Mind to Hand: Purposeful Robotic Control via Embodied Reasoning
Abstract: Humans act with context and intention, with reasoning playing a central role. While internet-scale data has enabled broad reasoning capabilities in AI systems, grounding these abilities in physical action remains a major challenge. We introduce Lumo-1, a generalist vision-language-action (VLA) model that unifies robot reasoning ("mind") with robot action ("hand"). Our approach builds upon the general multi-modal reasoning capabilities of pre-trained vision-LLMs (VLMs), progressively extending them to embodied reasoning and action prediction, and ultimately towards structured reasoning and reasoning-action alignment. This results in a three-stage pre-training pipeline: (1) Continued VLM pre-training on curated vision-language data to enhance embodied reasoning skills such as planning, spatial understanding, and trajectory prediction; (2) Co-training on cross-embodiment robot data alongside vision-language data; and (3) Action training with reasoning process on trajectories collected on Astribot S1, a bimanual mobile manipulator with human-like dexterity and agility. Finally, we integrate reinforcement learning to further refine reasoning-action consistency and close the loop between semantic inference and motor control. Extensive experiments demonstrate that Lumo-1 achieves significant performance improvements in embodied vision-language reasoning, a critical component for generalist robotic control. Real-world evaluations further show that Lumo-1 surpasses strong baselines across a wide range of challenging robotic tasks, with strong generalization to novel objects and environments, excelling particularly in long-horizon tasks and responding to human-natural instructions that require reasoning over strategy, concepts and space.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching robots to not just see and understand the world with language, but also to act in it with purpose. The team built a model called Lumo-1 that connects a robot’s “mind” (reasoning) to its “hand” (actions). It uses images, words, and motor control together so a robot can follow natural instructions like “put the low-calorie drink behind the yellow notebook,” figure out what that means, plan the steps, and move its arms to do it safely.
Key Questions and Goals
The researchers wanted to answer simple but hard questions:
- How can we make a robot think about what it’s doing, instead of just copying movements?
- How can we teach a robot to understand space (like “left of,” “behind,” “on the table”), objects, and human intent from pictures and words?
- How can we connect that understanding to smooth, precise actions across many kinds of tasks and different robots?
- How do we make the robot’s choices more transparent, so we know why it did something?
How They Did It (Methods and Approach)
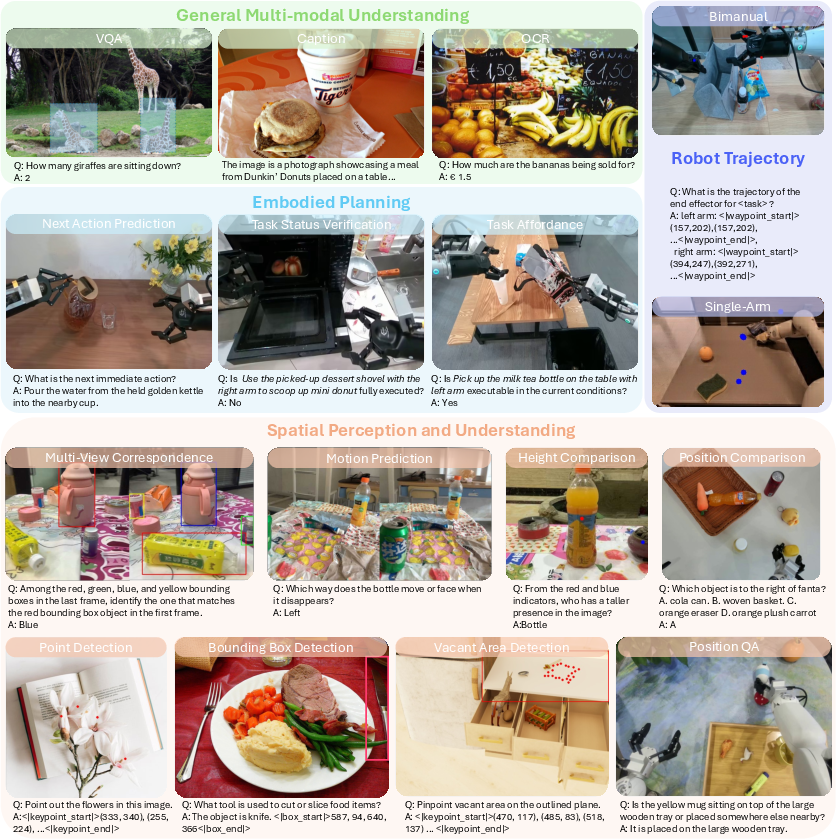
Teaching the Robot to Understand (Vision + Language)
Lumo-1 starts from a big pre-trained model that already understands images and text (Qwen2.5-VL-7B). The team then continued training it with special vision-language tasks that focus on the physical world:
- Understanding spatial relations and sizes (“Which object is left of the cup?”).
- Planning steps to finish a task (“What should I do next?”).
- Predicting simple arm motion paths on images. This improves the robot’s “common sense” about objects, space, and tasks.
Teaching the Robot to Act (Vision + Language + Action)
Next, they added action prediction so the model can output movements. Instead of controlling the robot directly joint-by-joint, they describe motions in the robot’s hand space (the “end-effector”), like tiny changes in position and rotation. This is more universal and easier to share across different robot bodies.
They trained on diverse demonstrations from multiple robots and many tasks to learn general physical skills. This helps Lumo-1 work in new environments and with new objects.
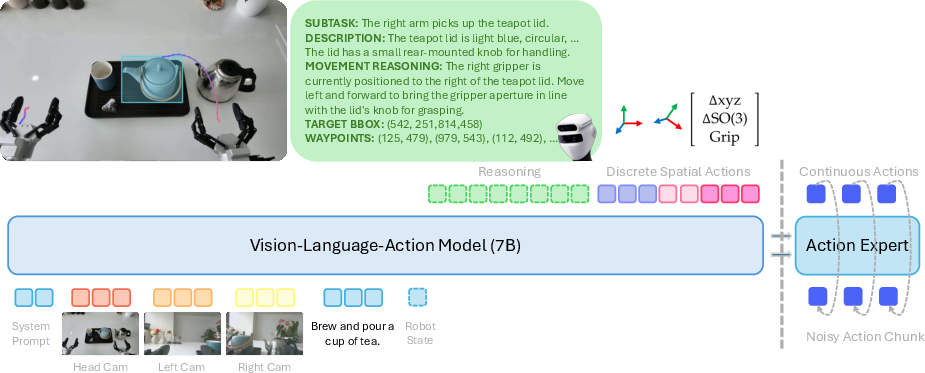
Teaching the Robot to Think, Then Act (Reasoning Traces)
The model doesn’t just output movements. It first “thinks out loud” by producing short reasoning steps (like subtask decisions and target locations), then generates the movement. Think of it as writing a mini plan before moving. This connects high-level understanding (the why and where) to low-level control (the how).
A Smarter Motion Alphabet (Spatial Action Tokenizer)
Robots move continuously, but the model learns better with simple pieces. So the team created a motion “alphabet”:
- They break real arm trajectories into key “waypoints,” like checkpoints on a route.
- They learn a small set of common tiny motions (“tokens”), each being a safe, valid step.
- The model predicts a sequence of these motion tokens—like spelling out a sentence—to reach the next waypoint.
This has two big benefits:
- It’s compact and fast (fewer tokens to predict).
- Every token is a valid small movement, reducing the chance of unsafe or nonsense actions.
To make motions smooth later, they add an “action expert” that can turn these tokens into continuous, fluid movements. First it learns general motion shapes; then it’s fine-tuned to specific tasks. This keeps language understanding strong while making actions precise.
Fine-Tuning with Rewards (Reinforcement Learning)
Finally, they use reinforcement learning (RL), which is like coaching: the model tries different plans and actions, gets a score (reward) for how good they are, and improves. Their RL method (called GRPO) encourages:
- Better reasoning (clearer subtask decisions and object locations).
- Better alignment between what the plan says and what the hands do.
This helps reduce mistakes like choosing the wrong subtask or drawing a bounding box that doesn’t match the movement.
Main Findings and Why They Matter
- Lumo-1 performed better than strong baseline robot models (called π0 and π0.5) on many real tasks, including:
- General pick-and-place across different objects and setups.
- Long, multi-step tasks that need careful planning and consistency.
- Dexterous manipulation that requires precise hand control.
- It generalizes well: it handles new objects, new places, and instructions that include concepts (like “low-calorie”) and spatial terms (like “behind”).
- It is more transparent: the robot’s reasoning steps help explain why it chose certain actions, making behavior easier to trust and debug.
These results show that connecting reasoning and action—mind to hand—helps robots act more purposefully and reliably.
Implications and Potential Impact
- Safer, more dependable home and workplace robots: By thinking through steps and making valid small motions, robots are less likely to make sudden, risky moves.
- Better teamwork with humans: Understanding natural language and spatial hints makes robots easier to instruct (“place the lighter bottle on the top shelf”).
- Faster development across different robot bodies: Describing motions in hand space (end-effector deltas) makes skills more transferable.
- More transparent AI: Reasoning traces let people see the robot’s thought process, building trust and making it easier to fix mistakes.
In short, Lumo-1 is a step toward robots that understand the world like we do, plan sensibly, and move with intent—bringing thoughtful, reliable robot helpers closer to everyday life.
Knowledge Gaps
Unresolved Gaps and Open Questions
Below is a single, concise list of specific knowledge gaps, limitations, and open questions that remain unresolved and can guide future research:
- Quantitative evaluation is under-specified: what exact task suites, metrics (e.g., success rate, subtask completion accuracy, trajectory error), statistical significance, and robustness tests substantiate claims against baselines (π0, π0.5)?
- Generalization scope is unclear: beyond “novel objects and environments,” how far does the model generalize to truly out-of-distribution settings (e.g., extreme lighting, clutter, deformables, tool-use, partial occlusion, moving targets)?
- Long-horizon control is capped by a 1.33 s action horizon; how are multi-minute tasks bridged without compounding drift or reasoning mistakes, and what memory architecture (beyond short-term subtask context) is needed?
- The factorization πθ(μ, a|o, l) = πθ(a|o, μ) πθ(μ|o, l) removes instruction l from action generation once μ is produced; does this discard essential linguistic constraints needed for low-level control, and when should l remain in the conditioning?
- Reasoning correctness and calibration are not quantified: how often are textual and visual reasoning traces wrong, how is confidence represented, and how does incorrect reasoning propagate to unsafe or failed actions?
- Reward design for GRPO is unspecified: what components reward textual reasoning, visual grounding, trajectory quality, and consistency, and how are trade-offs balanced to avoid reward hacking or degenerate reasoning?
- Safety and risk mitigation are not addressed: what safeguards (collision avoidance, force/torque limits, human-in-the-loop checks) ensure safe deployment given 10 kg payload and whole-body mobility?
- No tactile/force feedback: how does Lumo-1 handle contact-rich manipulation (insertion, peeling, cutting, compliant assembly) without haptics or force sensing, and what extensions are needed?
- Real-time latency and throughput of next-token reasoning plus action decoding are not reported: what are end-to-end delays on S1 hardware, and do they permit reactive control under dynamic conditions?
- Discrete–continuous hybrid is under-characterized: when and how does the system switch between discrete tokens and the flow-matching action expert at inference, and what ablations show the benefit over purely discrete or purely continuous policies?
- Flow-matching “unconditional-to-conditional” pre-training may induce distribution shift; how robust is the action expert when conditioned on sparse or noisy task context, and what regularization or adapters help?
- Spatial action tokenizer design choices are not justified: how were waypoint thresholds and cluster counts selected, and what is their sensitivity on performance, compression ratio, and failure modes?
- Motion token library is static and offline; can it be adapted online (e.g., via clustering refresh or token pruning) to new environments, embodiments, or previously unseen motion primitives?
- Top-3 token sampling introduces stochasticity; what is the impact on reproducibility, safety, and success rates, and when should deterministic selection be enforced?
- Synchronizing waypoint selection across torso and both arms may constrain bimanual independence; how does this affect tasks needing unsynchronized, asymmetric, or time-critical dual-arm coordination?
- Capping per-EE translation/rotation tokens at 5 may truncate necessary motion; what are failure cases and how should this limit be adapted to task complexity?
- EE-space delta invariance may be insufficient: differing kinematics, reachability, dynamics, and compliance across embodiments can break cross-robot transfer; what mechanisms (constraints, dynamics models, IK-aware planners) mitigate this?
- Mirroring for left/right trajectory balance may not preserve contact physics and camera parallax; what empirical validations and corrections are needed to avoid mirrored artifacts in grasp and placement?
- Intra-prompt trajectory de-duplication via occupancy grids may remove beneficial micro-variation; how does the threshold affect learning diversity, and can 3D volumetric or topology-based measures improve it?
- Visual calibration and 2D projection of 3D waypoints for trajectory QA are error-prone; what is the calibration procedure, error bounds, and their impact on supervision quality?
- Strategy for handling ambiguous or underspecified instructions is not described: will the system ask clarifying questions, default to conservative behavior, or infer intent via context priors?
- Partial observability and occlusion handling are unclear: does Lumo-1 maintain state over time, fuse multi-view depth, or plan active perception to reveal occluded targets?
- No formal treatment of constraints (joint limits, self-collision, workspace obstacles) in token decoding; how are feasibility checks integrated to prevent invalid motions?
- No metrics for reasoning–action consistency: how is alignment measured (e.g., consistency between predicted bounding boxes and resulting grasps), and how does RL improve it quantitatively?
- Task compositionality remains an open issue: can the model reliably recombine learned subtasks into new long-horizon plans without retraining, and what interfaces enable plug-and-play subtask reuse?
- Comparison with alternative tokenizers (FAST, learned VQ, spline/polynomial bases) lacks controlled ablations; what performance–latency–robustness trade-offs favor the proposed tokenizer?
- Data curation relies heavily on LLM-generated prompts and filtering; what is the rate of label noise/hallucination, and how does it affect embodied reasoning quality?
- Training compute and environmental impact are significant (≈407B tokens, 128×H100 across stages); can curriculum learning, dataset distillation, or active data selection reduce cost without degrading performance?
- Real-world failure taxonomy is missing: what are the dominant errors (perception, reasoning, control), their root causes, and what targeted mitigations (sensor upgrades, reward shaping, token repairs) help?
- Domain adaptation to new sites is unspecified: what few-shot or on-robot fine-tuning protocols enable rapid adaptation to novel kitchens, labs, or factories?
- Multi-lingual instructions and cultural context are unsupported; how does performance degrade outside English, and can cross-lingual pre-training bridge this?
- Human–robot interaction beyond one-shot instructions is unexplored: can the model handle dialogue, corrections, or preferences, and what interfaces improve collaboration?
- Ethics, privacy, and data governance are not discussed: how are household scenes anonymized, and what policies govern responsible deployment?
- Reproducibility is limited: will code, models, motion token libraries, calibration procedures, and datasets be released with exact hyperparameters and seeds to enable controlled replication?
Glossary
- Action chunk: A short sequence of actions over a fixed temporal horizon used for training and inference. "or more generally, an action chunk~ over a horizon of timesteps:"
- Affordance: The actionable possibilities an environment or object offers to an agent. "ShareRobot Affordance~\citep{ji2025robobrain} formulates affordance prediction as identifying the target location an agent should move to, conditioned on the task description."
- Autoregressive transformer backbone: A transformer model that generates outputs by predicting the next token conditioned on previous tokens. "which are then processed by a unified autoregressive transformer backbone which parameters are commonly initialized from a pre-trained visionâlanguage foundation model."
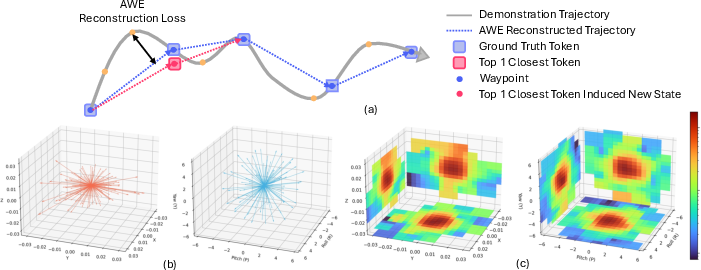
- AWE: A waypoint extraction algorithm that decomposes trajectories into minimal sets of waypoints under a reconstruction error budget. "we employ AWE~\citep{shi2023waypoint} to decompose each robot trajectory into a minimal set of waypoints whose linear interpolation approximates the original trajectory within a specified error threshold."
- Bimanual mobile manipulator: A robot platform with two arms mounted on a mobile body for dexterous manipulation. "Astribot S1, a bimanual mobile manipulator with human-like dexterity and agility."
- Binning-based discretization: A quantization method that maps continuous action dimensions into uniformly spaced bins. "The most widely used approach relies on simple binning-based discretization schemes~\citep{brohan2022rt,zitkovich2023rt,kim2024openvla}, where each action dimension is quantized independently."
- Chain-of-thought (CoT) reasoning: Step-by-step intermediate reasoning used to improve decision-making before producing outputs. "Step-by-step reasoning prior to producing an output - commonly referred to as chain-of-thought (CoT) reasoning - has become a key paradigm for enhancing LLM performance."
- Cross-embodiment: Training or modeling that spans multiple robot embodiments to improve generalization. "Co-training on cross-embodiment robot data alongside vision-language data"
- Delta end-effector (EE) space: Representing actions as incremental changes (deltas) in the robot’s end-effector position and orientation. "Each action is expressed in the delta end-effector (EE) space, with rotations parameterized in "
- Diffusion: A generative modeling technique for continuous distributions, used here to model action trajectories. "Building on recent advances in generative modeling, VLA models have explored representing action distributions through diffusion~\citep{liu2024rdt, ze20243d, chi2023diffusion}"
- Discrete cosine transform (DCT): A frequency-domain transform used for compression, applied to action tokenization. "Recent work such as FAST~\citep{pertsch2025fast} employs compression-based tokenization using discrete cosine transform (DCT) encoding."
- End-effector: The terminal part of a robot arm (e.g., gripper) that interacts with objects. "This task focuses on predicting the motion trajectory of the robot end-effector projected onto 2D head camera images."
- Flow matching: A training approach that learns continuous vector fields mapping between distributions, enabling efficient continuous action generation. "For fine-tuning, we add an action expert trained with flow matching~\citep{lipman2022flow} to improve inference efficiency."
- GRPO (Group Relative Policy Optimization): A reinforcement learning algorithm that optimizes policies using group-relative advantages and KL regularization. "we employ a reinforcement learning stage using Group Relative Policy Optimization (GRPO)~\citep{shao2024deepseekmath}."
- Intra-Prompt Trajectory De-duplication: A method to remove redundant trajectories within the same task/subtask prompt to increase diversity. "Intra-Prompt Trajectory De-duplication."
- K-means clustering: An unsupervised clustering method used to build motion token libraries from action deltas. "The deltas between consecutive waypoints are modeled via k-means clustering, where each cluster centroid defines a motion primitive that is incorporated into the motion token library."
- Key–value (KV) cache: Cached transformer attention states used to condition fast action generation. "During fine-tuning, a pre-trained flow-matching action expert is integrated to generate actions more efficiently, conditioned on the keyâvalue (KV) cache produced by the VLA backbone."
- Kullback–Leibler (KL) divergence: A measure of distributional difference used to regularize policy updates. "The KL regularization term, weighted by , constrains policy updates to remain close to the previous model $\pi_{\theta_\text{old}$, thereby ensuring stable and conservative policy improvement."
- Motion primitive: A discrete, reusable unit of movement representing typical action deltas. "each cluster centroid defines a motion primitive that is incorporated into the motion token library."
- Next-token prediction: A training objective where the model predicts the next token in a sequence, used for both text and discretized actions. "we first train Lumo-1 with next-token prediction objective over discrete actions."
- Occupancy grid: A discretized representation marking occupied cells, used here to compare and de-duplicate trajectories. "let and denote the occupancy grids of trajectories and "
- Proprioceptive state: Internal robot sensing (e.g., joint angles, forces) included in observations for control. "The observation ~ typically comprises multi-view visual inputs and the proprioceptive state of the robot."
- Robot Trajectory Mirroring: A data augmentation technique that mirrors trajectories (and corresponding visuals) across arms to balance training. "Robot Trajectory Mirroring."
- Slerp interpolation: Spherical linear interpolation for smoothly interpolating rotations. "Position and rotation are treated separately, using distinct distance metrics: point-to-line distance for position and rotational distance (after slerp interpolation) for rotation."
- SO(3): The group of all 3D rotations; used as the representation space for orientations. "with rotations parameterized in "
- Spatial action tokenizer: A tokenization scheme that encodes spatially structured motion deltas into discrete tokens. "we introduce a spatial action tokenizer for representing motion sequences."
- Teleoperation: Human-operated remote control of the robot used to collect demonstration data. "In teleoperation, differences in operator proficiency and personal preferences often lead to variations in motion speed and micro-movements."
- Top-3 token sampling strategy: A robust decoding approach that randomly selects among the three closest motion tokens. "we introduce a top-3 token sampling strategy: where the robot randomly selects among the three most relevant motion primitives."
- Vision-Language-Action (VLA) models: Multimodal models that integrate vision and language with action generation for robotic control. "Vision-language-action (VLA) models, denoted as , are typically optimized via imitation learning on large-scale robot demonstration datasets~."
- Vision–LLMs (VLMs): Multimodal models combining visual encoders with LLMs, trained on image-text data. "VLMs are generally trained via next-token prediction on paired or interleaved image-text data."
- Warmup-Stable-Decay: A learning-rate schedule with warmup, stable phase, and final decay for training stability. "The Warmup-Stable-Decay~\citep{hu2024minicpm} strategy is applied to the learning rate schedule, consisting of a 1\% warmup phase and a 10\% final decay phase."
- Waypoint decomposition: Representing trajectories via a minimal set of intermediate states to simplify modeling and reduce noise. "The waypoint decomposition abstracts away such temporal and micro-motion discrepancies, while k-means clustering further suppresses residual micro-movement noise, thereby simplifying modeling and enhancing representational consistency."
Practical Applications
Practical Applications of Lumo‑1’s Findings, Methods, and Innovations
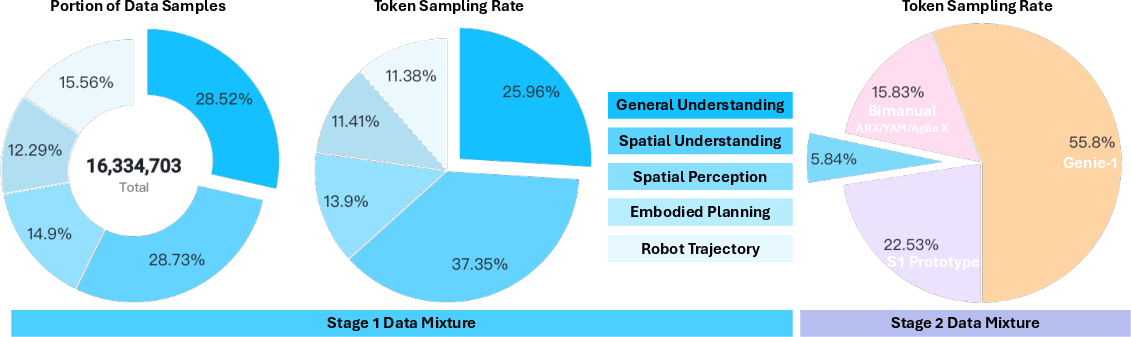
Below we group actionable, real‑world applications that derive from the paper’s core contributions: a generalist VLA policy (Lumo‑1), a spatial action tokenizer for cross‑embodiment control, a three‑stage training pipeline coupling embodied reasoning with action, a discrete‑to‑continuous action strategy with a flow‑matching expert, reasoning–action alignment via RL (GRPO), trajectory de‑duplication and mirroring for data efficiency, and long‑horizon control with subtask‑completeness gating.
Immediate Applications
These applications can be piloted or deployed now with available hardware (e.g., bimanual mobile manipulators with wrist/head cameras, 30 Hz control) and the training/integration recipes presented.
| Application | Sector(s) | Potential Tools/Products/Workflows | Assumptions/Dependencies |
|---|---|---|---|
| Bimanual pick‑and‑place for kitting, induction, and line changeover | Robotics, Manufacturing, Warehousing | Lumo‑1 ROS 2 skill server; Spatial Action Tokenizer library; partial‑reasoning mode for speed; top‑3 motion‑token sampling; EE‑space deltas for cross‑cell transfer | Calibrated cameras; 30 Hz control; appropriate grippers; safety fencing/cobotics compliance; on‑edge GPU or low‑latency cloud inference |
| Retail shelf restocking and backroom sorting under natural language instructions | Retail, Robotics | Planogram‑aware prompts; long‑horizon subtask‑gate controller; reasoning trace logger for auditability | Shelf/camera calibration; SKU/graspability constraints; store safety policies; illumination variability handling |
| Hospital and lab logistics (fetch/bring/place, instrument loading, bin transfers) | Healthcare, Life Sciences | Voice/text instruction UI; partial‑reasoning mode; conservative action sets; reasoning–action RL tuning for sterile zones | Non‑clinical tasks only; infection control; human‑in‑the‑loop overrides; HIPAA/alike privacy in VLM inputs |
| Facilities and hospitality services (meeting setup, bussing tables, room reset) | Hospitality, Property Ops | Long‑horizon subtask completeness gating; cross‑embodiment retargeting to diverse cobots | Mixed‑traffic safety; variable lighting/clutter; cart/tools compatibility |
| Cross‑embodiment skill transfer and retargeting | Robotics Integrators | EE‑space motion representation; action mirroring (left/right); per‑robot kinematics adapters | Accurate kinematics/extrinsics; torque/velocity limits respected; gripper differences abstracted |
| Transparent robot behavior via reasoning traces (explain → act) | Software, Safety/Compliance | Reasoning trace logger; test‑harness to check alignment between textual, visual, and trajectory predictions | Trace storage/governance; operator training; UI for “think/no‑think” switching; avoids leaking sensitive visual data |
| Data curation at scale (faster, cleaner datasets) | Academia, Industry R&D | Intra‑prompt trajectory de‑duplication; systematic mirroring; scheduler‑guided data collection | Access to teleop rigs; dataset quality gates; consistent camera intrinsics/extrinsics |
| Faster policy adaptation using a pre‑trained flow‑matching action expert | Robotics R&D, Software | Unconditional→conditional flow‑matching fine‑tuning; shared action expert across tasks | Sufficient diverse action corpus; stable VLM backbone; GPU budget for short fine‑tunes |
| Spatial perception and waypoint QA as auxiliary supervision | Perception, Software | Bounding‑box/keypoint/trajectory QA generators; VQA‑style training for embodied spatial reasoning | Quality of mask/box generators (e.g., SAM); robust camera calibration |
Long‑Term Applications
These require further research, scaling, validation, or regulatory maturation (e.g., greater robustness, broader tool use, safety certification, fleet learning).
| Application | Sector(s) | Potential Tools/Products/Workflows | Assumptions/Dependencies |
|---|---|---|---|
| General‑purpose household assistant (multi‑room chores with reliable generalization) | Consumer Robotics | Skill library built on motion‑token primitives; structured reasoning for long‑horizon chores; home calibration auto‑setup | Robust grasping across long‑tail objects; safe autonomy in proximity; cost‑effective hardware |
| Eldercare ADL support (retrieval, tidying, light meal prep) | Healthcare, Home Care | Safety‑first subtask gating; explainable reasoning logs for caregivers; shared autonomy UI | Clinical and ethical approvals; rigorous failure handling; smooth HRI; liability coverage |
| Flexible low‑volume manufacturing without task‑specific programming | Manufacturing | “App‑store” of composable motion tokens; on‑line few‑shot adaptation with flow‑matching expert | Standardized end‑effectors; product variability handling; QA integration |
| Hazardous‑environment operations (valves, switches, inspections) | Energy, Utilities, Industrial | Tool‑use extensions in EE‑space; robustness to PPE, dust, low light; compliance logs from reasoning | Rated hardware for hazardous zones; remote ops; harsh‑environment perception |
| Sterile logistics and OR support (non‑invasive) | Healthcare | Policy windows that enforce sterile zones; GRPO‑style safety shaping; continuous auditing via traces | Medical device certification; stringent cleanliness; human oversight |
| Federated fleet learning with reasoning–action alignment | Robotics Platforms | On‑device GRPO variants; privacy‑preserving aggregation; fleet‑wide token‑library updates | Reliable telemetry; privacy/IT policies; drift detection; safe deployment guards |
| Cross‑vendor motion‑token standard and skill marketplace | Robotics, Standards Bodies | Open motion‑token libraries for EE‑space deltas; validation suites; capability descriptors | Vendor buy‑in; kinematic/IO abstraction layers; certification processes |
| Multi‑robot collaborative tasks with subtask‑level coordination | Warehousing, Events, Construction | Shared subtask completeness signals; spatial reasoning over shared maps; conflict resolution policies | Robust comms; global localization; task allocation frameworks |
| Advanced tool use and automated tool‑change workflows | Manufacturing, Field Service | Reasoning over affordances; token libraries for insertion/fastening/scraping; perception‑driven alignment | High‑precision calibration; force/torque sensing; fixturing |
| Compliance‑first deployment playbooks leveraging reasoning logs | Policy, Governance | Standard operating procedures mapping reasoning→action; audit trails for AI Act/OSHA/ISO | Accepted industry standards; data retention policies; red‑teaming/validation benchmarks |
Notes on cross‑cutting assumptions and dependencies:
- Hardware: bimanual manipulators with wrist and head cameras, accurate camera/robot calibration, suitable grippers/end‑effectors, and 30 Hz control loops as assumed in the paper.
- Compute: training used large‑scale compute (hundreds of billions of tokens on 128 H100s); inference can be hosted on smaller GPUs but latency budgets and safety envelopes must be validated.
- Data: success depends on diverse, high‑quality teleoperation trajectories; the paper’s de‑duplication, mirroring, and scheduler can reduce collection burden but still require operator expertise.
- Safety and compliance: deployment in human spaces requires risk assessment, interlocks, fallbacks, and logging; reasoning traces improve auditability but do not replace formal certification.
- Generalization: the model showed strong generalization to novel objects/environments in reported tests; real‑world edge cases (lighting, clutter, deformables, tool variability) may require domain adaptation.
- Integration: ROS 2/PLC connectivity, facility maps, inventory/ERP links, and voice/UI layers are often needed to realize full workflows.
- Ethics and privacy: vision‑language inputs can capture sensitive scenes; logging and retention must follow local regulations and institutional policies.
Collections
Sign up for free to add this paper to one or more collections.