- The paper presents a benchmark (Temper-5400) and teacher-student translation pipeline to assess LLM quantitative reasoning under emotional perturbations.
- It finds that emotional framing reduces LLM performance by 2–10%, with emotions like disgust causing an average 5.9% accuracy drop.
- Neutralizing emotional content recovers about 70% of lost accuracy, highlighting mechanisms that distract model attention and weaken constraint enforcement.
Quantitative Fragility of LLMs under Emotional Perturbation: Analysis of TEMPER
Background and Motivation
LLMs are predominantly trained and evaluated on benchmarks that are crafted in emotionally neutral language. However, user interactions in real-world settings frequently involve queries embedded with emotional tone—frustration, urgency, joy, or disgust—which can introduce stylistic, but not semantic, variation. The paper "TEMPER: Testing Emotional Perturbation in Quantitative Reasoning" (2604.07801) examines whether emotional linguistic framing degrades LLM quantitative reasoning, even when mathematical content is strictly preserved. The authors establish a controlled emotion translation protocol, constructing Temper-5400: a large, semantically rigorous benchmark for emotion-neutral pairs spanning diverse quantitative reasoning datasets and evaluate a broad suite of LLMs from 1B to frontier scale. Empirical and representational analyses are used to probe the underlying mechanisms of this fragility.
Emotion Translation Pipeline and Benchmark Construction
A teacher-student architecture is used to achieve content-preserving emotional paraphrasing. The "teacher" is a frozen DistilRoBERTa classifier trained on a domain-adapted emotion corpus, providing both categorical (7-class) and continuous (100-dim latent) supervision signals. The "student" is an Llama~3.1-8B-Instruct model fine-tuned for bidirectional translation between neutral and emotional variants, with auxiliary losses encouraging hidden-state alignment with the teacher's emotion manifold. The λ hyperparameter enables precise intensity control, balancing emotion expression against semantic fidelity.
Ensemble diversity is achieved by training five translator variants, differing in loss signal and weight but sharing the generator architecture. For each quantitative reasoning problem, emotional rewrites are selected from this pool with semantic filtering and multiple retries; neutralizations are performed without access to the original, serving as natural paraphrases. Temper-5400 comprises 5,400 verified emotion-neutral pairs (spanning GSM8K, MultiArith, ARC-Challenge), rigorously validated for mathematical equivalence.
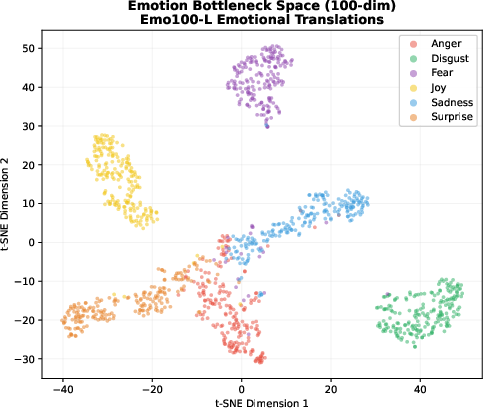
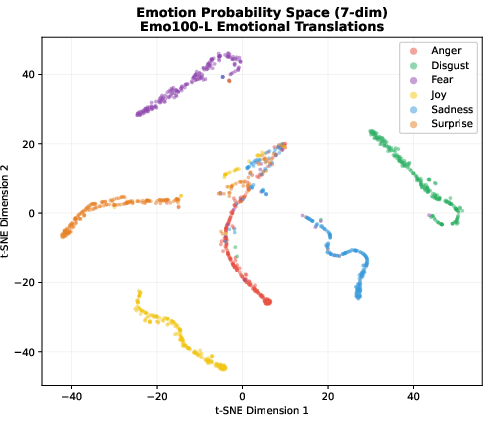
Figure 1: Compact, well-separated clusters in the 100-dim bottleneck space demonstrate the structured emotion manifold, capturing within-emotion variation and intensity gradients.
Across eighteen instruction-tuned models (1B–frontier scale), emotional framing induces a systematic drop in quantitative reasoning accuracy (2–10%), despite preservation of all numeric content and logical structure. Even at frontier scale (GPT-5.4, o3), accuracy degradation persists (≈2–3%), indicating that the effect is architectural-agnostic and not eliminated by scale. Recovery via neutralization (translation back to neutral tone) restores approximately 70% of lost accuracy, indicating that degradation is attributable to emotional style rather than content corruption.
The effect is robust against control conditions: length-matched, non-emotional paraphrases—generated with ten hard constraints on semantic preservation—do not cause systematic accuracy drop. This confirms that emotional content specifically, not verbosity or surface rewording, disrupts downstream reasoning.
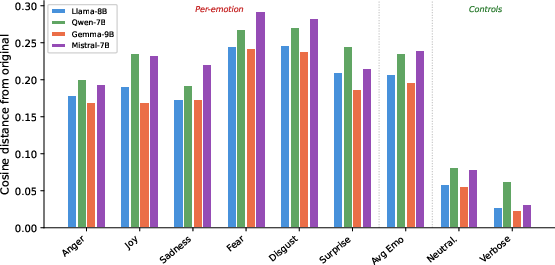
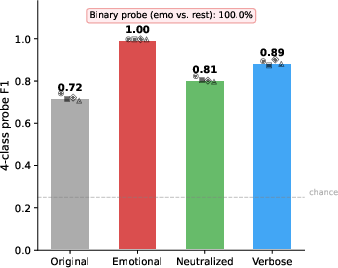
Figure 2: Cosine distance from original hidden representations; emotional text shifts model states 3–4× further than neutralized or paraphrased variants, consistent with representational interference.
Mechanistic Analysis and Failure Modes
Detailed chain-of-thought scrutiny using step-by-step model outputs, and qualitative labeling of emotional failures, reveals three dominant mechanisms:
- Constraint Degradation: Emotional elaboration softens or obscures mathematical constraints, leading to reinterpretation of the problem statement.
- Attention Competition: Emotional language distracts model attention from critical numerical elements, disrupting correct quantitative tracking.
- Premature Completion: Affect foregrounds the target answer, causing early termination of reasoning.
Disgust and fear cause the most pronounced degradation (mean 5.9% and 4.3%, respectively); joy and surprise are least disruptive (≈2% mean drop).
Latent Representation Dynamics
Extracted final-layer representations for original, emotional, neutralized, and non-emotional paraphrase variants show that emotional text produces structured, linearly separable hidden-state clusters. Cosine distances and linear probe results indicate that emotional variants occupy distinct regions in the latent space, coincident with degraded reasoning performance.
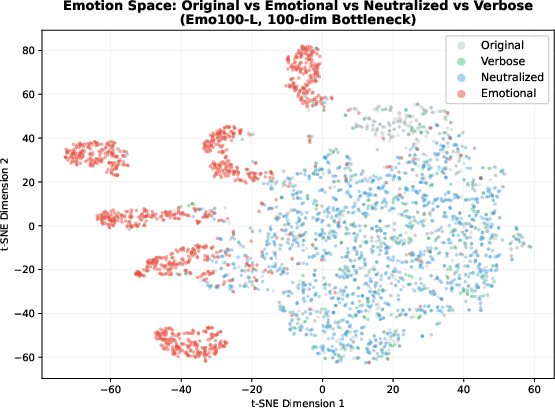
Figure 3: t-SNE in teacher's 100-dim bottleneck space; emotional translations (red) form well-separated clusters by emotion, while original, neutralized, and paraphrases overlap centrally.
Implications and Future Directions
The findings establish emotional framing as a distinct axis of LLM robustness, separate from structural or semantic perturbations. Standard benchmarks may overestimate reasoning performance by omitting emotional tone, highlighting a gap between benchmark and deployment settings. The teacher-student translation framework is generalizable to other stylistic attributes (formality, sarcasm, domain-specific jargon) for isolating robustness dimensions.
Practically, emotion-neutralization can serve as an inference-time mitigation strategy. At the frontier scale, the effect approaches the noise floor, yet is nonzero. The analysis suggests necessitating inclusion of emotional perturbations in future robustness evaluations and benchmark design.
Opportunities for further work include localizing representational interference (layer- and head-wise), expanding emotional taxonomy granularity, integrating with technical domains exhibiting emotional register, and designing higher-fidelity neutralization pipelines.
Conclusion
This study introduces a controlled, generalizable framework and quantitative benchmark for evaluating the impact of emotional framing on LLM quantitative reasoning. Empirical findings establish consistent, magnitude-scaled accuracy degradation tied to emotional style, which is partially recoverable by neutralization. Latent representation analyses corroborate structured interference in hidden states. The work motivates future research into mitigation, domain generalization, and broader stylistic robustness testing for LLMs in deployment scenarios.

