- The paper reveals that emotional framing significantly biases GPT-4 outputs, with negative prompts yielding only about 14% negative responses.
- The study employs systematic techniques including sentiment classification, transition matrices, and Frobenius distances to quantify tonal shifts.
- The research highlights the impact of safety alignment in suppressing tone effects, especially for sensitive subjects and controversial topics.
ChatGPT Reads Your Tone and Responds Accordingly: Emotional Framing Induces Bias in LLM Outputs
Introduction
Research into the behavior of LLMs like GPT-4 has demonstrated sensitivity not just to the semantic content of prompts but also to their emotional tone. This study examines how emotional framing, whether optimistic, neutral, or frustrated, systematically biases LLM outputs. The underlying objective is to identify the extent to which emotional tone can skew LLM responses and to understand the role of safety alignment in mitigating such effects.
Methods
To investigate the impact of emotional tone, 52 base questions were rephrased into 156 triplet prompts expressing neutral, positive, and negative tones. GPT-4's responses to these prompts were analyzed for sentiment using high-confidence sentiment classification and self-evaluation. The methods encapsulate a systematic approach to measuring tone-induced shifts, utilizing transition matrices and Frobenius distances to quantify these changes across both everyday and sensitive topics.
Results
Analysis of GPT-4's responses revealed two significant patterns: an "emotional rebound" effect where negatively phrased prompts seldom resulted in negative responses, and a "tone floor" where positive or neutral prompts rarely yielded negative replies. Specifically, only about 14% of responses to negative prompts maintained a negative valence, with the majority shifting to neutral (58%) or positive (28%) valences (Figure 1).
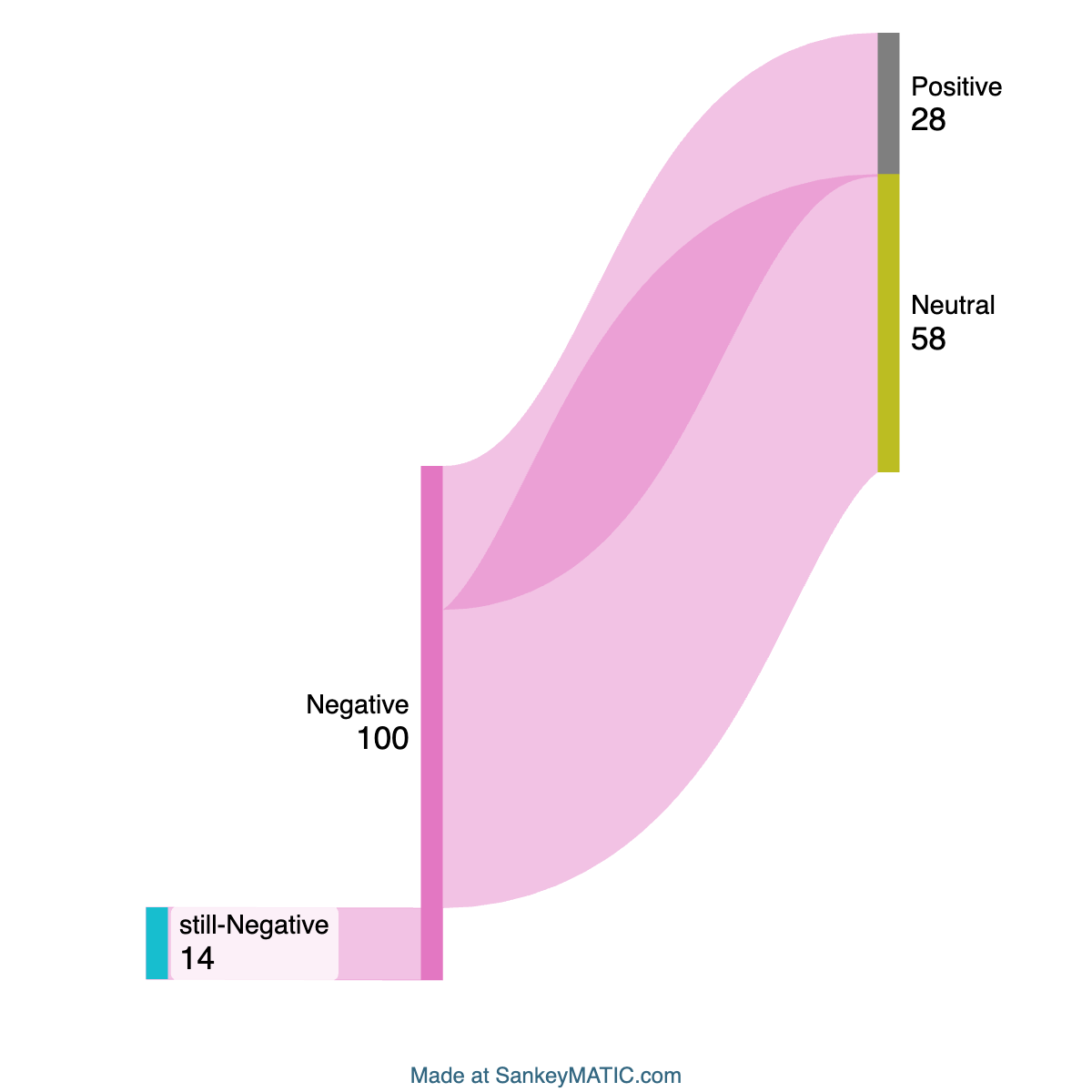
Figure 1: Response valence for negatively phrased prompts.
In contrast, when examining responses to neutrally phrased prompts, the distribution showed a similar propensity towards neutrality and positivity, with negligible negative responses (Figure 2).
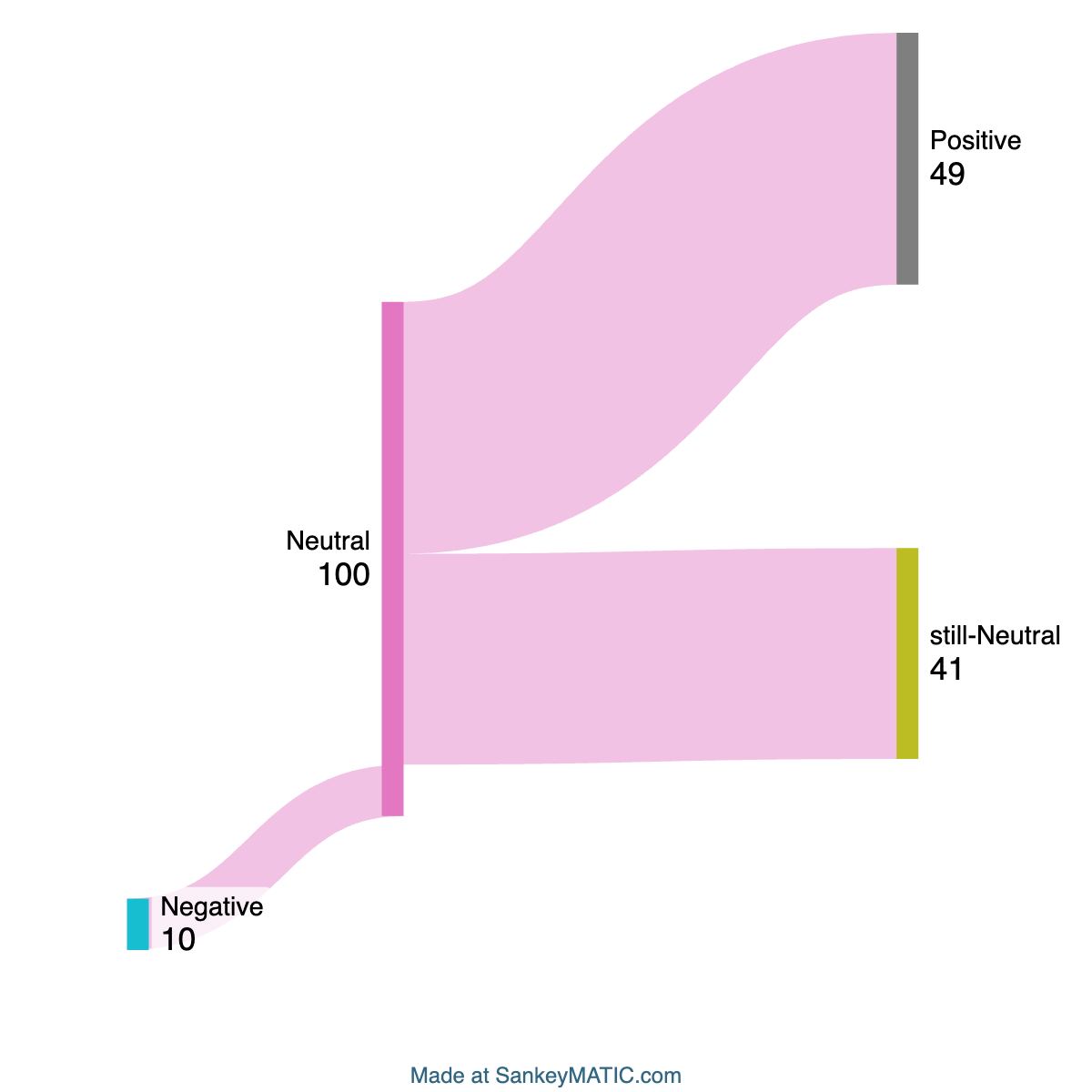
Figure 2: Response valence for neutrally phrased prompts.
These response patterns underscore a systematic bias towards positive and neutral tones, revealing an ingrained reluctance within GPT-4 to generate negative output unless explicitly prompted.
Tone Suppression in Sensitive Topics
When prompts addressed sensitive topics—defined as those likely to trigger alignment filters—response tone exhibited remarkable consistency, regardless of the input's emotional framing. This phenomenon suggests that alignment mechanisms within GPT-4 are more robust in these contexts, actively suppressing tone effects to maintain neutrality.
This assertion is further supported by the Frobenius distance analysis, which quantifies the model's tonal sensitivity. The minimized distances in sensitive topics underscore a strategic override, where emotional modulation is subdued in favor of alignment stability.
Representation Analysis
The study employed PCA and UMAP to visualize shifts in sentence-level embeddings across different tones, revealing partial separation of sentiment classes in response embeddings (Figure 3). The visualization indicates that positive and neutral responses, despite some overlap, generally form distinct clusters, whereas negative responses are more dispersed, reflecting the model's aversion to negativity.
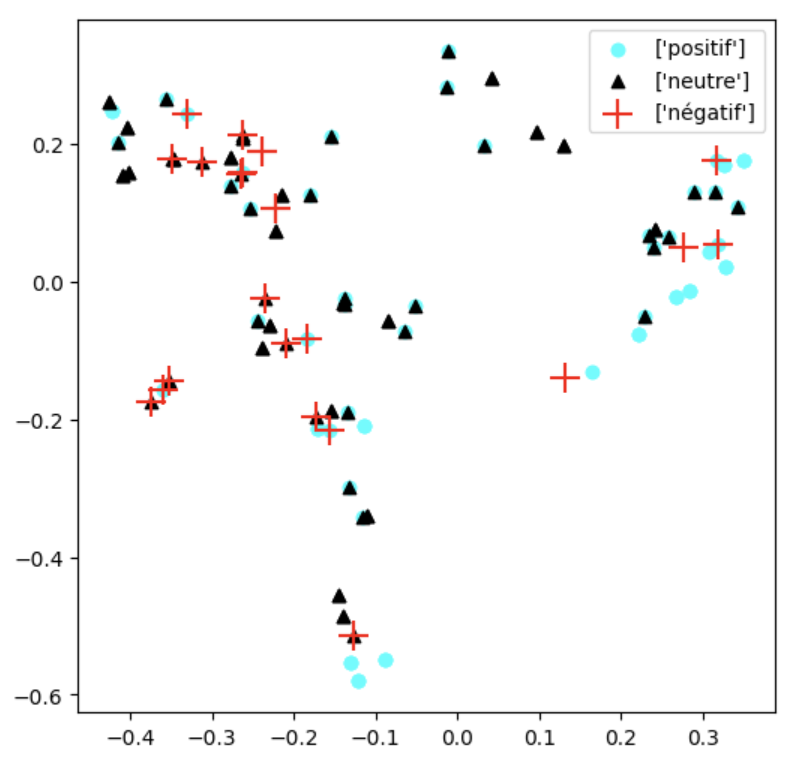
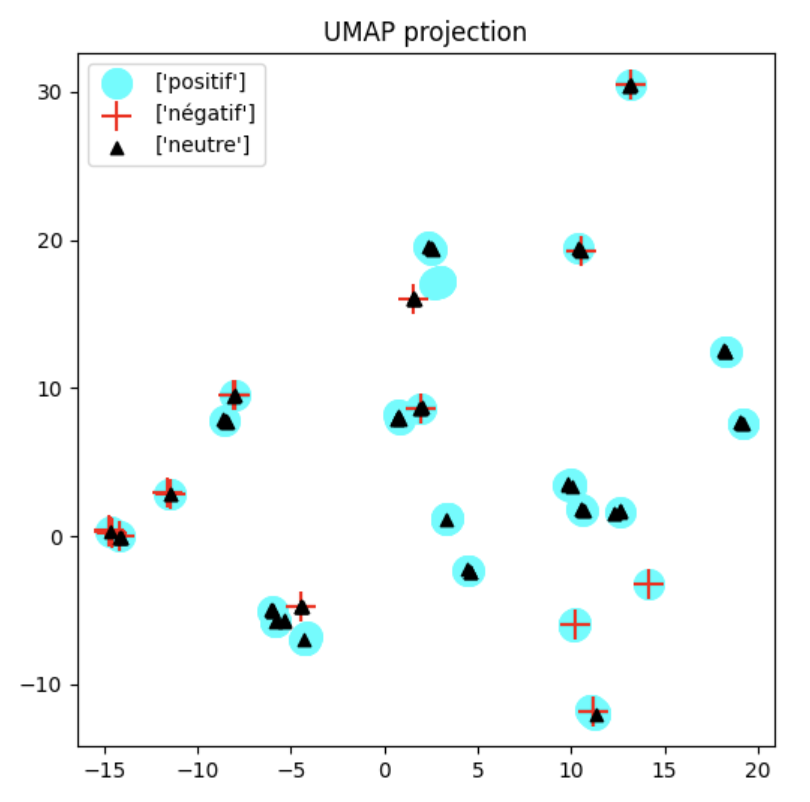
Figure 3: PCA (left) and UMAP (right) projections of response embeddings by model-evaluated tone. Colors and markers represent positive (cyan), neutral (black), and negative (red) valence labels.
Additionally, restricted UMAP projections show that in controversial topics, negative responses are less isolated, aligning more closely with neutral or positive clusters (Figure 4).
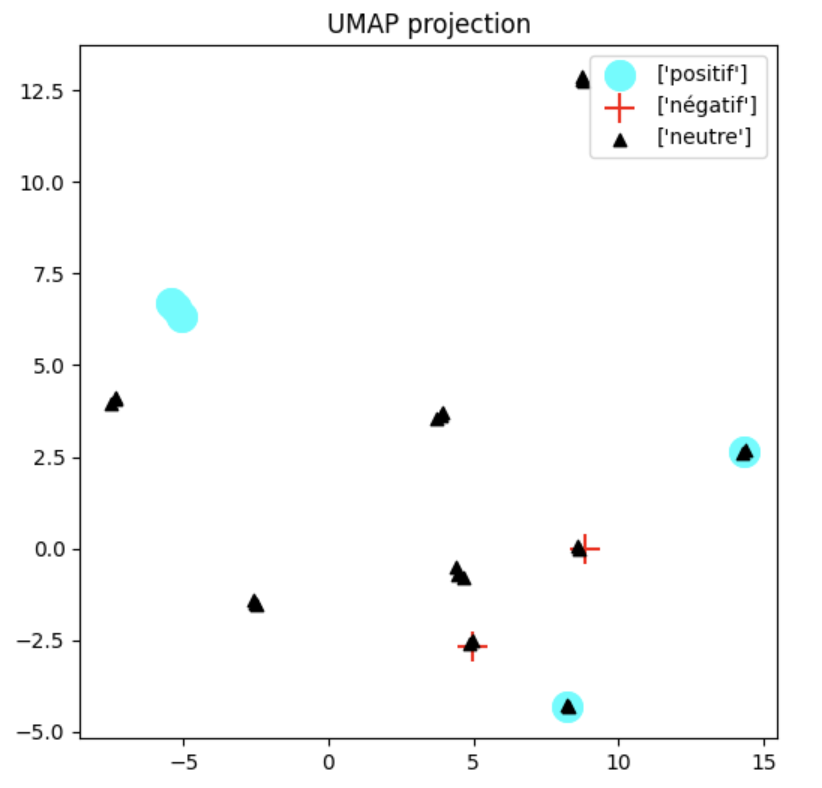
Figure 4: UMAP projection restricted to controversial topics only. Negatives are less isolated and tend to appear embedded in neutral/positive clusters.
Discussion
These findings point to an intrinsic emotional bias in GPT-4, shaped by emotional tone. The presence of emotional rebound and tone floor behaviors suggest a nuanced response strategy that LLMs adopt, potentially influenced by Reinforcement Learning from Human Feedback (RLHF). This learning may encourage emotionally positive or neutral outputs when user prompts carry negative or emotional undertones.
The study also raises critical considerations for AI alignment. Tone modulation or the lack thereof could influence the perceived objectivity and fairness of model responses, especially when used in decision-making environments.
Conclusion
This research highlights how emotional framing systematically influences LLM outputs, introducing biases tied to user prompt tone. While such traits may enhance user interaction by emitting reassuring and neutral tones, they pose a risk to the objectivity and consistency vital for informative and decision-support contexts. Future work should focus on transparency mechanisms and controls to mitigate these biases and align LLM behavior to the needs of diverse applications. Understanding and adjusting these hidden emotional dynamics are crucial for advancing the interpretability and reliability of LLMs.
The complete dataset and code base are publicly available for further exploration and reproducibility, providing the means to explore understanding and controlling tone-driven behaviors in LLMs.

