ViDoRe V3: A Comprehensive Evaluation of Retrieval Augmented Generation in Complex Real-World Scenarios
Abstract: Retrieval-Augmented Generation (RAG) pipelines must address challenges beyond simple single-document retrieval, such as interpreting visual elements (tables, charts, images), synthesizing information across documents, and providing accurate source grounding. Existing benchmarks fail to capture this complexity, often focusing on textual data, single-document comprehension, or evaluating retrieval and generation in isolation. We introduce ViDoRe v3, a comprehensive multimodal RAG benchmark featuring multi-type queries over visually rich document corpora. It covers 10 datasets across diverse professional domains, comprising ~26,000 document pages paired with 3,099 human-verified queries, each available in 6 languages. Through 12,000 hours of human annotation effort, we provide high-quality annotations for retrieval relevance, bounding box localization, and verified reference answers. Our evaluation of state-of-the-art RAG pipelines reveals that visual retrievers outperform textual ones, late-interaction models and textual reranking substantially improve performance, and hybrid or purely visual contexts enhance answer generation quality. However, current models still struggle with non-textual elements, open-ended queries, and fine-grained visual grounding. To encourage progress in addressing these challenges, the benchmark is released under a commercially permissive license at https://hf.co/vidore.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
ViDoRe V3: What this paper is about
This paper introduces ViDoRe V3, a big, carefully built test (a “benchmark”) for checking how well AI systems can find information in large collections of documents and then write good answers. These documents don’t just have text—they also include tables, charts, and images. The benchmark focuses on three things at once:
- finding the right pages (retrieval),
- writing the answer (generation),
- and pointing to the exact place in the document where the answer comes from (grounding).
Think of it like testing an “open‑book” AI that must act like a great librarian, a clear writer, and a careful fact checker all at the same time.
What questions the researchers asked
They set out to answer simple, real-world questions about AIs that read documents:
- Can AIs find the right pages when the answer is in text, tables, charts, or images?
- Can they answer tougher, open-ended questions that may require using several pages or documents?
- Can they show exactly where the answer came from by drawing a box around the evidence on the page?
- Do systems work across languages (for example, a Spanish question about an English document)?
- Which tools and setups work best—text-only search, image-based search, or a mix of both?
How they built and tested it (in everyday terms)
To build the benchmark, they collected 10 sets of real documents (about 26,000 pages) from areas like finance, energy, pharma, telecom, and more. Then they created 3,099 questions (each translated into six languages: English, French, Spanish, German, Italian, Portuguese).
Here’s how it worked, using simple analogies:
- Retrieval-Augmented Generation (RAG): Imagine you’re taking an open‑book test. The “retriever” is the librarian who quickly grabs the right pages. The “generator” is the student who writes the answer. “Grounding” is highlighting the exact sentence or chart that supports the answer.
- Queries (questions): Some were written by people; others were created by an AI and checked for quality. Questions ranged from “extract a fact” to “compare two things,” “yes/no,” “numbers,” “multi-step reasoning,” and open-ended prompts.
- Visual grounding: Annotators drew rectangles (bounding boxes) around the exact part of the page—text, table, chart, or image—that supports the answer. This is like putting a transparent sticky note around the evidence so you can show your work.
- Quality control: Multiple trained annotators checked relevance and answers. A large vision-LLM first filtered likely pages to save time, then humans verified and refined everything. Final answers were merged and cleaned up.
- Testing the systems: They compared:
- Text-based retrievers (searching words) vs. visual retrievers (looking at page images).
- Rerankers (tools that re-sort the top results to improve quality).
- Different “contexts” given to answer-writing models: only text, only images, or both.
- “Oracle” context (the gold-standard pages chosen by humans) to measure the upper limit of performance.
What they found and why it matters
Here are the main takeaways, with quick explanations for why they’re important:
- Visual retrievers outperform text-only retrievers
- What it means: When the “librarian” sees the actual page images (not just the text), it finds relevant pages more accurately.
- Why it matters: Real documents often store key info in tables, charts, and images that text-only systems miss.
- Reranking helps a lot—especially with text-based pipelines
- What it means: After the first search, using a reranker (a second pass that re-sorts results by usefulness) gives a big boost for text pipelines. Current visual rerankers help only a little and sometimes hurt.
- Why it matters: You can get better results by adding a good reranker to your pipeline today, especially on text.
- Hybrid context (both images and text) helps answer tough questions
- What it means: Giving the answer-writing model both top text snippets and page images led to the best results on hard questions.
- Why it matters: Different formats contain different clues. Combining them gives the AI more complete evidence.
- Images as context often beat text-only for difficult queries
- What it means: When the question is tricky and depends on tables, charts, or layout, showing the model the page images helps it write better answers.
- Why it matters: Preserving visuals prevents important details from getting lost in text extraction.
- Cross-language questions are harder
- What it means: Asking in one language about documents written in another causes a small but consistent drop in retrieval quality.
- Why it matters: Real systems need stronger multilingual and cross-lingual capabilities.
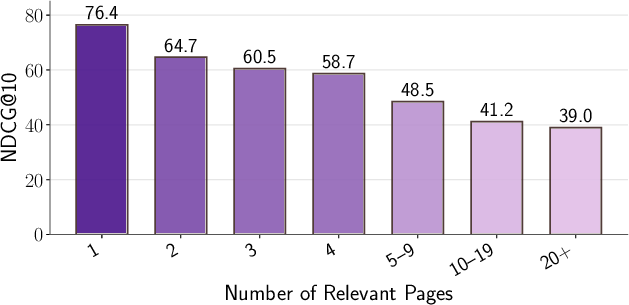
- Complex questions and multi-page evidence remain tough
- What it means: Performance drops when questions require multiple documents/pages or multiple steps of reasoning. Queries about visual content (tables/charts/images) are the hardest.
- Why it matters: This mirrors real work tasks—like comparing values across several pages—which AIs still struggle with.
- Showing exact evidence (visual grounding) is still very hard
- What it means: Today’s models are far from human-level at drawing boxes around the right evidence. They often miss pages that humans marked as relevant.
- Why it matters: If we want trustworthy systems that let users verify claims, visual grounding must improve.
- Big gap between “best pipeline” and the “oracle” (gold pages)
- What it means: Even the best retrieval setups miss important pages that humans would have provided.
- Why it matters: There’s lots of room to make the “librarian” side better—especially for multi-page and visual-heavy cases.
Why this work is useful
- Realistic and comprehensive: ViDoRe V3 tests not just finding text in one document, but also understanding tables, charts, and images across many pages and documents—just like real jobs.
- Multilingual: Questions are available in six languages, so systems can be tested across languages.
- High-quality human checks: Over 12,000 hours of human work went into making sure questions, answers, and evidence markings are trustworthy.
- Public and practical: The benchmark is available under a business-friendly license and is integrated into the MTEB leaderboard, so researchers and companies can compare systems fairly and track progress.
In short, ViDoRe V3 is a powerful “real-world exam” for AI systems that read documents. It highlights what works now (visual retrieval, reranking, hybrid contexts) and what still needs work (cross-lingual search, multi-step reasoning, and visual grounding). This should help build AI assistants that are not only smarter but also more transparent and reliable in everyday use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps that remain unresolved and can guide future research:
- Cross-lingual coverage is limited to high-resource Western European languages; the benchmark lacks queries and documents in low-resource languages, non-Latin scripts, code-switching, and mixed-script scenarios—hindering assessment of truly global RAG systems.
- Query translations were generated by an LLM without reported human verification; the impact of translation errors, semantic drift, and cultural/contextual mismatches on retrieval and generation remains unquantified.
- Source documents are restricted to English/French; cross-lingual retrieval is only evaluated in one direction (queries in multiple languages to English/French docs). The benchmark lacks settings where both queries and documents are multilingual or where documents are in low-resource languages.
- The query distribution is skewed toward extractive types; multi-hop and open-ended queries were “hardest to scale,” suggesting coverage gaps for complex reasoning needs and potential annotation bias.
- The VLM pre-filter discards queries whose answers span >30 pages, systematically excluding broad or corpus-synthesis tasks and limiting evaluation of long-range, cross-document retrieval scenarios.
- Page-level retrieval (NDCG@10) is the primary metric; there is no evaluation at the element/region level (tables, figures, paragraphs) nor task-specific retrieval metrics (e.g., numerical cell-level retrieval for tables, chart segment retrieval), limiting insight into fine-grained retrieval behaviors.
- The textual pipeline uses OCR-extracted Markdown; the impact of OCR errors, layout parsing quality, table/chart extraction fidelity, and alternative text extraction strategies on retrieval and generation is not analyzed.
- Chunking and image descriptions were reported as non-beneficial for the studied textual pipeline, but no systematic ablation across chunk sizes, overlap strategies, layout-aware chunking, or element-level indexing was provided to generalize this finding.
- Hybrid retrieval simply concatenates top-5 image pages and top-5 text pages without duplicate removal or fusion; the effectiveness of de-duplication, cross-modal scoring, reciprocal rank fusion, or learned fusion remains unexplored.
- Only one visual reranker baseline (jina-reranker-m0) was used; the lack of multilingual, cross-modal rerankers trained on this benchmark’s graded relevance labels is a key gap, especially given the large gains from textual reranking.
- No training baselines for rerankers (textual or visual) are reported using the benchmark’s relevance labels; it is unknown how far reranking performance could be improved with supervised learning on ViDoRe V3.
- End-to-end generation is evaluated with off-the-shelf, general-purpose LLMs/VLMs; there are no experiments with models fine-tuned for multimodal RAG on ViDoRe V3, leaving open how much task-specific training could close the oracle gap.
- The hybrid oracle does not outperform the image oracle on hard queries in some settings; optimal ways to package and present mixed text+image evidence (ordering, grouping, summarization, cross-referencing) to generators remain unclear.
- Prompt and context formatting for generation (e.g., page ordering, captions, element-level crops, structured citations) were not systematically ablated; their effects on answer correctness and faithfulness are unknown.
- Faithfulness beyond correctness is not measured; there is no standardized evaluation of evidence consistency, citation accuracy, or answer-source entailment (e.g., does the provided evidence truly support the claimed answer?).
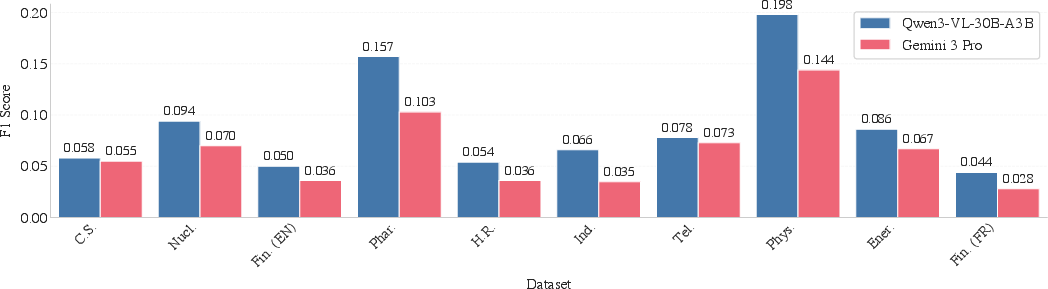
- Visual grounding performance is far below human agreement (F1 ~0.065 vs. human ~0.602); the causes (prompting, recall vs. precision, page selection, box granularity) and remedies (better instructions, element-level targets, training on ViDoRe V3) are not investigated.
- Grounding is evaluated via merged-zone IoU/Dice; alternative metrics that capture multi-instance alignment, granularity preference, and evidence sufficiency (e.g., coverage of all required regions) are not explored.
- The benchmark uses free-form bounding boxes; it remains open whether element-aligned annotations (e.g., Docling-parsed segments, table cells, chart components) would reduce subjectivity and improve model learnability and evaluation stability.
- The LLM judge is used for answer correctness; robustness across judges, sensitivity to prompt variations, inter-judge agreement, and calibration against human evaluation are not reported.
- “Easy vs. hard” labeling depends on a fixed set of LLMs’ parametric knowledge at a point in time; how stable this difficulty stratification is across model updates and time remains untested.
- Multi-page reasoning remains challenging, but the benchmark does not include baselines for agentic or iterative retrieval (e.g., step-by-step retrieval loops, planning, memory)—leaving open whether such strategies materially improve hard-query performance.
- The relationship between retrieval quality (graded relevance/NDCG) and downstream answer accuracy is not quantified; actionable guidance for optimizing k, page selection diversity, or reweighting based on relevance grades is missing.
- Domain-specific evaluation gaps persist (e.g., numerical faithfulness in finance tables, chart interpretation steps in scientific documents, cross-document comparison tasks); targeted metrics and task suites per domain are not provided.
- Cross-lingual degradation (2–3 points) is observed but not dissected; the contributions of query translation quality, document language-model embeddings, reranker language coverage, and generator language handling are not isolated.
- Efficiency and deployability are not evaluated (latency, memory/compute cost, throughput, price-performance trade-offs across pipelines); practical constraints for enterprise settings remain unaddressed.
- Effects of data contamination and pretraining exposure (especially for closed models) are acknowledged but not measured; mechanisms to detect or mitigate training-set overlap with public corpora are not provided.
- The impact of pre-filter false negatives (VLM missing relevant pages) on dataset coverage and annotation quality is not quantified; sampling audits or error analyses of the pre-filter are absent.
- Final answers are aggregated via an LLM; the error rate of this aggregation step, potential loss of minority but correct interpretations, and alternatives (consensus protocols, human adjudication, multi-reference answers) are untested.
- Modality-specific grounding performance (text vs. table vs. chart vs. image) is not reported; targeted grounding difficulties by modality—and corresponding model or annotation remedies—remain unclear.
Practical Applications
Immediate Applications
The paper’s benchmark, findings, and methodology enable several deployable workflows and products across sectors. Below are actionable applications that practitioners can implement now, along with sector links and key dependencies.
- Visual-first retrieval for PDF-heavy knowledge bases (industry: finance, pharma, energy, telecom, industrial)
- What to do: Replace or augment text-only retrievers with late-interaction visual retrievers for page-level search over manuals, filings, reports, and slide decks; prefer models like ColEmbed-3B-v2 for image inputs.
- Why now: Consistent gains over textual retrieval across domains; better handling of tables/charts/images.
- Dependencies: Access to page images; GPU budget for visual embeddings; document ingestion that preserves page fidelity; evaluation against ViDoRe V3 to confirm gains on your corpus.
- Textual reranking on top of base retrieval (industry, academia, software)
- What to do: Add a strong textual reranker (e.g., zerank-2) after initial retrieval—even if you retrieve with visual models—to significantly improve top-k quality.
- Why now: Paper shows large improvements from textual reranking; visual rerankers currently lag.
- Dependencies: High-quality text extraction (OCR + layout); robust chunk-to-page mapping for reranking; multilingual support if needed.
- Hybrid retrieval pipelines (image + text) for harder questions (industry, education)
- What to do: Merge top-k from a visual retriever (images) and a textual retriever (text) before generation to improve accuracy on multi-step/open-ended queries.
- Why now: Hybrid contexts outperform single-modality on difficult queries in the benchmark.
- Dependencies: Deduplication across modalities; context window management; generator that accepts mixed modalities.
- Visual context in generation for complex pages (industry, education)
- What to do: Feed page images (not only OCR text) into VLM/LLM with vision to improve grounding and answer correctness on difficult items.
- Why now: Image contexts beat text-only contexts on “hard” queries even with oracle pages.
- Dependencies: Generator with strong vision (e.g., Gemini 3 Pro class); effective prompt design; image preprocessing and resolution choices.
- Benchmark-driven model selection and CI gates (software MLOps, academia)
- What to do: Adopt ViDoRe V3 in continuous evaluation to select retrievers/rerankers/generators, track regressions, and validate multilingual and visual performance before deployment.
- Why now: Public, commercially permissive benchmark integrated into MTEB; includes retrieval, generation, grounding.
- Dependencies: Reproducible evaluation harness; acceptance thresholds by query type/format; guarding against overfitting (use hold-out/private sets, when available).
- Cross-lingual query support for bilingual/multinational orgs (industry, public sector)
- What to do: Test and tune retrieval when query language differs from document language; deploy language-aware retrievers/rerankers; fallback to translation workflows if needed.
- Why now: The benchmark shows measurable degradation in cross-lingual retrieval—so targeted mitigation is impactful.
- Dependencies: Reliable MT for queries or docs; multilingual embedders; governance for translation accuracy in regulated domains.
- Sourcing and governance via grounded citations (industry, public sector, education)
- What to do: Return page-level evidence with overlays or page anchors; if VLM bounding boxes are unreliable, use OCR spans/coordinates and document element IDs as provisional evidence.
- Why now: Grounding reduces hallucinations and supports auditability; current VLM boxes lag human performance, so adopt hybrid heuristics now.
- Dependencies: OCR with layout (tables/charts recognized), viewer UI to overlay highlights; policies for evidence thresholds.
- Domain-specific RAG assistants for operational documents (industrial maintenance, telecom, energy)
- What to do: Deploy copilot-style Q&A over technical manuals, SOPs, and troubleshooting guides; use visual retrieval + textual rerank + hybrid context.
- Why now: Benchmark domains mirror these use cases; visual elements are prevalent.
- Dependencies: Up-to-date corpora; secure on-prem deployment if needed; user-in-the-loop validation for safety-critical answers.
- Financial and regulatory document copilots (finance, pharma)
- What to do: Question answering over filings, clinical summaries, trial protocols; use visual tables/charts in context; provide source highlights for audit.
- Why now: Tables/charts drive key facts; visual-first pipelines demonstrably help.
- Dependencies: Access rights and licensing; robust PII redaction and compliance logging; human review workflows.
- Enterprise-grade query taxonomy and analytics (industry, academia)
- What to do: Classify tickets/queries by type/format (boolean, numerical, multi-hop, open-ended, question/keyword/instruction) to route to specialized pipelines and measure SLAs by difficulty.
- Why now: Performance is strongly tied to query type/format; routing improves reliability and metrics clarity.
- Dependencies: Lightweight classifier; pipeline variants; metrics dashboards by query segment.
- Human-in-the-loop data creation for in-house benchmarks (industry, academia)
- What to do: Replicate the paper’s annotation protocol: VLM pre-filter pages, human verify relevance and answers, annotate evidence regions; use this to build private, domain-tuned test sets.
- Why now: Method reduces cost while ensuring quality; yields more realistic evaluations than fully synthetic sets.
- Dependencies: Annotation vendor/tooling; clear guidelines; VLM filters; reviewer QA; privacy-safe data hosting.
- Teaching and curriculum assets for multimodal RAG (education)
- What to do: Use ViDoRe V3 to design assignments on retrieval, reranking, grounding; compare pipelines and explain failure modes on charts/tables.
- Why now: Public release, rich multimodal diversity; exposes limits in current systems.
- Dependencies: Course compute budget; simplified evaluation harness; permissive licensing acknowledged.
- Procurement and policy evaluation checklists (public sector, compliance)
- What to do: Require vendors to report ViDoRe V3 scores (retrieval, generation, grounding) and demonstrate multilingual and visual competency; set minimum thresholds for deployment in citizen-facing assistants.
- Why now: Standardized, realistic benchmark reduces vendor claims ambiguity; encourages grounded, auditable answers.
- Dependencies: Policy team alignment on metrics; periodic review cadence; consideration of domain shift vs benchmark coverage.
Long-Term Applications
The paper also surfaces gaps that motivate next-generation systems and research. These require further development, scaling, or model advances.
- Reliable visual grounding with bounding boxes (industry, public sector, academia)
- Vision: Production-grade bounding boxes that match or surpass human evidence agreement, enabling clickable citations and regulatory-grade traceability.
- Why later: Current VLM grounding F1 is far below human; recall is the main bottleneck.
- Dependencies: New VLM training objectives, datasets with fine-grained grounding, UI standards for multi-region evidence.
- Strong multilingual visual rerankers (industry, academia)
- Vision: Rerankers that operate on images+text across languages to close the gap seen today.
- Why later: Visual rerankers currently provide marginal, sometimes negative gains.
- Dependencies: Training corpora and evaluation protocols akin to ViDoRe V3; efficient late-interaction architectures.
- Multi-hop, cross-page and cross-document reasoning at scale (industry, education, research)
- Vision: Agents or planners that orchestrate retrieval across many pages, align mixed modalities, and synthesize evidence with explicit chains of citations.
- Why later: Performance drops as relevant pages grow; “hard” queries remain challenging even with oracle context.
- Dependencies: Long-context models, retrieval-time planning, memory/caching, verifiable reasoning traces.
- Cross-lingual RAG for low-resource and non-Latin scripts (public sector, global enterprise)
- Vision: Seamless search and grounding across script families; robust to translation shifts and specialized terminology.
- Why later: Current benchmark covers 6 Western European languages; broader coverage needs data, models, and evaluation.
- Dependencies: Multiscript OCR, embeddings, datasets and annotations in underrepresented languages.
- Domain-adaptive visual retrievers and table/chart specialists (finance, pharma, scientific publishing)
- Vision: Retrievers specialized in financial tables, clinical endpoints, and complex charts; better “mixed” modality handling.
- Why later: Mixed-content pages are toughest; specialized pretraining and task heads likely needed.
- Dependencies: Curated domain corpora with modality labels; chart/table structural understanding; evaluation slices per modality.
- Evidence-aware generators that “use what they retrieve” (software, compliance)
- Vision: Generators that are measurably sensitive to retrieved evidence, degrade gracefully, and abstain without support; consistent performance gap shrink versus oracle contexts.
- Why later: Even with oracle contexts, models underutilize evidence on hard queries.
- Dependencies: Training with evidence-consumption objectives, counterfactual tests, and abstention calibration.
- Standardized RAG QA audit and governance frameworks (policy, regulated industries)
- Vision: Policies that mandate grounded citations, cross-lingual fairness tests, and per-query-type SLAs; benchmark-backed certification.
- Why later: Requires consensus on metrics, acceptable risk thresholds, and auditing pipelines.
- Dependencies: Sector-specific guidance (e.g., finance, healthcare), legal acceptance, independent test suites.
- Enterprise-grade annotation and evaluation platforms (industry, tooling vendors)
- Vision: Products that implement the paper’s human-in-the-loop protocol: VLM prefiltering, page relevance triage, answer aggregation, and bounding-box UI.
- Why later: Needs integrated workflow automation and cost-effective human oversight at scale.
- Dependencies: Secure data handling, workforce management, quality controls, integration with retrieval/generation stacks.
- Accessibility and learning tools that transform complex visuals (education, public services)
- Vision: Systems that translate charts/tables into accessible narratives with linked evidence for learners and citizens.
- Why later: Requires robust visual grounding and faithful chart reasoning beyond current capabilities.
- Dependencies: Chart semantics understanding, evaluation for faithfulness and pedagogy, multilingual narration.
- Edge and on-prem multimodal RAG for sensitive documents (healthcare, defense, finance)
- Vision: Visual retrievers and generators optimized for constrained hardware and strict privacy.
- Why later: Visual models are compute-intensive; need compression and privacy-preserving pipelines.
- Dependencies: Distillation, quantization, private fine-tuning; policy-compliant logging and audit.
- Retrieval quality SLAs and observability by query segment (industry operations)
- Vision: Live dashboards and alerts for retrieval/generation performance over query types/modalities/languages; automatic fallback strategies.
- Why later: Needs robust telemetry, difficulty tagging, and automated mitigations.
- Dependencies: Query classifiers, benchmark-aligned metrics, canary tests, routing/orchestration layer.
Notes on feasibility and assumptions
- Domain shift: Your documents may differ from benchmark corpora; expect to validate with an internal test set built via the paper’s protocol.
- Data quality: OCR and layout extraction are critical for textual reranking and provisional grounding; scanned or noisy docs reduce gains.
- Compute: Visual retrievers and image-based generation require GPU capacity; budget for embeddings and reranking.
- Multilingual scope: Current benchmark emphasizes Western European languages; extending to other scripts requires additional resources.
- Evaluation bias: LLM judging can introduce bias; consider multi-judge ensembles and human spot checks for critical use cases.
- Compliance: Grounded citations are necessary but not yet fully reliable at bounding-box level; combine evidence heuristics with human review in regulated settings.
Glossary
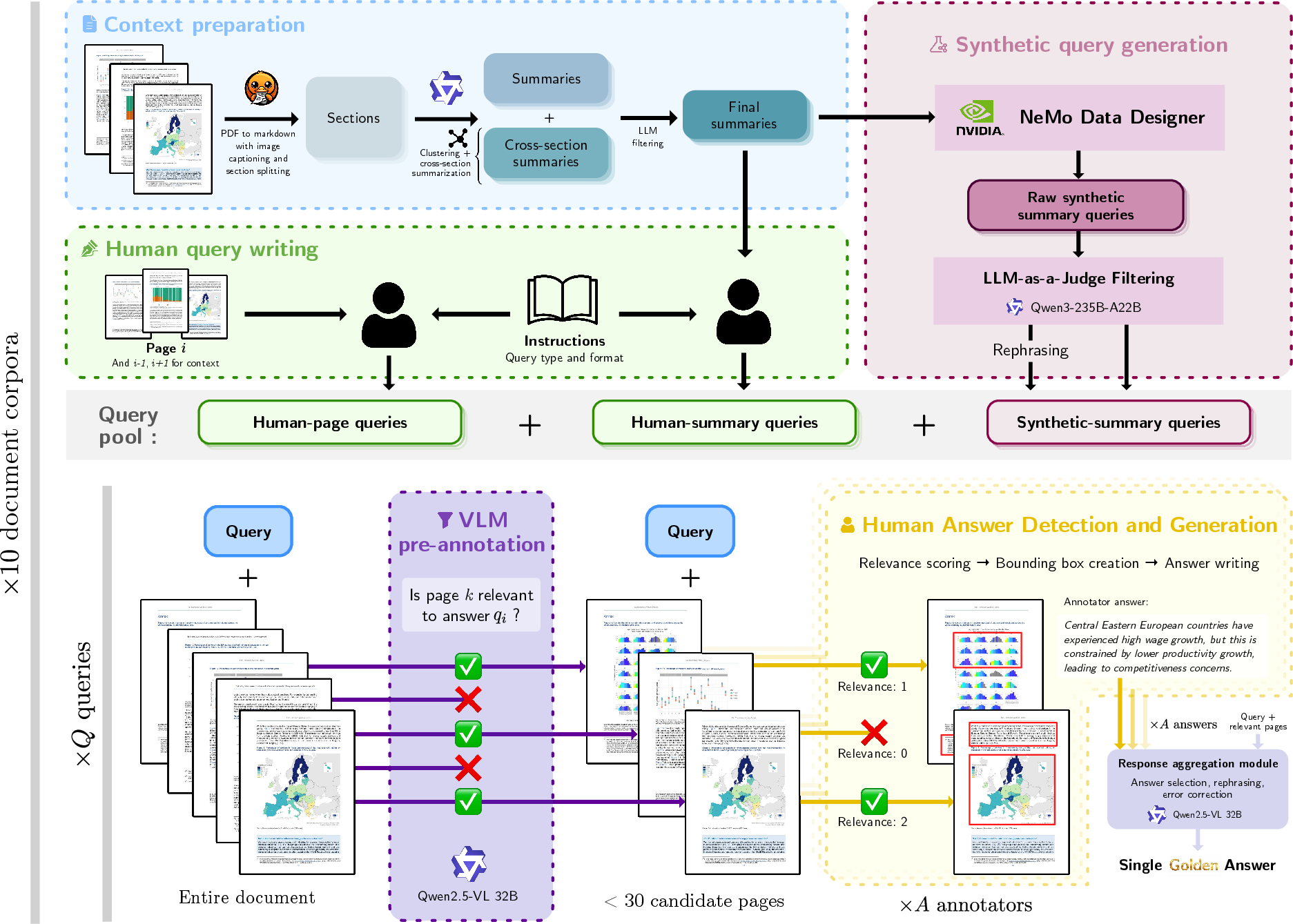
- Blind contextual: Query generation without direct access to the original document content to reduce extractive bias. "Queries are sourced from 3 streams: human extractive (using raw pages), human blind contextual (using summaries to mitigate extractive bias), and synthetic blind contextual."
- Boolean queries: Queries that require a yes/no or true/false answer. "We define 7 Query Types: open-ended, extractive, numerical, multi-hop, compare-contrast, boolean, and enumerative"
- Bounding boxes: Rectangular regions that localize evidence on page images for visual grounding. "For each relevant page, annotators delineate bounding boxes around content supporting the query"
- Compare-contrast queries: Queries asking for similarities or differences between entities or concepts. "We define 7 Query Types: open-ended, extractive, numerical, multi-hop, compare-contrast, boolean, and enumerative"
- Cross-lingual retrieval: Retrieving relevant content when the query and documents are in different languages. "We extend the benchmark to rigorously assess cross-lingual retrieval."
- Dense methods: Retrieval approaches that encode inputs into single dense vectors for similarity search. "for a given parameter count, visual retrievers outperform textual retrievers, and late interaction methods score higher than dense methods."
- Dice coefficient: A measure of spatial overlap (equivalent to F1 for sets) used to compare predicted and ground-truth regions. "We then compare zones across annotators by measuring pixel-level overlap, reporting Intersection over Union (IoU) and F1 score (Dice coefficient)."
- Docling: A document processing toolkit used to extract text and element types from PDFs. "First, the text is extracted from PDFs using Docling along with image descriptions."
- DocVQA: A benchmark for visual question answering on document images. "VDU has traditionally relied on single-page datasets like DocVQA"
- Embedder: A model that converts text into vector embeddings for clustering or retrieval. "They are clustered to group similar summaries together using Qwen3-Embedding-0.6B as embedder"
- Enumerative queries: Queries asking for lists or sets of items. "We define 7 Query Types: open-ended, extractive, numerical, multi-hop, compare-contrast, boolean, and enumerative"
- Ground-truth: Human-verified reference annotations used as the gold standard. "We additionally establish an upper bound using an oracle pipeline that supplies the model with ground-truth annotated pages."
- Gwet's AC2: An agreement coefficient robust to prevalence skew in ratings. "we report Gwet's AC2, as it remains stable under prevalence skew, at 0.760"
- HDBSCAN: A density-based clustering algorithm used to group summary embeddings. "HDBSCAN for clustering."
- Human-in-the-loop: An annotation or evaluation process that integrates human oversight at key stages. "we employ a rigorous three-stage human-in-the-loop annotation process"
- Hybrid pipeline: Combining text and image contexts or retrievers to improve end-to-end performance. "In the hybrid configuration, we concatenate the top-5 results from the visual retriever (images) with the top-5 results from the textual retriever (text), without removing duplicates;"
- Inter-annotator agreement: A measure of consistency across different annotators’ labels. "We compute inter-annotator agreement on the subset of query-page pairs labeled by two or three annotators."
- Intersection over Union (IoU): A metric for the overlap between predicted and reference regions. "We then compare zones across annotators by measuring pixel-level overlap, reporting Intersection over Union (IoU) and F1 score (Dice coefficient)."
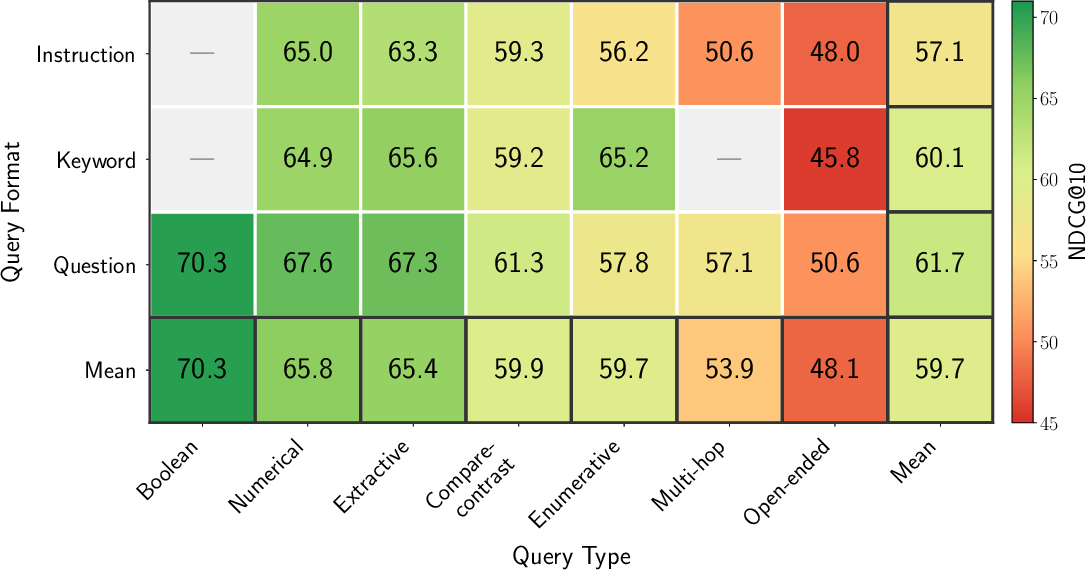
- Instruction format: A query phrasing style that uses imperative instructions rather than questions or keywords. "We define 3 Query Formats: question, keyword, and instruction."
- Keyword format: A query phrasing style consisting of key terms rather than full sentences. "We define 3 Query Formats: question, keyword, and instruction."
- Late interaction methods: Retrieval models that perform token- or region-level interactions at query time to improve matching. "for a given parameter count, visual retrievers outperform textual retrievers, and late interaction methods score higher than dense methods."
- LLM judge: A LLM used to automatically assess correctness of generated answers. "The correctness of generated answers is assessed against the ground truth final answer by an LLM judge"
- Macro-average: Averaging metric scores uniformly across datasets or classes, regardless of size. "Following MTEB conventions, the average score is a macro-average over all datasets."
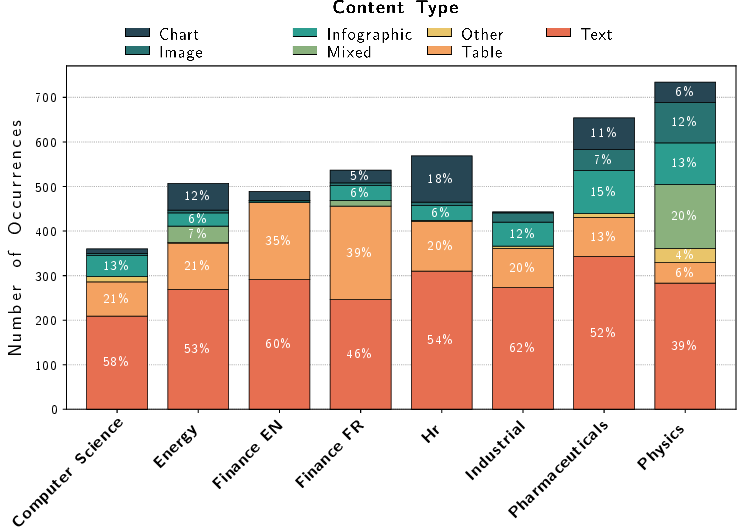
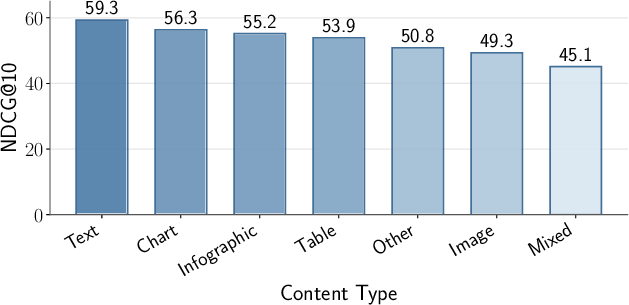
- Modality: The type of content (e.g., text, table, chart, image) present in a document or evidence. "attribute a modality type to each bounding box: Text, Table, Chart, Infographic, Image, Mixed or Other."
- Multi-hop queries: Queries requiring reasoning across multiple pieces of information or pages. "We define 7 Query Types: open-ended, extractive, numerical, multi-hop, compare-contrast, boolean, and enumerative"
- Multimodal RAG: Retrieval-augmented generation that integrates multiple content modalities (text and visuals). "We introduce ViDoRe V3, a comprehensive multimodal RAG benchmark"
- MTEB: The Massive Text Embedding Benchmark framework and leaderboard. "The benchmark is fully integrated into the MTEB ecosystem and leaderboard"
- NDCG@10: Normalized Discounted Cumulative Gain at rank 10, a retrieval effectiveness metric. "Retrieval performance (NDCG@10) across the benchmark."
- NeMo Data Designer: A tool for scalable synthetic data generation pipelines. "This pipeline is implemented using NeMo Data Designer to facilitate generation scaling."
- Oracle pipeline: An evaluation setup that uses gold-standard relevant contexts to estimate an upper bound. "We additionally establish an upper bound using an oracle pipeline that supplies the model with ground-truth annotated pages."
- Parametric knowledge: Information encoded in model parameters that can be recalled without external context. "we stratify queries by difficulty based on parametric knowledge."
- Prevalence skew: Imbalanced occurrence of labels that can bias agreement metrics. "we report Gwet's AC2, as it remains stable under prevalence skew"
- Query taxonomy: A classification of queries by type and format to enable nuanced evaluation. "we develop a query taxonomy with two orthogonal dimensions: Query Type, defining the user's information need, and Query Format, describing the query's syntactic structure."
- RAG (Retrieval-Augmented Generation): A paradigm where generation is grounded by retrieved external content. "Retrieval-Augmented Generation (RAG) pipelines must address challenges beyond simple single-document retrieval"
- Reranker: A model that reorders retrieved items to improve relevance. "We evaluate the impact of adding a reranker to the textual and visual pipelines of the Jina-v4 retriever."
- Tiered review process: A structured multi-level quality assurance workflow for annotations. "Given this strong but imperfect agreement, we implement a tiered review process: extractive queries require at least one annotator and one reviewer, while more complex non-extractive queries require at least two annotators and one reviewer."
- UMAP: A dimensionality reduction technique used before clustering embeddings. "UMAP for dimension reduction"
- Visual Document Understanding (VDU): Understanding and extracting information from visually structured documents. "Early Visual Document Understanding (VDU) benchmarks focus on single-page comprehension"
- Visual grounding: Linking generated answers to specific visual regions in source documents. "we benchmark state-of-the-art models on (i) retrieval accuracy by modality and language, (ii) answer quality across diverse retrieval pipeline configurations, and (iii) visual grounding fidelity."
- Vision-LLM (VLM): Models that jointly process visual and textual inputs. "Vision-LLM (VLM) filtering combined with human expert verification enables efficient, high-quality annotation at scale."
- Visual retriever: A retrieval model that operates on page images rather than text. "visual retrievers outperform textual ones"
Collections
Sign up for free to add this paper to one or more collections.