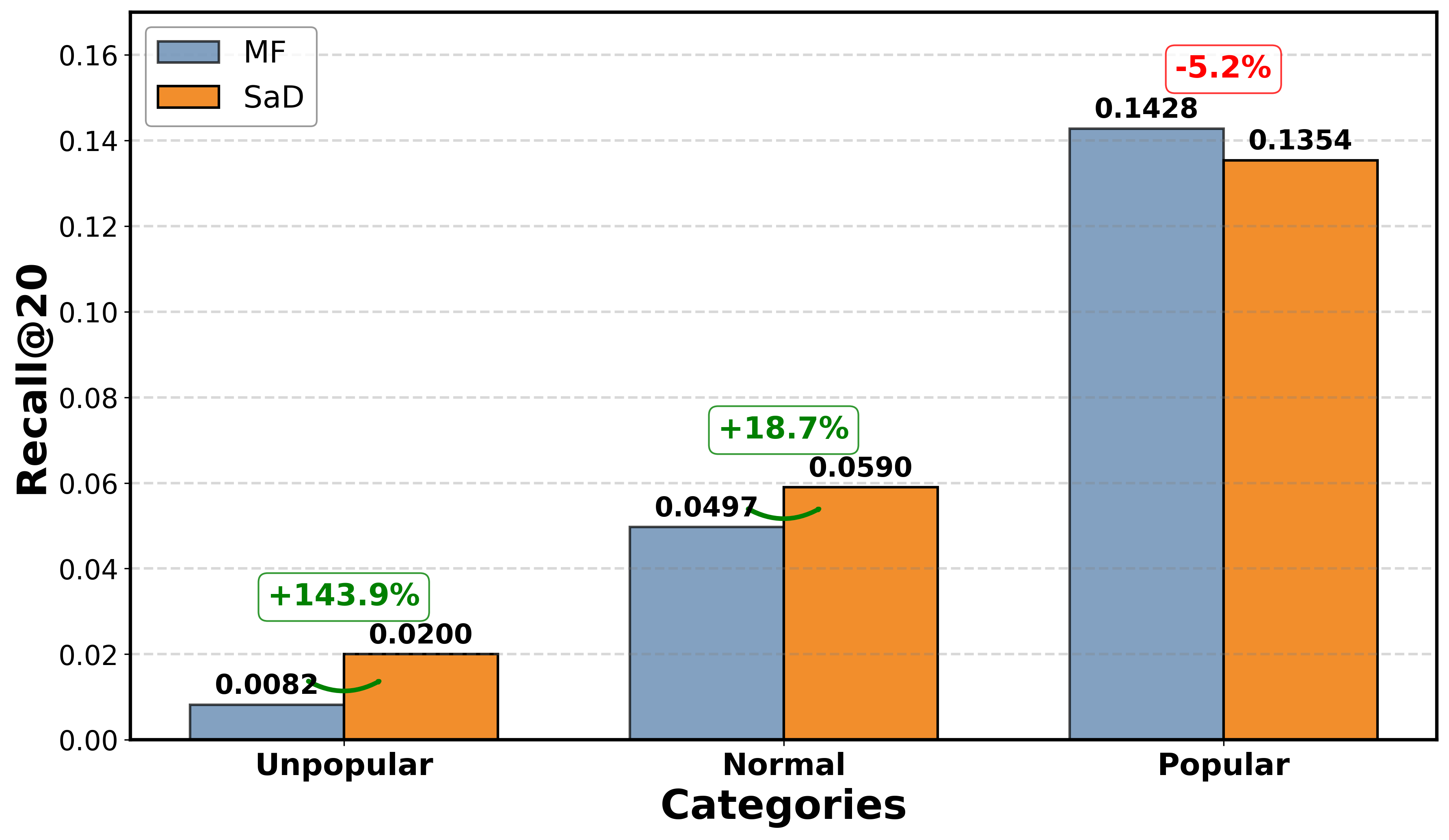
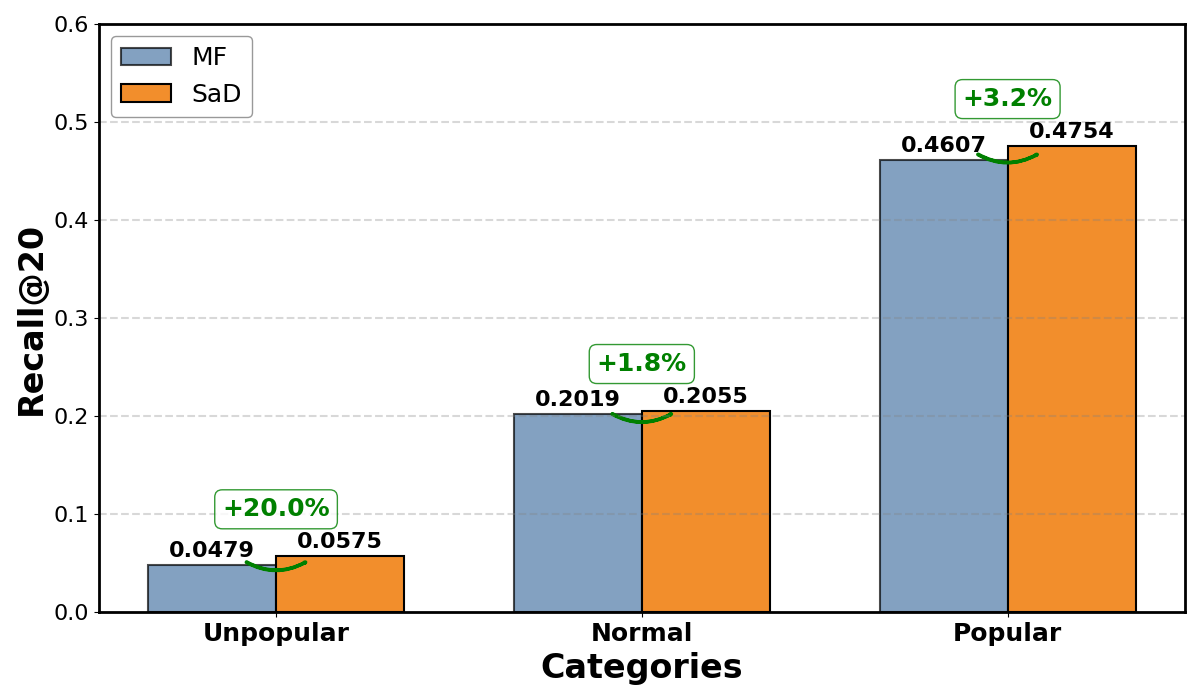
The largest gains occur on unpopular items (long-tail), where SNR benefits from the sparse view are most pronounced. For example, on Movielens, SaD outperforms MF by ~25% on these items, and on Yelp the improvement factor reaches approximately 2.5 (Figure 2).
Figure 2: Under the SaD paradigm, explicit improvements for long-tail items are observed, validating SNR analysis.
Ablation studies confirm both views are essential: stripping cross-view alignment or removing either module causes 2–4% performance drops. Analysis further verifies that information flow from sparse to dense (and vice versa) directly leads to per-view SNR improvement and higher joint optimality, closely matching theoretical predictions.
Generality, Robustness, and Plug-and-Play Integration
SaD’s design is model-agnostic. The dense component can be any latent model (from basic MF to state-of-the-art GNNs such as LightGCN, SGL, SimGCL). Integrating SaD with these backbones further improves their performance, and effects are orthogonal to self-supervised learning methods (Table 5).
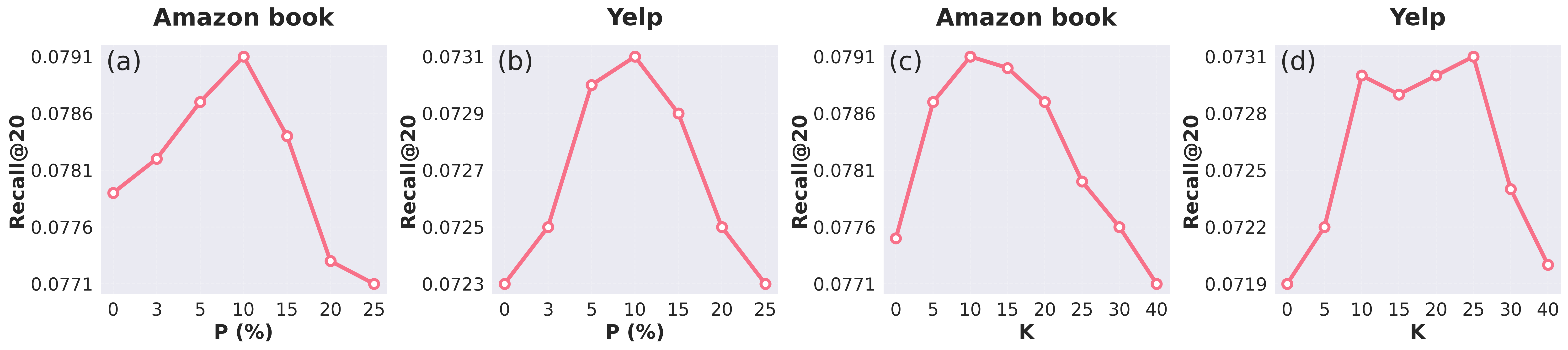
SaD’s robustness is validated via sensitivity analyses across key hyperparameters (pseudo-positive injection rate, top-K, β). Performance persists across wide parameter ranges, with only modest degradation, confirming insensitivity to hyperparameter misspecification (Figure 3).
Figure 3: Analysis of sensitivity to augmentation and top-K supports stability and robustness of the SaD framework.
Additional evaluations on alternative benchmarks, including Amazon subdomains and others, reaffirm portability and generalizability.
Theoretical and Practical Implications
This work delivers several critical messages to CF practitioners and theorists:
Theoretical Unification: The precise SNR analysis clarifies why dense models saturate on tail items and formally proves that dual-view fusion with weakly correlated estimators is statistically optimal for noisy (sparse) data.
Algorithmic Flexibility: SaD serves as a plug-and-play alignment layer, applicable atop nearly any CF pipeline, catalyzing universal gains and facilitating robust cold-start mitigation.
Bias Mitigation: The explicit improvement on long-tail items directly counters popularity bias, with β offering a tunable mechanism for further de-biasing as needed.
Practical Utility: With only minor computational overhead (2 slim passes, 1 dense pass), SaD matches or beats stronger standalone models at lower complexity and supports seamless deployment scenarios.
Conclusion
SaD introduces a principled, theoretically sound dual-view alignment approach for collaborative filtering, delivering robust, state-of-the-art recommendation performance even in the face of severe data sparsity. Its core contribution—demonstrating that cross-view SNR-driven fusion is strictly superior to monolithic dense or sparse models—recasts model fusion from ad-hoc ensemble to statistically grounded optimization. Future lines of inquiry include learning adaptive fusion gates, adding context-aware or side information alignment, and extending SaD to broader tasks such as social and multi-behavior recommendation. The SaD paradigm sets a new standard for structuring CF systems resilient to real-world data challenges.