- The paper introduces a hierarchical multi-agent orchestration framework that bridges LLM-driven intent with scalable HPC execution.
- It demonstrates high-throughput screening of 2,304 MOFs by decomposing tasks into planner and executor roles using asynchronous tool calls.
- The approach achieves near-linear speedup and adaptable multi-objective workflows, ensuring robust traceability and reproducibility.
Multi-Agent Orchestration for High-Throughput Materials Screening on Leadership-Class HPC
Architectural Innovations for Scalable Scientific Automation
The paper presents a hierarchical multi-agent orchestration framework designed to bridge the gap between LLM-driven intent and scalable execution on leadership-class HPC systems. The central innovation is a planner–executor paradigm, wherein a planner agent dynamically decomposes scientific objectives into structured tasks, while a fleet of executor agents asynchronously execute these tasks using tool calls routed via the Model Context Protocol (MCP) and Parsl workflow engine. The architecture is modular, allowing the planner agent to adaptively allocate workloads and the executors to concurrently invoke ensemble simulations across compute nodes. This separation of concerns enables robust scaling, traceability, and adaptability for complex scientific workflows.
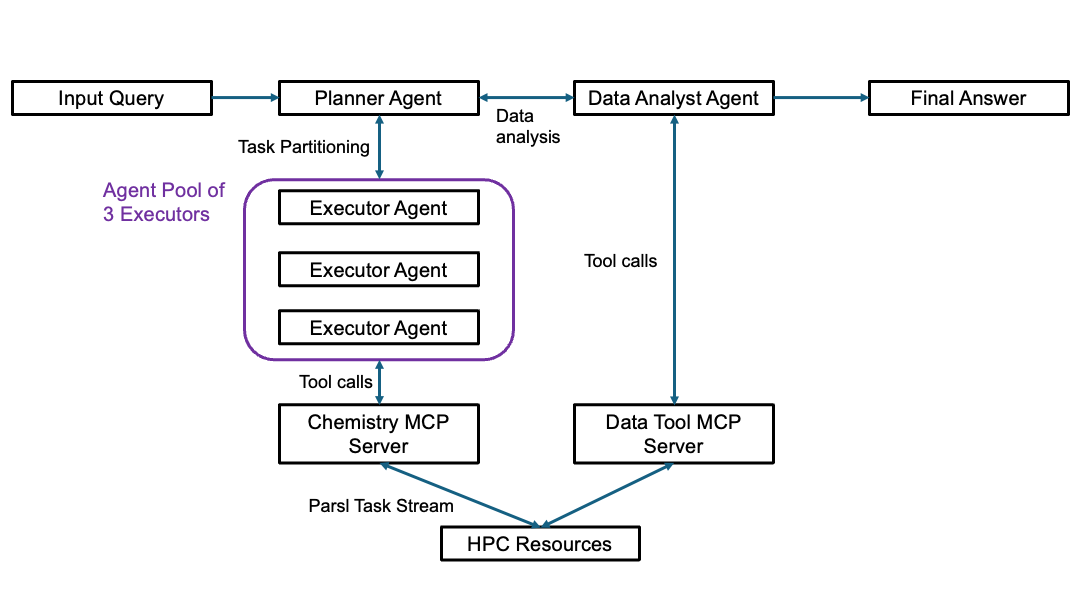
Figure 1: Schematic detailing the orchestrated, multi-agent hierarchy with planner, executor, and analyst agents interacting across MCP servers and HPC resources.
Key to this framework is its integration with Parsl, which abstracts resource allocation, execution, and fault tolerance. MCP standardizes tool interfaces and supports asynchronous operations, preventing serialization bottlenecks typical of single-agent or sequential architectures. The workflow manager handles millions of simulation tasks with minimal orchestration overhead, demonstrating operational stability and reproducibility on the Aurora supercomputer.
Workflow Demonstration: High-Throughput MOF Screening
The framework was evaluated on a prominent application: high-throughput screening of Metal-Organic Frameworks (MOFs) for atmospheric water harvesting, utilizing the Computation-Ready Experimental (CoRE MOF) database. The agentic system is initiated by a natural language prompt specifying the scientific objectives and simulation parameters. The planner agent translates this into simulation directives, executor agents run Grand Canonical Monte Carlo (GCMC) simulations via gRASPA for thousands of MOFs, and data analyst agents aggregate and post-process the results for final reporting.

Figure 2: Representative agentic workflow output for screening 1,152 MOFs, demonstrating planner decomposition, executor tool invocation, and analyst aggregation.
This explicit exposure of reasoning and tool invocation at each stage affords granular traceability and validation, a critical feature for large-scale scientific campaigns where provenance and intermediate decisions must be auditable.
Screening Results and Statistical Outcomes
The agentic workflow managed the concurrent screening of 2,304 MOFs, computing working capacities of water for atmospheric water harvesting. The statistical analysis reveals a highly skewed distribution: most MOFs exhibit low working capacities (below 1.0 mol/kg), whereas the top 20% reach working capacities up to 7.06 mol/kg. The workflow post-processes and ranks candidates, reflecting the system's capacity to handle large data ensembles robustly and autonomously.
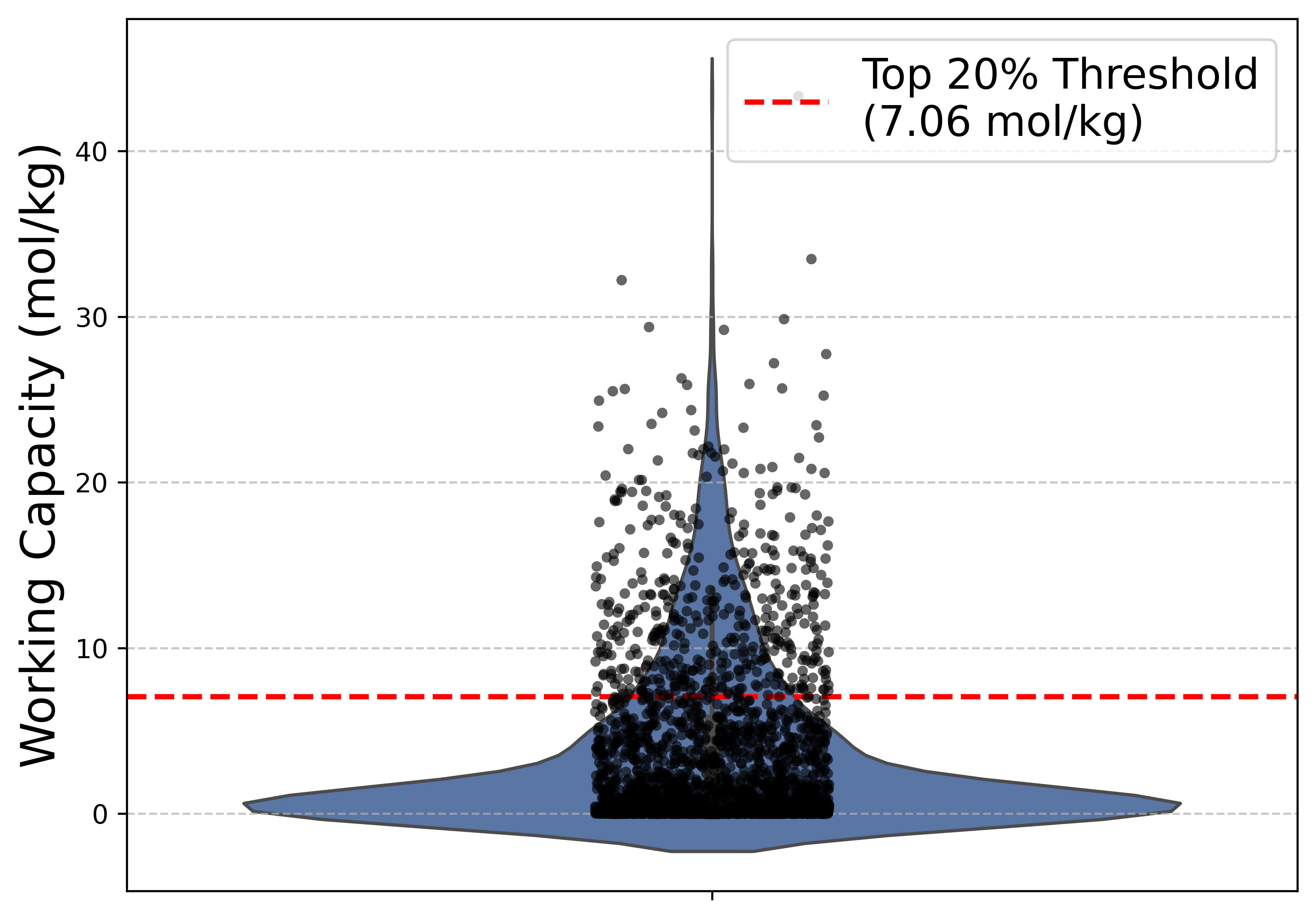
Figure 3: Violin and strip plot showing working capacity distribution across 2,304 MOFs and the top 20% performance threshold.
These results underscore the ability of agent-driven automation to expedite materials discovery, enabling rapid exploration and evaluation of vast design spaces with minimal human intervention.
Multi-Objective Screening and Adaptivity
As materials discovery frequently entails multi-objective optimization, the authors tested the framework's ability to handle simultaneous tasks. The planner agent interpreted a composite prompt requiring water, CO2, and N2 adsorption scenarios and generated parallel workflows for each. Executor agents launched concurrent simulation ensembles, and the analyst agent provided ranked outputs for all objectives. This test highlights the architecture’s dynamic adaptivity: new queries and conditions can be issued at runtime without modifying the underlying code, supporting extensibility for varied scientific objectives.
Weak scaling experiments with fixed-per-node workloads and strong scaling with a fixed MOF dataset were performed across 1–256 nodes on Aurora. The workflow maintained stable throughput across scaling tests despite simulation time variance due to MOF structural differences. Near-linear speedup was observed from 8 to 32 nodes, with strong scaling efficiency at higher node counts dropping to 64.9%, attributable to communication, API, and execution overhead.
Figure 4: (a) Weak scaling performance with constant MOFs per node; (b) Strong scaling speedup as node count increases for full dataset benchmarks.
Agentic overhead (API and orchestration, excluding simulation time) was modest, ranging 60–90 seconds per run. Reliability was evaluated with 25 experiments yielding an 84% success rate, indicating current gaps in tool-calling robustness but demonstrating practical viability for large campaigns.
Implications, Reproducibility, and Future Directions
The research establishes a practical approach for LLM-driven workflows that exploit HPC concurrency, democratizing scientific automation via natural language interfaces. The successful deployment of gpt-oss-120b, an open-weight model, highlights cost, privacy, and reproducibility advantages compared to proprietary models, with the success rate expected to rise as open-weight model reliability improves.
The framework’s architectural modularity is theoretically extensible beyond materials screening, applicable to any scientific domain demanding high-throughput simulation or computational experiments. Practical implications include streamlined resource utilization, transparent workflow traceability, and flexible expansion for multi-objective or adaptive campaigns. These features may catalyze adoption in computational chemistry, systems biology, and other data-driven sciences.
Future research may focus on further improving agent reliability, integrating more sophisticated reasoning capabilities in the planner agent (e.g., reinforcement learning, Bayesian optimization), and enabling more autonomous adaptation to intermediate results. Extending orchestration to hybrid AI/physics pipelines and tighter coupling with experimental data streams also presents substantial opportunities.
Conclusion
The hierarchical multi-agent orchestration framework described in this paper provides a robust, scalable, and modular solution for LLM-driven scientific automation on leadership-class HPC systems. By effectively separating planning, execution, and analysis, and leveraging asynchronous tool interfaces and workflow managers, the architecture achieves efficient high-throughput screening with low overhead and significant flexibility. Its implications extend beyond materials screening, offering a blueprint for integrating agentic AI with scientific HPC at scale and promoting reproducible, adaptive, and accessible computational research.