- The paper introduces LiVER, a diffusion-based framework that explicitly controls 3D scene layout, illumination, and camera trajectories.
- It employs a renderer-based agent to convert text into structured scene proxies using HDR maps and spatial optimization for precise lighting cues.
- Empirical evaluations show LiVER’s superior performance in lighting fidelity and scene adherence, making it ideal for CGI integration.
Lighting-grounded Video Generation with Renderer-based Agent Reasoning: An Expert Analysis
Motivation and Technical Context
Text-to-video (T2V) generation models have shown significant progress in visual quality and temporal coherence, but suffer from limited controllability in scene layout, lighting, and camera dynamics. Physical realism is frequently compromised—generated videos often exhibit entangled representations for geometry, camera, and illumination, resulting in unnatural lighting phenomena such as inconsistent specular highlights, shadows, and material reflections. Previous works leveraging 3D-aware conditions improve spatial arrangement and camera control, but do not adequately address physically-accurate lighting modeling.
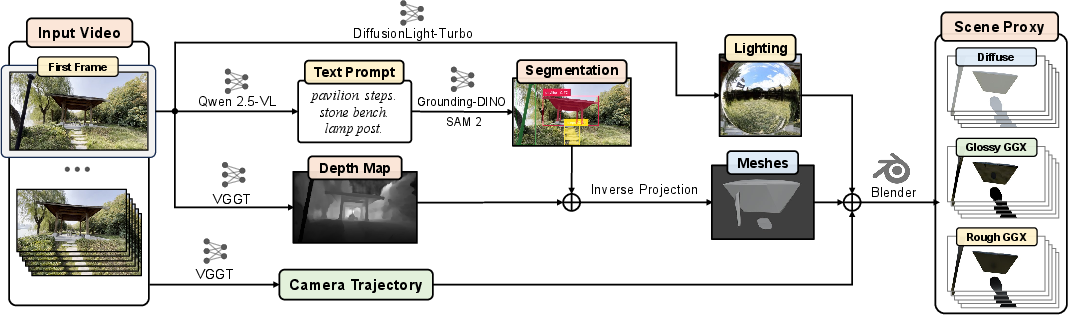
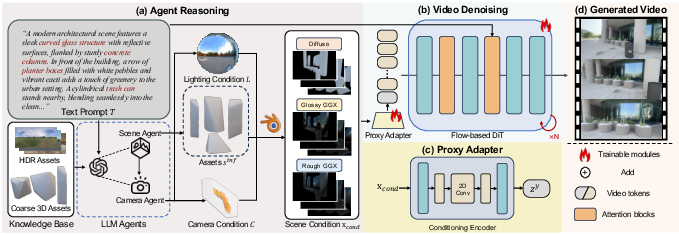
This paper introduces LiVER, a diffusion-based T2V framework specifically designed for explicit, disentangled control over 3D scene layout, illumination, and camera trajectories. Central to LiVER is a renderer-based agent that translates textual instructions into structured scene proxies grounded in 3D geometry and high dynamic range (HDR) environment maps, enabling physically consistent lighting cues.
Data Annotation Pipeline and LiVERSet
The LiVERSet dataset is constructed to address the gap in annotated, lighting-aware video data. It comprises:
Each video is paired with captions generated by Qwen 2.5-VL, supporting semantic guidance. Together, LiVERSet contains $11,000$ clips of $81$ frames at 720×1280 resolution, split equally between real and synthetic domains.
Renderer-based Agent Reasoning
The LiVER agent system parses high-level text and generates explicit conditioning signals. This involves:
This modular proxy-based conditioning disentangles lighting from geometry and camera, enabling targeted control operations.
Model Architecture and Training
LiVER leverages the Wan2.2-5B foundational video diffusion model, integrated via:
- Scene Proxy Encoder: Lightweight 2D Conv blocks map stacked renders into compact spatial features.
- Conditioning Adapter: Residual injection of proxy features into VAE latent space, modulated by a learnable scalar initialized to zero.
- Training Strategy: Three-stage optimization—(1) conditional pathway training on proxy encoder+adapter while backbone frozen, (2) joint LoRA fine-tuning, (3) lighting diversity expansion mixing real and synthetic samples. This staged approach preserves generative priors while progressively injecting control pathways.
Empirical Results
LiVER demonstrates quantitatively superior performance on the LiVER-Real test set, achieving lowest FVD/FID and highest CLIP scores, as well as maximal mIoU for scene layout fidelity. Camera trajectory and lighting error metrics are minimized. Notably, LiVER maintains stable lighting consistency in dynamic scenarios with minimal instability.












Figure 3: Qualitative comparison depicting temporal sequence outputs across baselines and LiVER, showing more realistic lighting and spatial control.
LiVER's superiority is further validated by user studies, with participants overwhelmingly preferring LiVER on all evaluation axes: video quality, scene control, camera, and lighting. Ablation experiments confirm the necessity of synthetic data and staged optimization for disentangled illumination and control fidelity.
Fine-grained Lighting Control and Controllability
LiVER allows continuous manipulation of HDR environment maps, producing spatially and temporally consistent lighting changes (rotation, mood shifts, etc.)—geometry and materials remain stable while illumination evolves.









Figure 4: Model output under dynamic rotation of HDR lighting, showing physically accurate reflections and shading.
Layout and camera conditions are tightly adhered to, enabling precise spatial structure and motion control. The proxy system mimics traditional CGI workflows, allowing post-process editing of conditioning signals and seamless integration with standard 3D software.
Ablation Analysis
The staged training scheme is essential; naive end-to-end training results in degraded outputs and reduced scene adherence. Models trained only on real data fail to generalize dynamic lighting, underscoring the value of synthetic augmentation.














Figure 5: Ablation results demonstrating the impact of synthetic data and staged training on lighting fidelity.
Implications and Future Directions
LiVER fundamentally improves controllability and physical realism for video synthesis by introducing explicit scene proxy conditioning grounded in renderer-based reasoning. The architecture is conducive to integration with professional CGI workflows, enabling both automated and manual control of scene parameters. This unlocks applications in virtual filmmaking, interactive content, and creative media production.
Challenges remain for achieving higher fidelity in coarse 3D proxy reconstruction; the system’s reliance on textual prompts for material/geometry details could be mitigated by advances in prompt engineering and asset retrieval. Further research might explore robust input modalities, improved agent reasoning for higher-complexity scenes, and scalable extension to longer/higher-res content.
Conclusion
The LiVER framework advances the state-of-the-art in controllable video generation by disentangling and explicitly conditioning on scene layout, lighting, and camera in a physically plausible manner. Empirical evaluation confirms superior performance across standard metrics, as well as subjective quality and control preferences. The combination of renderer-based agent reasoning and proxy-driven conditioning establishes a new standard for physically grounded, editable video synthesis for AI-driven media and virtual cinematography.