Cog-DRIFT: Exploration on Adaptively Reformulated Instances Enables Learning from Hard Reasoning Problems
Abstract: Reinforcement learning from verifiable rewards (RLVR) has improved the reasoning abilities of LLMs, yet a fundamental limitation remains: models cannot learn from problems that are too difficult to solve under their current policy, as these yield no meaningful reward signal. We propose a simple yet effective solution based on task reformulation. We transform challenging open-ended problems into cognitively simpler variants -- such as multiple-choice and cloze formats -- that preserve the original answer while reducing the effective search space and providing denser learning signals. These reformulations span a spectrum from discriminative to generative tasks, which we exploit to bootstrap learning: models first learn from structured, easier formats, and this knowledge transfers back to improve performance on the original open-ended problems. Building on this insight, we introduce Cog-DRIFT, a framework that constructs reformulated variants and organizes them into an adaptive curriculum based on difficulty. Training progresses from easier to harder formats, enabling the model to learn from problems that previously yielded zero signal under standard RL post-training. Cog-DRIFT not only improves on the originally unsolvable hard problems (absolute +10.11% for Qwen and +8.64% for Llama) but also generalizes well to other held-out datasets. Across 2 models and 6 reasoning benchmarks, our method consistently outperforms standard GRPO and strong guided-exploration baselines. On average, Cog-DRIFT shows +4.72% (Qwen) and +3.23% (Llama) improvements over the second-best baseline. We further show that Cog-DRIFT improves pass@k at test time, and the curriculum improves sample efficiency. Overall, our results highlight task reformulation and curriculum learning as an effective paradigm for overcoming the exploration barrier in LLM post-training.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about? (Big idea)
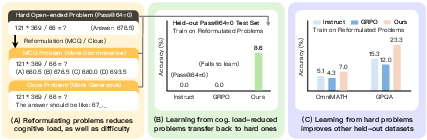
This paper shows a new way to teach AI LLMs to solve really hard reasoning problems (like tough math questions). When a problem is too hard, the model often guesses wrong every time and gets no useful feedback, so it can’t learn. The authors fix this by rewriting hard questions into easier formats—like multiple-choice or fill‑in‑the‑blank—while keeping the same correct answer. Then, as the model improves, they slowly switch back to the original, open-ended format. They call this approach Cog-DRIFT.
What questions are the researchers trying to answer?
They’re asking:
- How can we help a model learn from problems that are currently too hard for it to solve?
- If we temporarily make a hard problem easier (without changing the correct answer), will learning from that easier version help the model do better on the original hard version?
- Is it better to teach in stages (from easier to harder), like levels in a game, rather than all at once?
How did they do it? (Methods in simple terms)
Think of solving a tough puzzle in three ways:
- Open-ended: you must produce the full solution from scratch.
- Multiple-choice: you pick the right answer from a few options.
- Fill-in-the-blank (cloze): part of the answer is shown, and you complete it.
The open-ended version is like finding your way through a giant maze with no hints. Multiple-choice shrinks the maze by showing a small set of doors; fill‑in‑the‑blank gives you partial guideposts. The authors:
- Reformulated each hard question into several easier versions:
- 4-choice multiple-choice (easiest),
- 10-choice multiple-choice,
- fill‑in‑the‑blank,
- and the original open-ended format (hardest).
- Kept the correct answer exactly the same in every version, so they could automatically check if the model was right (this is “verifiable rewards”).
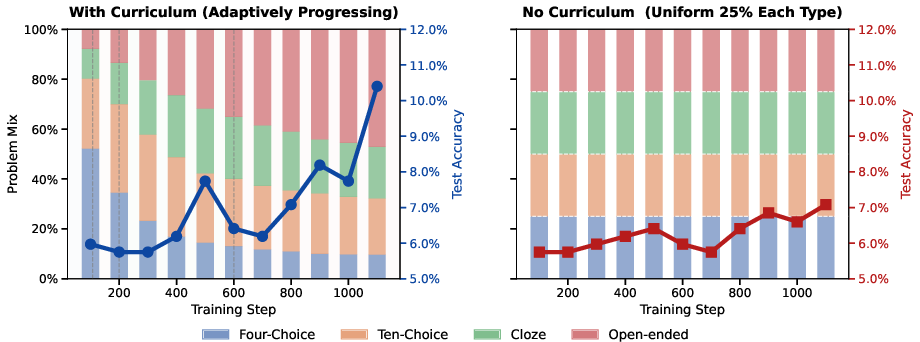
- Gave the model an “adaptive curriculum,” like moving up game levels:
- Start training on the easiest format.
- When the model is getting half or more correct, move that problem to the next harder format.
- Repeat until it’s solving the original open-ended version.
They trained with a reinforcement learning method (GRPO) that rewards outputs more when they’re closer to correct and in the right format. They tested on several challenging benchmarks (like AIME math problems and GPQA) and checked both pass@1 (gets it right on the first try) and pass@k (gets it right at least once if you let it try k times).
What did they find, and why does it matter?
Main takeaways:
- Easier formats unlock learning: When the model saw multiple-choice or fill‑in‑the‑blank versions, it finally got useful feedback and started improving—even on problems it previously never solved.
- Learning transfers back: After practicing on the easier versions, the model did better on the original open-ended questions. In other words, practice with scaffolding helped on the “real” task.
- Bigger, consistent gains: Across two different models (Qwen and Llama) and six tough benchmarks, their method beat standard training methods. On the hardest set (where models originally never got any right in 64 tries), accuracy jumped by roughly 9–10 percentage points.
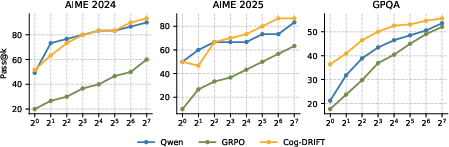
- Better pass@k: Not only did first-try accuracy improve, but the chance of getting a correct answer within a few tries also went up. That suggests the model actually learned new reasoning patterns, not just how to guess better once.
- Variety helps: Mixing multiple reformulations (e.g., both multiple-choice and fill‑in‑the‑blank) worked better than using just one. Diversity of practice made transfer to open-ended questions stronger.
- Curriculum saves effort: The “level up when ready” strategy used data more efficiently and kept progress going, instead of plateauing.
Why this matters: A common problem in training is that very hard questions give zero feedback when the model fails, so it can’t get better. By reformulating tasks and using an adaptive curriculum, the model learns from problems it previously couldn’t learn from at all.
What’s the bigger impact?
- Better teaching for AI: This mirrors how humans learn—start with structured help, then gradually remove support. It gives a practical recipe to help models improve reasoning without needing expensive human labels or a stronger “teacher” model.
- General and scalable: The idea of reformulating tasks and building an adaptive curriculum can apply beyond math—to code, science, and other reasoning-heavy jobs—where answers can be checked automatically.
- Stronger, more reliable reasoning: Because improvements show up even when you let the model try multiple times (higher pass@k), this suggests real skill growth, not just lucky guesses.
In short, Cog-DRIFT shows that carefully rewriting and staging hard problems turns “too hard to learn from” into “learnable,” leading to smarter and more dependable AI reasoning.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved by the paper; each item highlights a specific missing piece or uncertainty that future work could directly address.
- Scope beyond verifiable math: How well does Cog-DRIFT transfer to unverifiable or weakly verifiable domains (e.g., open QA, long-form reasoning, planning, safety critique) where binary outcome rewards are unavailable?
- Generality across modalities and tasks: Does the reformulation-curriculum approach extend to code generation (e.g., unit-test–based verifiers), multimodal reasoning, or scientific tasks beyond GPQA where answers may be symbolic, structured, or multi-part?
- Reformulation generator bias: Reformulations are produced by a specific LLM (Qwen-4B); how sensitive are outcomes to the choice, size, and prompting of the reformulation generator, and what happens if the learner and reformulator are the same or different models?
- Distractor quality and adversarial design: MCQ distractors are only validated for uniqueness of the correct option, not for plausibility or similarity to the gold answer; how does distractor difficulty/quality affect learning and transfer?
- Cloze mask policy: How do different cloze-masking strategies (pattern, length, position of revealed digits/tokens) impact cognitive load reduction, learning dynamics, and transfer back to open-ended formats?
- Ordering of difficulty levels: The empirical ordering MCQ4 → MCQ10 → Cloze → OEQ is assumed; under what conditions (task type, model size, prompt style) does this ordering hold or break, and can it be learned automatically?
- Curriculum thresholds and stability: The instance-level promotion rule uses a fixed accuracy threshold τ=0.5 and m samples; what is the sensitivity to τ and m, and are there more statistically robust or adaptive promotion criteria?
- Reward design choices: Rewards only consider final correctness and a small format bonus; could richer signals (step-level verifiers, unit tests, partial-credit grading, constraint checks) yield better transfer and stability?
- Algorithmic choices and alternatives: GRPO is used as the RL algorithm; how does Cog-DRIFT perform under alternative objectives (PPO, AWR/AWAC, entropy-regularized RL, off-policy RL with replay, variance-reduction techniques)?
- Compute and sample efficiency accounting: The paper argues improved sample efficiency via curriculum but does not quantify total compute (reformulation generation, per-instance promotions, rollouts) relative to baselines; what is the wall-clock and token-level cost-benefit?
- Robustness to noisy reformulations: Despite deterministic checks, reformulations may contain subtle errors (misleading wording, formatting artifacts); how robust is training to such noise, and can uncertainty-aware or verifier-in-the-loop filtering improve reliability?
- Leakage and shortcut risks: Cloze hints may expose too much of the answer, enabling shortcut solutions; what masking strategies minimize leakage while still reducing cognitive load, and how to detect and prevent shortcut learning?
- Transfer failure modes: Which problem types (e.g., combinatorics vs geometry, multi-step algebra vs numeric) fail to benefit from reformulations or curriculum, and why? Can per-category curricula be tailored to mitigate failures?
- Hardness definition and selection bias: pass@64=0 is used to define “hard”; how do results change with different k, temperature, decoding strategies, or models used to label hardness, and can hardness be estimated without large rollouts?
- Data quality filtering dependence: The “Silver Answer Filter” uses GPT-5.4 majority voting to filter noisy items; how sensitive are outcomes to the choice and strength of this filter, and how to avoid potential data leakage or hidden supervision biases?
- Cross-model fairness and transfer: Hard problems are selected using Qwen, then applied to Llama; does this introduce cross-model selection bias, and would selecting hard items per target model yield different outcomes?
- Scale-up to larger models and stronger baselines: Results are on 3–4B instruct models; does Cog-DRIFT retain gains for larger, more capable LLMs (7B–70B+), and against stronger RLVR baselines or expert-guided methods (e.g., POPE with large teachers)?
- Pass@k improvements characterization: The paper shows pass@k gains on selected benchmarks; what is the statistical significance across more seeds/datasets, and how do improvements distribute across easy vs hard subsets within benchmarks?
- Long-term generalization and forgetting: Does training on reformulations cause any degradation on tasks requiring unconstrained generative behavior (e.g., free-form proofs, explanations), and does the model overfit to boxed-answer formatting?
- Multilingual and domain-shift robustness: How does the approach fare on multilingual math/logic datasets or under domain shifts (different curricula, different distributions of problem types and solution styles)?
- Alternative reformulations: Beyond MCQ and cloze, what is the impact of other structured formats (e.g., step-skeletons, program sketches, equation templates, fill-in reasoning steps) on transfer and generalization?
- Global vs instance-level curricula: The paper adopts per-instance promotion; how does this compare to global difficulty schedules, population-based curricula, or bandit-style allocation of formats across the dataset?
- Mechanistic understanding of transfer: Why does diversity of reformulations improve transfer to open-ended tasks? Can causally grounded or representation-level analyses reveal how discriminative-to-generative transitions reshape internal computations?
- Interactions with chain-of-thought quality: RL rewards target final answers; how do reformulations affect the correctness, completeness, and faithfulness of intermediate reasoning steps, and can step-level verification improve both learning and interpretability?
- Safety and broader impacts: Does reducing cognitive demand encourage overconfidence or brittle behavior when hints are absent? What are the safety implications of training models to rely on structured cues that may not appear at test time?
Practical Applications
Below is an overview of real-world applications enabled by Cog-DRIFT’s findings, methods, and innovations. Cog-DRIFT reformulates hard, open-ended problems into cognitively simpler, answer-preserving variants (e.g., multi‑choice, cloze) and trains models with an adaptive, instance‑level curriculum. This yields stronger learning signals in RL with verifiable rewards (RLVR), better generalization, and improved pass@k—without relying on stronger teachers.
Immediate Applications
- Education (adaptive tutoring and assessment)
- Use case: Build tutoring systems that scaffold student learning by dynamically transitioning question formats (4‑choice → 10‑choice → cloze → open‑ended) based on per‑student accuracy, mirroring the paper’s instance‑level curriculum.
- Tools/products/workflows: “Curriculum engine” that reformulates items, verifies answer uniqueness, and auto‑promotes difficulty when students exceed a threshold; analytics dashboard to track format‑level mastery.
- Assumptions/dependencies: Answer verifiability (e.g., math, vocabulary); high‑quality distractors for MCQs; alignment of platform content with licensing/pedagogy.
- Software and AI Engineering (LLM training pipelines for reasoning)
- Use case: Integrate Cog-DRIFT into RLVR training for math, code, and other verifiable tasks to unlock learning from hard problems (pass@64=0) and improve sample efficiency.
- Tools/products/workflows: A “reformulation service” that generates and validates MCQ/cloze variants; an “instance‑level curriculum scheduler” (threshold τ, per‑instance level tracking); reward verifiers (correctness + format); plug-ins for vLLM/verl/TRL-like stacks.
- Assumptions/dependencies: Deterministic verifiers (e.g., unit tests, math checkers); compute budget for group sampling; care to avoid shortcut learning (require full answers, not option letters).
- Software (code assistants with verifiable rewards)
- Use case: For code generation, convert difficult, open‑ended tasks into structured variants (e.g., masked code spans, restricted API choices) to provide denser RL signals, then escalate to full solutions.
- Tools/products/workflows: Unit-test backed verifiers; masked‑completion tasks; per‑instance difficulty tracking in CI pipelines; pass@k monitoring by difficulty tier.
- Assumptions/dependencies: Rich, reliable test suites; answer preservation between variants; clean handling of partial credit and format compliance.
- Finance and Compliance (verifiable QA training)
- Use case: Train models to reason about regulatory rules, financial math, and policy checks by reformulating hard compliance/Q&A items into MCQ/cloze forms with answer-preserving structure.
- Tools/products/workflows: Compliance QA banks auto‑converted to MCQ/cloze; verifiers for numeric/logical outcomes (e.g., threshold checks, formula validation); curriculum‑based fine‑tuning workflows.
- Assumptions/dependencies: Clearly verifiable answers (numeric, boolean, single‑label); validated distractors and gold labels; governance for data provenance.
- Healthcare (clinical calculations and protocol QA)
- Use case: Improve reasoning on dosage calculations, risk scores, and guideline logic by training with MCQ/cloze variants before open‑ended generation (e.g., clinician‑facing assistants).
- Tools/products/workflows: Libraries of validated clinical calculation items; verifiers for numeric outputs; safe formatting rules for final answers.
- Assumptions/dependencies: Medical domain experts to curate/verify answers; strict QA to prevent unsafe suggestions; deployment under regulatory and privacy constraints.
- Data Curation and Benchmarking (quality filters and “hard” sets)
- Use case: Adopt the paper’s filtering strategy (e.g., “silver answer” filtering via a stronger solver and deterministic verifiers) to prune unsolvable or mislabeled items from “hard” datasets.
- Tools/products/workflows: Filtering pipelines (oracle solver majority vote, solvability checks), MCQ uniqueness checks, cloze mask validity tests, Math-Verify-like tools generalized to domain.
- Assumptions/dependencies: Access to a reliable “oracle” or ensemble solver for filtering; domain-specific verifiers; awareness of potential selection bias when using pass@k to define difficulty.
- Model Evaluation and Ops (pass@k and curriculum analytics)
- Use case: Embed pass@k tracking by difficulty tier and curriculum stage into MLOps dashboards to detect whether training is unlocking new capabilities or just sharpening pass@1.
- Tools/products/workflows: Metrics pipelines for pass@k(1..128); per‑instance level progression logs; alarms for plateauing levels; ablation tracking for reformulation mixtures.
- Assumptions/dependencies: Consistent sampling budgets; reproducible evaluation harnesses; budget-aware comparison of pass@k.
Long-Term Applications
- Generalization to Unverifiable or Partially Verifiable Domains
- Use case: Extend reformulation to complex domains (e.g., open‑ended QA, scientific reasoning, long-form analysis) by constructing surrogate verifiers (e.g., rubric‑based or retrieval‑based checks) or by transforming tasks into multiple constrained sub-questions.
- Tools/products/workflows: Rubric/verifier design frameworks; reference‑grounded checking (retrieval + entailment); structured decomposition into verifiable subproblems.
- Assumptions/dependencies: Robust, domain-specific verifiers; careful handling of multiple valid answers; potential need for human-in-the-loop evaluation.
- Robotics and Planning (structured plan reformulation)
- Use case: Reformulate hard planning tasks into skeleton/option‑based choices (e.g., select next action from candidates, fill missing steps) before escalating to free-form plans with verifiable rollouts or simulators.
- Tools/products/workflows: Simulator-backed verifiers; action‑space MCQs; cloze‑style plan templates; curriculum‑aware training interfaces for embodied agents.
- Assumptions/dependencies: High-fidelity simulators or reliable environment checkers; methods to ensure answer preservation from simplified plans to executable policies.
- Energy and Operations Research (optimization with verifiable objectives)
- Use case: Apply curriculum reformulation to scheduling, dispatch, or routing tasks by first training on structured subproblems (candidate comparisons, masked solutions) and promoting to open‑ended optimization outputs verified by solvers.
- Tools/products/workflows: Solver-backed correctness checks (feasibility/optimality thresholds); candidate list generation; masked-solution templates; curriculum schedulers integrated with OR pipelines.
- Assumptions/dependencies: Access to solvers/evaluators; clear objective functions; computational overhead for verification.
- Test-Time Adaptation and Interactive Scaffolding
- Use case: At inference, detect struggle on hard prompts and on-the-fly present simplified reformulations to elicit correct answers (or reasoning traces), then map back to open-ended outputs.
- Tools/products/workflows: Difficulty estimators; fallback reformulation loops; answer‑preserving mapping from simplified responses to final outputs; confidence-based gating.
- Assumptions/dependencies: Real-time verifiers; latency budget; safeguards to avoid user confusion and ensure transparency.
- Auto-Discovery of Reformulation Spaces and Curricula
- Use case: Move beyond MCQ/cloze to discover task-specific simplifications and automatically tune curriculum thresholds, group sizes, and format mixes for maximal transfer and sample efficiency.
- Tools/products/workflows: Meta-learning over reformulation types; Bayesian optimization of curricula; automated distractor generation with uniqueness proofs; policy‑aware difficulty estimation.
- Assumptions/dependencies: Reliable signals to rank difficulty; robust detection of shortcut exploitation; compute for large-scale curriculum search.
- Sector-Scale “Curriculum RLVR” Platforms
- Use case: Offer managed services that provide reformulation generation, verification, and instance-level curricula for enterprise LLM training across verticals (healthcare, finance, education, software).
- Tools/products/workflows: APIs for reformulation, verifier catalogs, curriculum orchestration, audit logs for data quality and model progression; compliance-ready deployment.
- Assumptions/dependencies: Standardized verifiers per domain; governance for data and model updates; clear SLAs around correctness and safety.
- Policy and Standards
- Use case: Inform guidelines for training/evaluating AI systems with verifiable rewards and curricula, including best practices for dataset filtering, answer preservation, and reporting pass@k beyond pass@1.
- Tools/products/workflows: Benchmarks of “hard” problems with verified labels; documentation standards for curricula and verifier design; procurement criteria for public-sector AI using scaffolding.
- Assumptions/dependencies: Consensus on verification methodologies; transparency requirements; sector-specific ethical and safety constraints.
- Cross-Modal Reasoning (vision-language, multimodal science)
- Use case: Create verifiable reformulations for multimodal tasks (e.g., selecting correct diagram interpretation from options, filling masked numeric labels), then escalate to open-ended multimodal explanations.
- Tools/products/workflows: Multimodal verifiers (e.g., synthetic data generators, differentiable renderers, unit-test-like visual checks); curriculum engines that track multimodal difficulty.
- Assumptions/dependencies: Reliable multimodal checking; careful control of data leakage and spurious correlations.
Notes on feasibility across all applications:
- The method’s effectiveness depends on answer verifiability and high-quality reformulations that genuinely reduce search space while preserving answers.
- Multiple reformulations (e.g., MCQ + cloze) and adaptive, instance-level curricula drive transfer and sample efficiency—single-format training is less effective.
- Data quality matters: “hard” sets defined by pass@k can include flawed items; filtering (oracle solver agreement, solvability checks) improves outcomes, especially for sensitive models.
- Compute and engineering overheads arise from generating/validating reformulations and running curricula; curricula mitigate some costs by focusing sampling where learning occurs.
Glossary
- Advantage estimates: In policy-gradient RL, an estimate of how much better a sampled trajectory is than a baseline; zero variance implies no learning signal. "leading to zero variance in the advantage estimates."
- Adaptive curriculum: A training schedule that automatically advances example difficulty based on performance. "organizes them into an adaptive curriculum based on difficulty."
- Chain-of-thought: Step-by-step natural language reasoning traces used during training or prompting. "correct chain-of-thought \citep{wei2022chain} reasoning trajectories"
- Cloze: A fill-in-the-blank format where parts of the answer are masked to reduce generation difficulty. "fill-in-the-blank (cloze) tasks"
- Cognitive load: The mental effort required to process a task; lowering it can make learning easier. "have been used to reduce cognitive load and scaffold learning"
- Cognitive scaffolding: Structuring tasks or support to help learners tackle just-beyond-capability problems. "cognitive scaffolding approaches in human education."
- Deterministic verifiers: Rule-based checks that deterministically assess correctness (e.g., exact answer match). "By employing deterministic verifiers (e.g., binary rewards based on final answer correctness)"
- Discriminative tasks: Tasks framed as selection or ranking among options rather than free-form generation. "MCQs are more discriminative, turning the task into one of ranking or selection."
- Distribution sharpening: The idea that RL may amplify already likely high-reward behaviors rather than discover new ones. "or primarily performs "distribution sharpening" by amplifying high-reward paths already present in the model's latent space"
- Entropy-reward trade-off: Balancing exploration (entropy) and exploitation (reward) to avoid premature convergence in RL. "by balancing the entropy-reward trade-off to prevent premature convergence"
- Format compliance: Rewarding outputs that follow required answer formatting, independent of correctness. "Our reward function combines correctness and format compliance:"
- Group Relative Policy Optimization (GRPO): An RL algorithm that normalizes rewards within sampled groups to guide updates. "Group Relative Policy Optimization (GRPO)"
- Grokking: Sudden generalization after extended training, often discussed in reasoning/algorithm-learning contexts. "propose a ``grokking'' recipe for RLVR"
- In-context learning: Learning from examples provided in the prompt without parameter updates. "8 in-context learning samples."
- Instance-level curriculum: A curriculum where each example advances in difficulty based on its own measured accuracy. "an instance-level curriculum that progressively scales problem difficulty"
- Multiple-choice questions (MCQ): Problems presented with answer options, constraining the output space and easing search. "multiple-choice (MCQs)"
- Offline trajectories: Pre-collected sequences (e.g., from stronger models) used to supply learning signals without on-policy generation. "leverage privileged information or offline trajectories to provide a learning signal"
- On-policy sampling: Generating training data using the current policy; can fail on very hard problems due to sparse rewards. "on-policy sampling fails to discover any correct solutions"
- Open-ended questions (OEQ): Problems requiring unconstrained free-form answers rather than choosing among options. "open-ended questions (OEQ)"
- Outcome correctness: Rewarding the final answer’s exact correctness, irrespective of the reasoning process. "using outcome correctness as the reward"
- Pass@k: The probability that at least one of k sampled answers is correct; used to gauge solvability under sampling. "Here, we define ``difficult'' as pass@64=0"
- Privileged On-Policy Exploration (POPE): A method that uses stronger-model prefixes to guide exploration into reward regions. "such as POPE, which uses offline prefixes from a stronger model to guide exploration"
- Proximal Policy Optimization (PPO): A widely used policy-gradient RL algorithm with clipped objectives for stable training. "algorithms such as PPO \citep{schulman2017proximal} and GRPO"
- Rejection Fine-Tuning (RFT): Fine-tuning on successful trajectories selected by rejecting incorrect ones to improve reasoning. "Rejection sampling Fine-Tuning (RFT):"
- Reinforcement Learning with Verifiable Rewards (RLVR): RL setup where rewards come from objective verifiers (e.g., exact answer checks). "Reinforcement Learning with Verifiable Rewards (RLVR)."
- Rollout budget: The cap on the number of sampled trajectories per problem during training or evaluation. "RLVR operates under a rollout budget"
- Rollout-based objectives: RL objectives that rely on sampled trajectories from the current policy to compute rewards/updates. "with rollout-based objectives (e.g., GRPO)"
- Sample efficiency: How effectively a method learns from limited data or rollouts. "the curriculum improves sample efficiency."
- Sparse-reward environments: Settings where correct signals are rare, making learning difficult without additional guidance. "sparse-reward environments"
- Stochastic exploration: Randomness in sampling actions/outputs that can occasionally discover correct solutions. "arising from stochastic exploration"
- Supervised fine-tuning (SFT): Parameter updates using labeled pairs (e.g., problem–solution) via supervised learning. "perform supervised fine-tuning (SFT)"
- Task reformulation: Rewriting problems into alternative formats (e.g., MCQ, cloze) that preserve answers but reduce difficulty. "We instead propose task reformulation as a practical solution."
- Zone of Proximal Development (ZPD): The range of tasks just beyond current ability where learning is maximized with support. "the Zone of Proximal Development"
Collections
Sign up for free to add this paper to one or more collections.