- The paper introduces SEMCo, a content-only recommendation framework that models user preference via direct item-item similarity without relying on collaborative filtering embeddings.
- It leverages sparse contrastive loss with α-entmax and modality-specific attention to enhance gradient flow and sharply discriminate informative positives and negatives.
- Empirical evaluations across diverse datasets demonstrate significant gains in ranking metrics and fairness, highlighting its scalability and practical impact in cold-start scenarios.
Sparse Contrastive Learning for Content-Based Cold Item Recommendation
Introduction and Motivation
Item cold-start remains a persistent bottleneck in collaborative filtering (CF)-driven recommender systems, particularly impacting the recommendation of items without observed user interactions. Existing cold-start models predominantly attempt to align multimodal content features (e.g. images, text) with learned CF embeddings, but this approach is fundamentally limited by the inherent information gap between behavioral (CF) signals and semantic content representations. The paper "Sparse Contrastive Learning for Content-Based Cold Item Recommendation" (2604.12990) rigorously challenges the representational alignment paradigm by introducing a purely content-driven method, sidestepping CF embedding supervision and directly modeling item-item content similarity as predictive of user preference.
Methodology
Content-Driven Item Similarity Modeling
Instead of embedding content features into the latent space of a CF model, the proposed approach, SEMCo, directly encodes item content into a latent space where item-item similarity correlates with user preferences. This is operationalized via a content encoder f(⋅), which aggregates multimodal representations using modality-specific transformations and attention-based fusion, followed by L2 normalization. Preference prediction utilizes matrix multiplications to efficiently compute user-oriented scores based purely on item-item content similarity, leveraging principles from linear autoencoder-based CF techniques.
Sparse Contrastive Loss via α-Entmax
Standard sampled softmax loss is unsuitable in high-cardinality, contrastive content-based contexts due to dense gradient updates induced by non-zero (pseudo-)probabilities for all negatives. SEMCo generalizes sampled softmax with the α-entmax family, parameterizing output sparsity (α=1 recovers softmax, α=2 yields sparsemax). Fenchel-Young loss provides gradient sparsity, focusing updates exclusively on the most informative positives and negatives. This amplifies training signal quality, particularly for content-based similarity modeling, and enables sharper discrimination among candidate items.
Knowledge Distillation in Content Space
SEMCo is extended via knowledge distillation (KD), transferring item-item similarity structure from a high-capacity teacher encoder to a compact student, entirely within the content space. Both offline and online distillation variants are explored, with SEMCo-Online training the teacher and student jointly, employing exponential moving averages as consistency targets. The distillation objective leverages α-entmax-transformed outputs, further concentrating supervisory signals on relevant similarities.
Empirical Evaluations
SEMCo is evaluated against five cold-start baselines (e.g., CLCRec, GAR, GoRec, Heater, ALDI) across four diverse datasets (Clothing, Electronics, Music4All-Onion, Microlens), covering E-commerce, micro-video, and music domains. Metrics include Recall@20, NDCG@20, Item Mean Discounted Gain@20 (MDG@20), and item exposure diversity via Gini coefficients. The cold-start protocol rigorously excludes 20% of items from training.
Key numerical results:
- SEMCo achieves statistically significant gains in recall, NDCG, and MDG across all datasets relative to the strongest baseline, e.g., up to 133.7% improvement in MDG@20 on Electronics.
- Sparsemax SEMCo-Online consistently yields the highest user-oriented and item-oriented accuracy (e.g., up to 14.9% gain in NDCG@20 versus base SEMCo on Music4All-Onion).
- Gini diversity improvements reach 148.7% on Music4All-Onion, indicating substantially more equitable item-level outcomes without sacrificing accuracy.
The distributional equity of cold item predictions is visualized in the Electronics dataset.
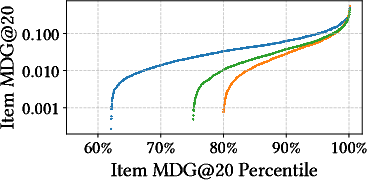
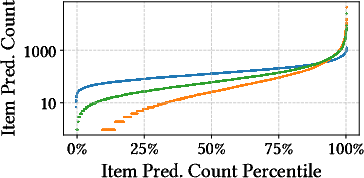

Figure 1: Item MDG@20 and prediction counts across the cold item population in the Electronics dataset, highlighting SEMCo-Online’s balanced coverage relative to GoRec and magnitude scaling.
Analysis and Discussion
Theoretical Implications
Abandoning CF embedding alignment and training solely in the content space eliminates inherited popularity bias. SEMCo’s contrastive, sparse loss objective tightly couples content similarity with proxy user preference, obviating the need for explicit fairness constraints. The sparsity-inducing α-entmax loss leads to high-quality gradient flows: Sparsemax, in particular, enables models to focus on ≤10% of batch similarities during distillation, aligning supervisory signals with the most relevant content structures.
Practical Implications
SEMCo demonstrates superior performance in both ranking and fairness metrics, making it applicable to domains where catalog expansion is rapid and historical interactions are absent or unreliable. The approach scales efficiently by leveraging batch-level computation and modality-specific attention structures. Distillation substantially enhances deployment feasibility for resource-constrained environments, with online variants yielding optimal trade-offs between accuracy and training complexity.
Limitations and Open Directions
While the matrix multiplication approach to user-item scoring is scalable in current experiments, full-catalog inference may pose computational challenges in extreme-scale scenarios. The method assumes the presence of pre-trained content features; extension to missing modality settings remains open.
Future directions include:
- Robustness to incomplete or noisy modality presence [malitesta2026training].
- Further exploration of sparse loss functions and curriculum learning in dense retrieval contexts.
- Integration with domain-adaptive augmentation using LLMs for content enrichment [wang2024large, huang2025large].
Conclusion
SEMCo advances cold-start item recommendation by reconceptualizing the task as a content-only, item-item similarity prediction problem, formalized via sparse contrastive learning using α-entmax loss. Empirical results substantiate strong gains in both ranking accuracy and item-level fairness, particularly through knowledge distillation and sparse supervision in online settings. The findings highlight the necessity of decoupling content-based models from popularity-biased CF supervision, promoting equity and accuracy in item recommendation. The practical and theoretical implications point toward broader adoption of sparsity-controlled contrastive objectives in multimodal cold-start RSs (2604.12990).