- The paper presents a novel diffusion framework that integrates intrinsic scene channels with hybrid and masked attention to achieve photorealistic, temporally consistent video synthesis.
- It introduces recursive sampling and switchable LoRA layers to efficiently generate long videos with fine-grained control using global and local text prompts.
- Experimental results on the InteriorVideo dataset show improved FID, FVD, and structural metrics, demonstrating superior quality over baseline video models.
X2Video: Multimodal Controllable Neural Video Rendering via Intrinsic-Guided Diffusion
Introduction and Motivation
The paper introduces X2Video, a diffusion-based video synthesis framework that leverages intrinsic scene channels (albedo, normal, roughness, metallicity, irradiance) for photorealistic video generation, while supporting multimodal controls through reference images and both global and local text prompts. This approach addresses the limitations of traditional physically based rendering (PBR) pipelines, which require expert knowledge and are computationally intensive, and prior intrinsic-guided diffusion models, which lack fine-grained multimodal control and temporal consistency.
Framework Architecture
X2Video extends the XRGB image diffusion model to video by introducing several architectural innovations:
- Hybrid Self-Attention: Integrates Reference Attention and Multi-Head Full (MHF) Temporal Attention to ensure both fidelity to reference images and strong temporal consistency across frames.
- Masked Cross-Attention: Enables disentangled conditioning on global and local text prompts, applying them to specified spatial regions via masks.
- Recursive Sampling: A hierarchical keyframe/interpolation scheme for long video generation, mitigating error accumulation typical in autoregressive sampling.
The overall structure is depicted below.
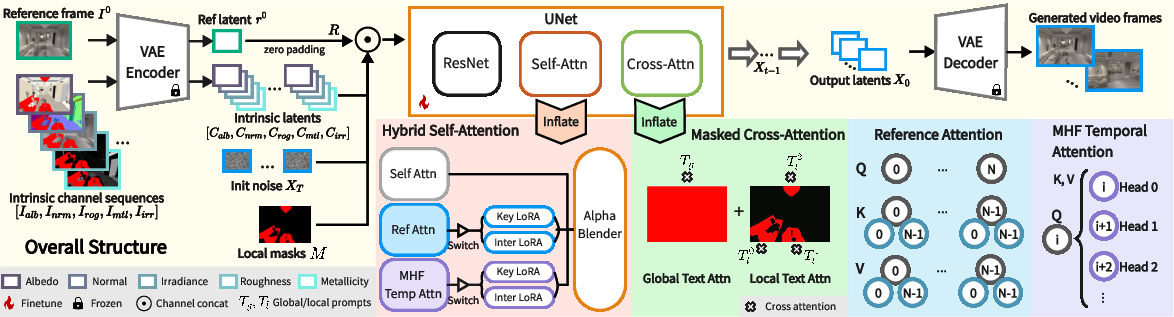
Figure 1: The X2Video framework, showing intrinsic channel input, multimodal conditions, and the attention mechanisms for temporally consistent video synthesis.
Hybrid Self-Attention Mechanism
The Hybrid Self-Attention module is central to X2Video’s temporal modeling. It combines:
- Reference Attention: Each frame attends to the reference frame, maintaining appearance and structure alignment.
- MHF Temporal Attention: Each attention head interacts with features from different frames, enabling full temporal context without increasing computational complexity.
- Alpha Blender: Learnable scalars αr and αt control the contribution of reference and temporal attention, initialized to zero for stable transfer from pretrained image models.
This design allows the model to inherit pretrained knowledge while progressively learning temporal and reference-based correlations.
Masked Cross-Attention for Multimodal Control
Masked Cross-Attention enables precise control over both global and local regions:
- Global Text Prompt: Attended by all spatial locations.
- Local Text Prompts: Each prompt is restricted to its corresponding mask region, allowing localized semantic editing.
- Formulation: The output is a sum of global cross-attention and masked local cross-attention, ensuring disentangled and region-specific conditioning.
Recursive Sampling for Long Video Generation
To generate long, temporally consistent videos, X2Video employs Recursive Sampling:
Dataset: InteriorVideo
The authors introduce InteriorVideo, a dataset of 1,154 rooms from 295 interior scenes, each with smooth camera trajectories and complete ground-truth intrinsic channels. This dataset addresses deficiencies in prior datasets (e.g., missing or unreliable channels, discontinuous trajectories) and is critical for training and evaluating intrinsic-guided video models.
Experimental Results
Intrinsic-Guided Video Rendering
- Qualitative: X2Video produces temporally consistent, photorealistic videos with accurate color, material, and lighting, outperforming XRGB (image model) and SVD+CNet (video model with ControlNet).
- Quantitative: X2Video achieves superior FID, FVD, PSNR, SSIM, LPIPS, and TC scores, with inference speed of 1.08s/frame on RTX 5880 Ada GPU.
Multimodal Controls
- Intrinsic Channel Editing: Parametric tuning of albedo, roughness, and metallicity enables precise control over color, material, and texture.
- Reference Image Control: Restores missing intrinsic information and enables style transfer.
- Text Prompts: Global prompts control overall lighting; local prompts, via masks, edit specific regions.
- Metrics: Adding text or reference conditions compensates for missing intrinsic data, improving all quality metrics.
Ablation Studies
- Hybrid Self-Attention: MHF Temporal Attention and Reference Attention significantly improve temporal consistency and fidelity compared to 1D temporal attention and naive concatenation.
- Masked Cross-Attention: Outperforms attention reweighting and masked replacement in local editing tasks, with improvements scaling with the number of masks/prompts.
- Sampling Scheme: Recursive Sampling prevents error accumulation and maintains color/material consistency over long sequences, outperforming sequential sampling.
Extensions and Generalization
- Adaptation to PBR Styles: Reference frames from different PBR pipelines enable style transfer in video synthesis.
- Generalization to Dynamic/Outdoor Scenes: Despite training on static indoor scenes, X2Video can synthesize dynamic content and generalize to outdoor scenes, with limitations in sky rendering addressed by reference frames.
- Acceleration: Incorporating Latent Consistency Models (LCM) enables 2-step DDIM sampling, reducing inference time to 0.24s/frame with minimal quality loss.
Limitations
- Transparent/Reflective Surfaces: The model cannot synthesize content behind transparent glass or sharp reflections of distant objects due to incomplete 3D scene understanding and intrinsic channel limitations.
- Potential Remedies: Future work may integrate explicit transparency modeling and 3D scene representations to address these issues.
Conclusion
X2Video establishes a new paradigm for controllable neural video rendering by combining intrinsic-guided diffusion, multimodal conditioning, and scalable temporal modeling. The framework demonstrates strong performance in photorealistic video synthesis, flexible editing, and efficient long video generation. Theoretical implications include the feasibility of extending image diffusion models to video via attention-based mechanisms and hierarchical sampling. Practically, X2Video enables intuitive, high-quality video editing and rendering for graphics, vision, and content creation applications. Future research may focus on integrating 3D scene understanding, improving multimodal fusion, and expanding to more diverse domains.
