- The paper introduces a reasoning-guided alignment framework that leverages VLM-generated region descriptions to enhance document retrieval accuracy.
- It combines contrastive learning with KL regularization, resulting in over 2% NDCG improvement across multiple benchmarks.
- Results demonstrate improved query-document embedding alignment and refined attention on sparse, localized visual cues.
Reasoning-Guided Fine-Grained Alignment for Visual Document Retrieval
Motivation and Context
Visual document retrieval tasks present complex challenges due to the heterogeneous layouts and sparsely distributed evidence across document images. Traditional approaches often rely on VLMs to encode document pages and queries into a shared embedding space, optimizing alignment via contrastive objectives. These methods primarily focus on global representations, frequently neglecting fine-grained, localized evidence that is critical for effective retrieval under visually rich and spatially complex scenarios. OCR-based methods are susceptible to recognition errors and loss of layout information, whereas VLM-based retrievers struggle with diffuse attention distributions, especially when using InfoNCE-style contrastive learning. The ReAlign framework specifically addresses the need for more principled, region-focused supervision by leveraging the reasoning capacity of VLMs.
ReAlign Methodology
ReAlign integrates reasoning-guided fine-grained alignment signals into the training of visual document retrievers. The approach first employs a high-capacity VLM to localize query-relevant regions within a page and then generates query-aware descriptions grounded in these regions. It collects query-document-description triplets (q,d,t), where t is sampled from VLM-grounded region descriptions. The retriever is optimized to minimize the KL divergence between the ranking distributions induced by the query and those induced by the region-focused descriptions, effectively regularizing the model to achieve semantic consistency between query intent and evidence localization.

Figure 1: Reasoning-guided region grounding enables ReAlign to concentrate attention on ground-truth regions, unlike conventional InfoNCE training.
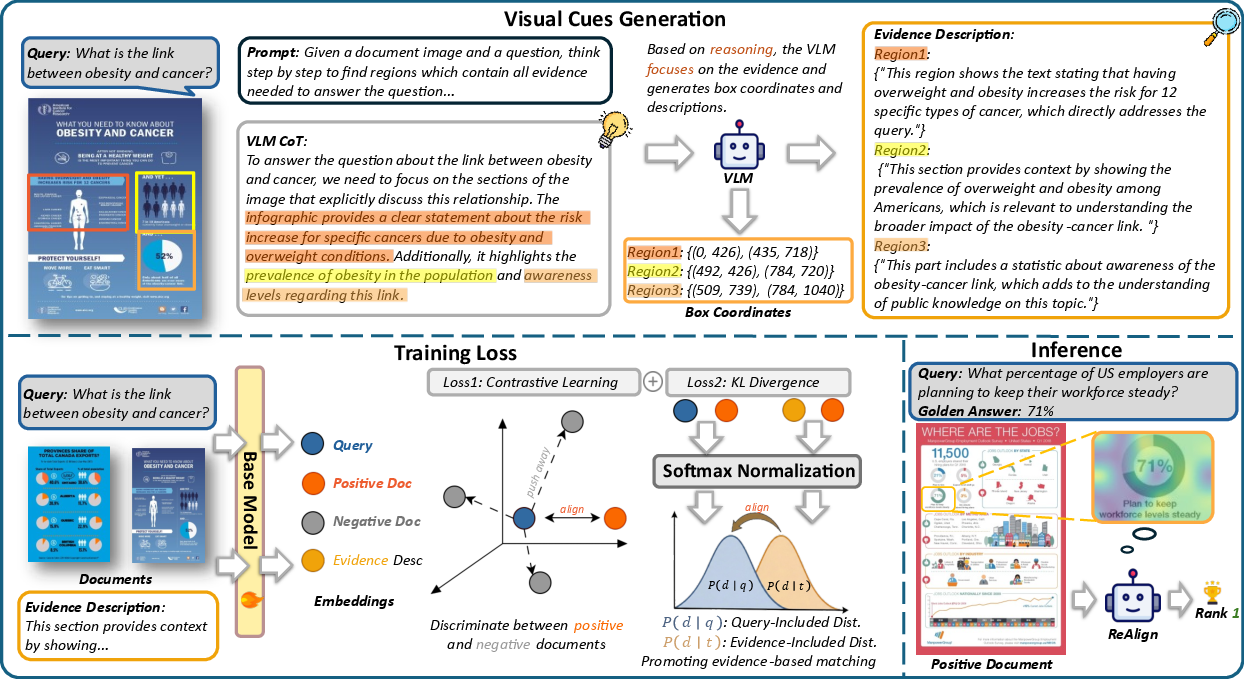
Figure 2: The ReAlign architecture leverages region-focused descriptions synthesized via VLM reasoning for document representation alignment.
The overall loss combines standard contrastive learning with reasoning-guided KL regularization:
L=LContrast+λLKL
where λ tunes the impact of the alignment regularization. The region-focused supervision guides VLMs to encode only those visual and textual cues most relevant for retrieval.
Evaluation and Results
ReAlign was evaluated across six visual document retrieval benchmarks, encompassing both in-domain and zero-shot tasks (DocVQA, InfoVQA, ChartQA, SlideVQA, PlotQA, ArXivQA). The framework demonstrates robust gains across VLM backbones (Phi3V, Qwen2.5-VL). Strong numerical results include average performance improvements exceeding 2% NDCG, with ReAlign consistently outperforming baselines such as InfoNCE-trained, OCR-based, and globally supervised VLM retrievers.
- On DocVQA and InfoVQA, ReAlign (Qwen2.5-VL-7B-Instruct) achieves NDCG@5 scores of 86.5 and 78.6 respectively, yielding statistically significant gains over NV-Embed, DSE, and VDocRetriever.
- The performance margin is particularly pronounced in benchmarks requiring retrieval of sparse, highly localized evidence from visually structured documents.
Ablation studies show that reasoning-guided supervision is the main driver for the observed gains; substituting region-focused descriptions with full-page captions markedly degrades performance. The framework is sensitive to the KL regularization weight, with λ=0.2 offering optimal balance.
Analysis of Training Signal and Embedding Space
The synthesized descriptions produced by reasoning-guided region selection exhibit superior quality and conciseness according to LLM-as-Judge scores.
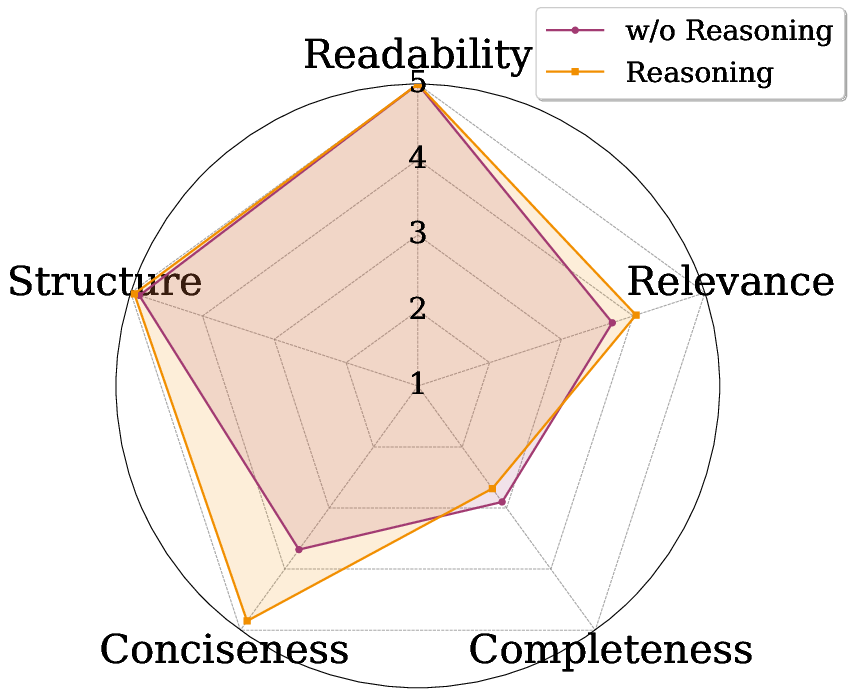
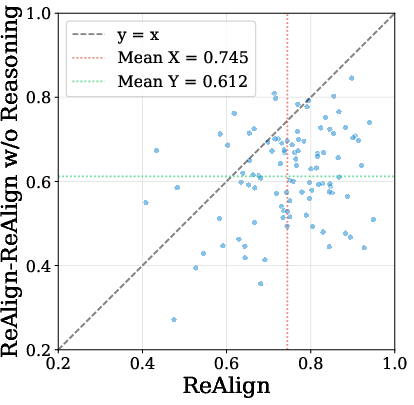
Figure 3: Region-focused descriptions generated by ReAlign achieve higher relevance and conciseness across multiple LLM evaluation dimensions.
Embedding analysis indicates that ReAlign achieves both improved query-to-positive document alignment and greater embedding space uniformity.
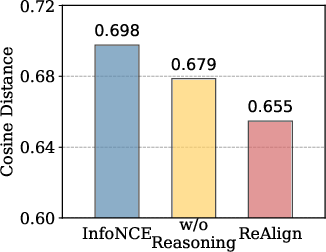
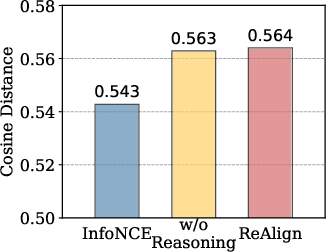
Figure 4: Query-to-positive cosine distance is reduced in ReAlign, indicating finer-grained semantic alignment between query and evidence.
Attention and Region Focus Mechanisms
ReAlign significantly enhances the attention allocation of VLMs toward query-relevant regions, as quantified by averaged coverage scores.
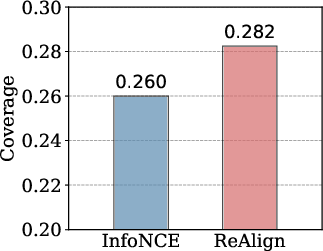
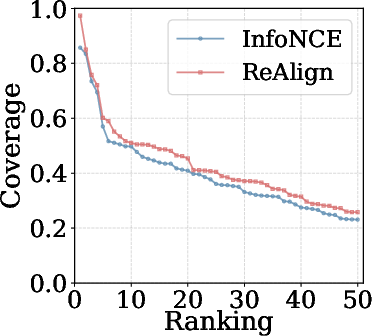
Figure 5: Models trained with ReAlign concentrate attention more reliably over reasoning-guided regions than InfoNCE-trained retrievers.
The Intersection over Union (IoU) score between attention-based patches and query relevance patches is also substantially improved, demonstrating refined agreement between attention and final semantic representations.
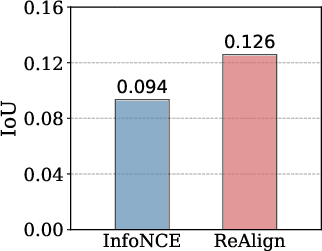
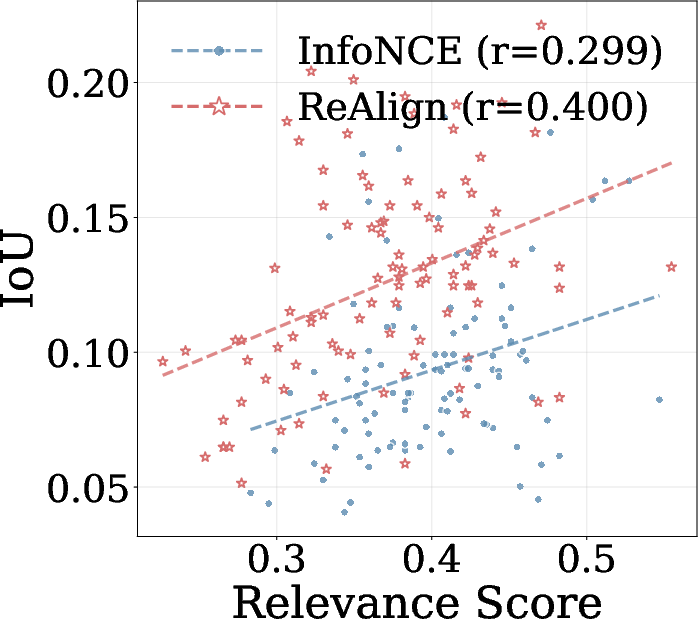
Figure 6: ReAlign fosters higher IoU between attention and query relevance patches, indicating robust region-level alignment.
Case studies further validate the method: ReAlign is able to allocate strong attention to numeric or visual cues critical for retrieval, avoiding distraction from irrelevant content, whereas InfoNCE-trained models exhibit diffuse or biased attention.

Figure 7: ReAlign consistently focuses attention on decisive regions in visual documents, outperforming conventional contrastive retrievers.
Implications, Theoretical Impact, and Future Directions
ReAlign advances visual document retrieval by integrating explicit, reasoning-guided region alignment as supervisory signals. This approach consistently yields superior retrieval performance, particularly for tasks requiring localization and aggregation of sparse evidence. The results assert that region-focused supervision, empowered by VLM reasoning capabilities, is essential for semantic grounding in visually rich, structurally complex documents.
Theoretically, the framework demonstrates that distributional alignment between query-induced and evidence-induced rankings promotes discriminative and robust embedding spaces, validating the dual objectives of alignment and uniformity in contrastive learning. Practically, ReAlign’s generalizability across VLM backbones and domains suggests a path forward for developing retrievers equipped with robust visual grounding and effective evidence attribution, supporting downstream document understanding and retrieval-augmented generation tasks.
Future directions include scaling reasoning-guided alignment to multi-page or composite documents, integrating reinforcement learning for adaptive region selection, and extending the approach to video or non-document visual modalities. There is also scope for leveraging more sophisticated multimodal reasoning agents to further refine description synthesis and improve retrieval specificity.
Conclusion
ReAlign introduces a reasoning-guided alignment framework for visual document retrieval, leveraging VLM-derived region-focused descriptions as fine-grained supervision. Empirical and quantitative analyses confirm substantial improvements in retrieval accuracy, attention targeting, embedding space quality, and evidence grounding. This principled region-focused approach sets a new benchmark for robust and generalizable visual document retrievers (2604.07419).