- The paper introduces a ControlNet-style adapter that leverages high-dimensional DINO features to condition video diffusion.
- It disentangles geometry and appearance through augmentation-driven training, ensuring robust spatial and temporal consistency.
- Experiments demonstrate effective style transfer and 3D conditioning, outperforming traditional edge- or depth-based control methods.
Control-DINO: Feature Space Conditioning for Controllable Image-to-Video Diffusion
Introduction
The paradigm of controllable generation in video diffusion has seen rapid expansion, aligning with the broader emergence of vision foundation models. "Control-DINO: Feature Space Conditioning for Controllable Image-to-Video Diffusion" (2604.01761) formulates a versatile approach to video diffusion control by leveraging high-dimensional self-supervised DINO feature maps as the primary conditioning signal. The authors present a lightweight ControlNet-style adapter that operates robustly on dense DINO features, supporting both 2D (e.g., image) and 3D (e.g., voxel, mesh, point cloud) conditioning signals. Central to the method is the disentanglement of geometry/semantic information from appearance via an augmentation-driven training regime, enabling structural guidance while facilitating flexible style, relighting, and domain adaptation.
Methodology
ControlNet-Style Dense Feature Conditioning
The core architecture comprises a frozen pre-trained video diffusion backbone (CogVideoX-5B-I2V) augmented by a ControlNet-like residual branch. Dense DINOv3 feature maps are extracted for each frame and temporally downscaled via a causal Conv3D adapter to align the temporal resolution with the VAE latent representation. The conditioning branch injects the DINO features by residual addition to the output of the video transformer's first 16 layers, with masking possible for further spatial specificity.
During training, appearance-augmented video frames are denoised, while the conditioning signal is always computed from the unmodified video, encouraging invariance in the residual path to style, color, and illumination attributes. The augmentation protocols span photometric perturbations, neural style transfer (CartoonGAN, AnimeGAN, FastStyle, Drawing), and blur, ensuring coverage of both synthetic and realistic style variations.
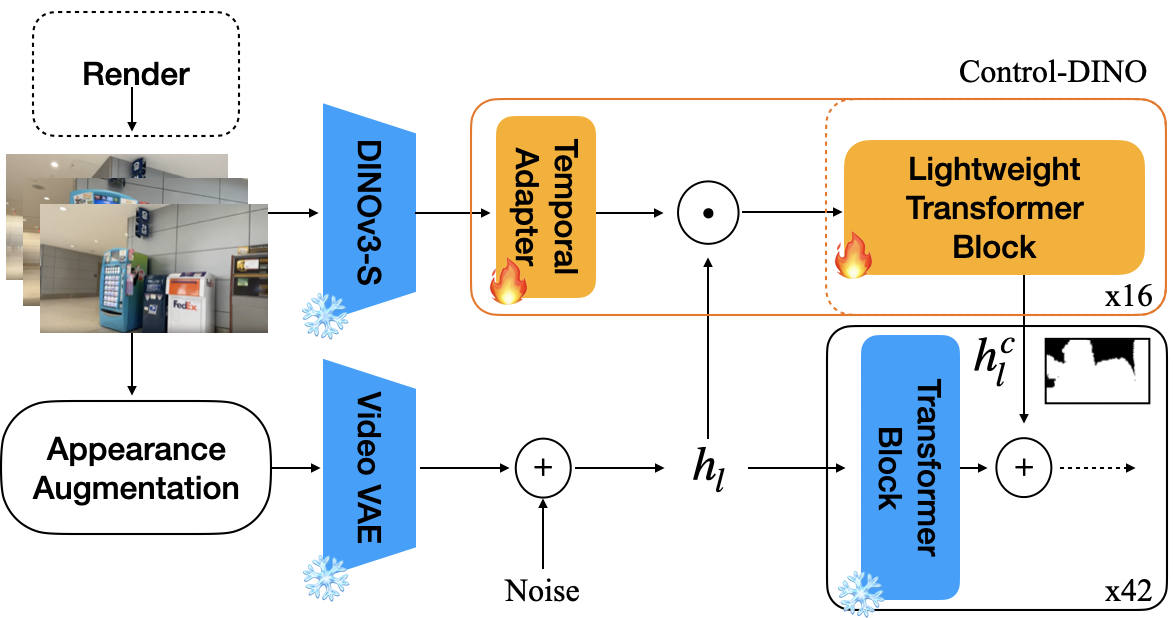
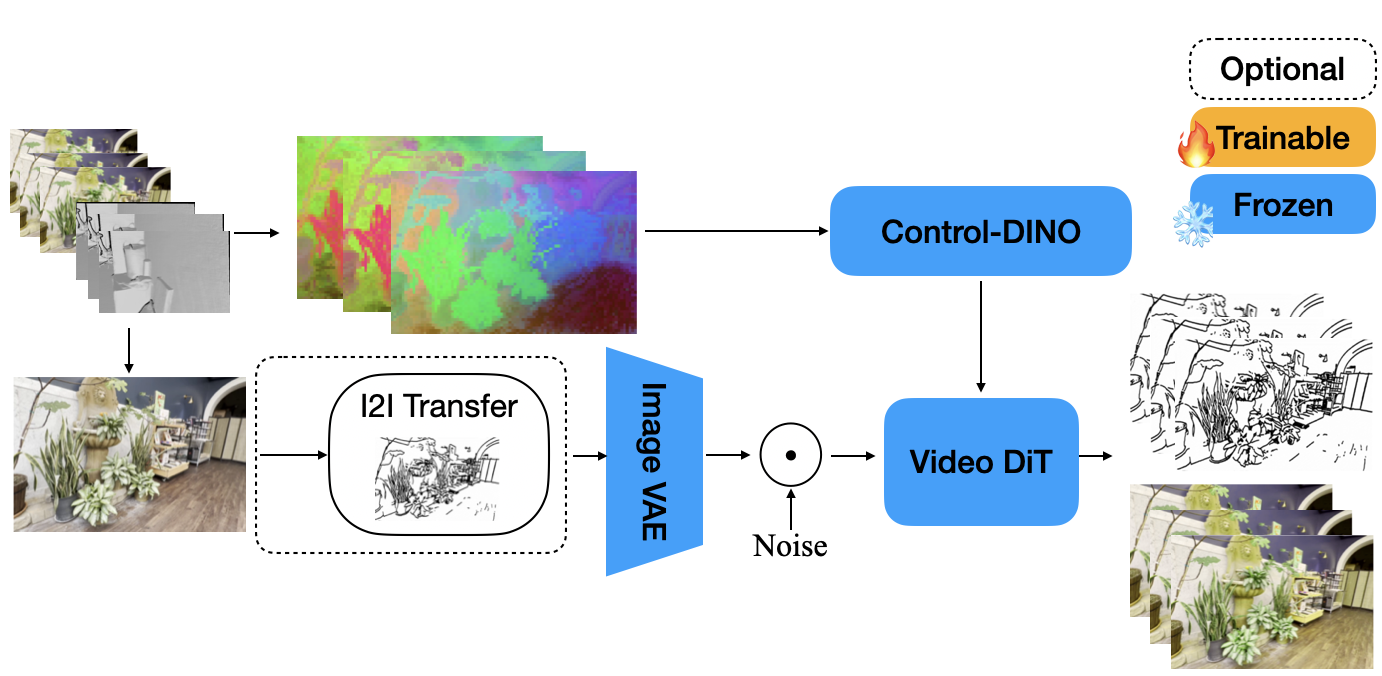
Figure 1: Overview of feature-based training (left) and inference (right). DINOv3 features condition the ControlNet branch, while denoising targets appearance-augmented data, enforcing semantic/structural guidance over appearance.
3D Feature Conditioning and Generalization
A significant extension supported by this architecture is low-resolution, high-channel control from 3D representations. The method supports voxel-based, mesh-based, and point-cloud-derived DINO(-like) descriptors (such as from Concerto or Sonata). These are rendered from the target camera viewpoint, projected onto the ControlNet's token grid, and used for guidance in scenarios with only structural geometry available (e.g., 3DGS, untextured reconstructions), maintaining strong spatial-semantic correspondence with modest compute requirements.




Figure 2: Visualization of 3D structure used as “first frame” conditioning: top—voxel RGB renderings, bottom—mesh renderings.
Experiments
Setup and Baselines
Experiments are conducted on DL3DV and out-of-domain Tanks and Temples (for long-horizon view synthesis), as well as on ScanNet++ for 3D-driven video generation. The method is evaluated against state-of-the-art control-diffusion baselines, including Wan2.2 (Canny, Depth), AnyV2V, and the large-scale Cosmos-Segmentation ControlNet, under both in-domain and cross-domain scenarios.
Image-to-Video Transfer and Stylization
DINO-based conditioning demonstrates robust temporal and spatial consistency, particularly under large camera motion and style shifts. The model, via its appearance-invariant training, permits strong style transfer—preserving geometry and semantics while decoupling appearance—even across extreme relighting and neural stylizations.

Figure 3: DINO feature-conditioned outputs under stylization and lighting shifts. Geometry and semantics are retained, while style and color can be arbitrarily modulated.
Video-from-3D
On ScanNet++, the model shows that even low-resolution voxel/mesh features with appended DINO/Concerto descriptors enable faithful geometry-consistent and temporally stable video generation. In settings where only sparse geometry or uncolored reconstructions are accessible, the approach still maintains semantic plausibility, outperforming edge- or depth-only baselines in structural and perceptual metrics.






















Figure 4: Qualitative comparison at fixed timestamps for ScanNet++ scenes. DINO-based 2D/3D conditioning yields sequences with high geometric and semantic alignment to ground truth, exceeding edge/depth-based methods.
Deterministic vs. Flexible Control
An important experimental finding is the tradeoff between the determinism of high-dimensional feature control and generative flexibility. Strong DINO-based control restricts the solution space—reducing perceptual variance and mode collapse—but can limit diversity. Masking and guidance scaling mitigate this as discussed in the ablations.
Robustness to Conditioning Signal Quality
The architecture tolerates significant variation in input signal quality and modality. It is robust to downscaling of feature map resolution, point cloud sparsification, and changes in voxel size, as demonstrated with ablation studies and conditioning augmentations.

Figure 5: Model robustness to diverse conditioning augmentations. Despite input sparsity or low-resolution, generation quality remains stable if semantic structure is preserved.
Temporal Stability
For long video rollouts, the model shows strong camera and scene consistency (up to 240 frames), benefiting from the structure held in DINO features and the autoregressive inference setup.


































Figure 6: Temporal stability over long sequences; repeated camera poses generate consistent content, with minimal drift or degradation.
Ablative Analysis
The training regime that mixes real and highly augmented data drives appearance invariance but can slightly reduce FID in default “real” generation, compensated by substantial gains in out-of-domain style transfer and long-horizon consistency. Projecting DINO features via PCA incurs significant information loss and degrades control precision, supporting the choice of raw, high-dimensional encoding. Omitting spatial mixing constraints (e.g., using only direct linear projections) results in diminished spatial tracking under viewpoint change.
Implications and Future Directions
The work positions high-dimensional, dense foundation model features as the new interface for controllable video diffusion, bridging the gap between classical low-level geometrical cues and semantic/appearance-rich guidance. In practical terms, this allows for unified pipelines supporting frame-accurate restyling, photorealistic 3D-aware rendering, and simulation-to-real domain transfer with minimal manual control specification.
From a theoretical standpoint, the results reinforce the role of self-supervised representation spaces as effective control signals, provided proper disentanglement from appearance is enforced via data augmentation and careful architecture-pathway design. The tradeoff between determinism and generation diversity remains a key consideration for downstream applications.
Anticipated directions include scaling to even larger vision foundation models, integrating real-time spatio-temporal feature selection, and extending to multi-modal conditioning (e.g., concatenation with language, audio, or physics priors). There is also clear value in further investigating adaptive masking and attention mechanisms for balancing guidance fidelity with generative exploration.
Conclusion
"Control-DINO: Feature Space Conditioning for Controllable Image-to-Video Diffusion" demonstrates that conditioned video diffusion on dense, high-dimensional DINO features enables robust, cross-domain, and temporally consistent generation under significant style, illumination, and domain shifts. The architecture sets a foundation for future work on unified video control interfaces, reducing reliance on modality-specific handcrafted signals and unlocking new applications in geometry-driven content generation, simulation, and editing (2604.01761).