Towards Scalable Pre-training of Visual Tokenizers for Generation
Abstract: The quality of the latent space in visual tokenizers (e.g., VAEs) is crucial for modern generative models. However, the standard reconstruction-based training paradigm produces a latent space that is biased towards low-level information, leading to a foundation flaw: better pixel-level accuracy does not lead to higher-quality generation. This implies that pouring extensive compute into visual tokenizer pre-training translates poorly to improved performance in generation. We identify this as the pre-training scaling problem and suggest a necessary shift: to be effective for generation, a latent space must concisely represent high-level semantics. We present VTP, a unified visual tokenizer pre-training framework, pioneering the joint optimization of image-text contrastive, self-supervised, and reconstruction losses. Our large-scale study reveals two principal findings: (1) understanding is a key driver of generation, and (2) much better scaling properties, where generative performance scales effectively with compute, parameters, and data allocated to the pretraining of the visual tokenizer. After large-scale pre-training, our tokenizer delivers a competitive profile (78.2 zero-shot accuracy and 0.36 rFID on ImageNet) and 4.1 times faster convergence on generation compared to advanced distillation methods. More importantly, it scales effectively: without modifying standard DiT training specs, solely investing more FLOPS in pretraining VTP achieves 65.8\% FID improvement in downstream generation, while conventional autoencoder stagnates very early at 1/10 FLOPS. Our pre-trained models are available at https://github.com/MiniMax-AI/VTP.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching computers to “understand” images in a smarter way so they can make better, more realistic pictures later. The authors focus on the “visual tokenizer,” a tool that turns an image into a compact code (like a secret message) that a generator (the “artist” model) uses to create new images. They show that the usual way of training this tokenizer—only by perfectly rebuilding pixels—doesn’t help the artist make better pictures. Instead, they propose a new training method (called VTP) that teaches the tokenizer both how to rebuild the image and how to understand what’s in it.
Key Questions
- Why does training the tokenizer to copy pixels perfectly not lead to better image generation?
- What kind of “understanding” should the tokenizer learn so the generator can make higher-quality images?
- Can we scale up (use more data, bigger models, more compute) and see steady improvements if we train the tokenizer the right way?
How They Did It (Methods, in simple terms)
Think of the system as a two-part team:
- Part 1: The “visual tokenizer” compresses an image into a small code (called a latent space). This code should be both detailed enough to rebuild the image and meaningful enough to describe what’s in the image.
- Part 2: A “generator” (like an AI artist) uses that code to paint new images.
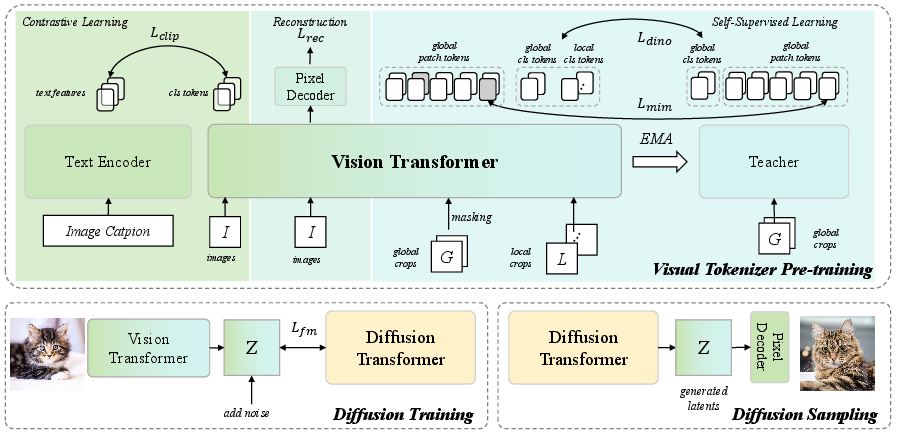
The authors build a new tokenizer based on a Vision Transformer (ViT)—you can think of it as a super-powerful reader that looks at an image piece by piece (patches) and learns patterns.
They train the tokenizer with three kinds of tasks at the same time:
- Reconstruction (rebuilding pixels):
- Goal: Turn the code back into the original image.
- Analogy: Zipping a photo and unzipping it so it looks the same.
- Trick used: First train with simple pixel and “perceptual” losses (to keep colors and textures right). Later fine-tune the decoder with a GAN loss to sharpen details.
- Self-supervised learning (understanding from images alone):
- Masked image modeling (MIM): Hide parts of the image and ask the model to guess them, like filling in missing puzzle pieces.
- Self-distillation: A “teacher” version of the model gives hints to a “student” version, teaching it consistent, meaningful features across different views of the image.
- Contrastive learning with text (image–text matching):
- Use pairs of images and captions (like “a cat on a sofa”).
- Train the model so the image code and the text code match when they belong together and don’t match when they’re random.
- Analogy: Pairing photos with the right descriptions so the model learns what “cat,” “sofa,” “sky,” etc., mean.
Important detail: They keep the generator’s training fixed and only improve the tokenizer’s pre-training. That way, any improvement in generated images comes from a better tokenizer code, not changes to the generator.
Main Findings and Why They Matter
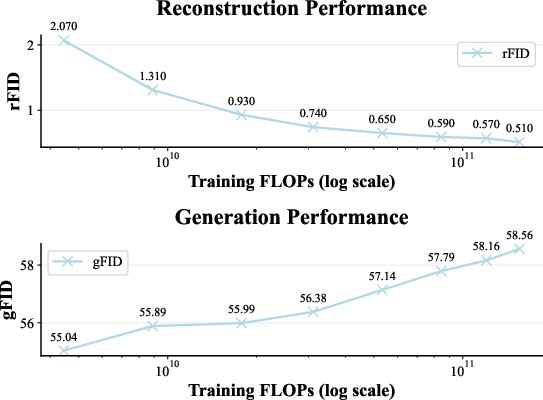
- Better pixel copying alone does not equal better generation:
- If you only train the tokenizer to rebuild images perfectly, the generator actually gets worse at making new pictures. The tokenizer learns lots of low-level details (like exact colors and edges) but not high-level meaning (like “this is a dog” or “a car on a street”).
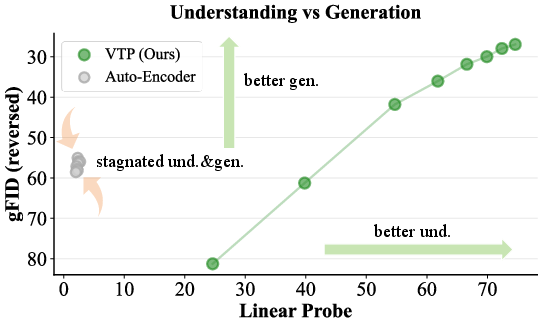
- Understanding drives generation:
- Teaching the tokenizer to understand images—through masked modeling, teacher–student training, and image–text alignment—makes the generator’s pictures noticeably better. The more the tokenizer understands, the better the generator performs.
- It scales well:
- With the new training mix (reconstruction + self-supervised + contrastive), using more compute, bigger models, and more data keeps improving results. In numbers:
- Up to 65.8% improvement in generation quality (FID) just by investing more compute in tokenizer pre-training.
- 4.1× faster training convergence for generation compared to advanced competitors.
- Strong understanding and reconstruction: around 78.2% zero-shot accuracy on ImageNet and a low reconstruction error (rFID ≈ 0.36).
- Combining tasks works best:
- Doing both image–text matching and self-supervised learning together (plus reconstruction) gave the strongest results. It made the tokenizer’s code both meaningful and detailed.
Why this matters: This shows a clear path to make generative image models better without changing their main training setup—just by preparing a smarter image code.
Implications and Impact
- Smarter pre-training = better art: If we teach the tokenizer to truly understand what’s in an image (not just copy pixels), the generator can make more realistic and meaningful pictures.
- Efficient scaling: Investing in larger datasets, bigger tokenizers, and more compute for tokenizer pre-training pays off. Unlike the old way, performance keeps improving as you scale.
- Simple upgrade path: You don’t need to change how you train the generator. Just swap in a better-pre-trained tokenizer, and generation quality improves.
- Future directions:
- Add more “understanding” tasks (like learning motion for video).
- Curate training data so the tokenizer learns special skills (e.g., text rendering, medical images), which could unlock better results for targeted generative tasks.
In short, the paper shows that giving the image “zipper” a brain—so it learns meaning as well as pixels—lets the AI artist paint better, faster, and keep improving as we scale up.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper that future researchers could address:
- External validity beyond ImageNet-256: The tokenizer’s benefits are only demonstrated with DiT trained on ImageNet at 256px. It is unclear whether the scaling and “understanding drives generation” findings transfer to higher resolutions (512/1024px+), diverse datasets (e.g., COCO, LAION, medical, satellite), and non-ImageNet domains.
- Conditioning generality: Experiments evaluate class-conditional/unconditional generation “without CFG” on ImageNet. The impact on text-to-image diffusion (prompt-conditioned), image editing, inpainting, and other conditioning types remains untested.
- Architectural generality of downstream models: The scaling benefits are shown for a single DiT configuration. Whether VTP improves training dynamics and ceilings for other generators (UNets, Rectified Flow Transformers, autoregressive image/video models, diffusion decoders) is unknown.
- Loss weighting sensitivity and schedules: The paper largely fixes loss weights (e.g., λ_rec=0.1, λ_clip/λ_ssl∈{0,1}). There is no systematic analysis of sensitivity, optimal schedules (e.g., ramping/annealing), or adaptive weighting (e.g., uncertainty weighting) across scales or training phases.
- Batch-size constraints and practicality: CLIP training uses extremely large batches (e.g., 16k), which limits reproducibility. Alternatives (e.g., memory banks, gradient caching, cross-batch negatives, hard-negative mining) and their effect on generative scaling are unexplored.
- Data quality and filtering transparency: Pretraining uses an “internally filtered” DataComp subset (277M). The filtering criteria, caption quality, language coverage, and licensing are not detailed, hindering reproducibility and analysis of how data quality/noise affects latent semantics and generation.
- Text encoder effects: A custom 12-layer text transformer is used, but the role of text encoder quality (pretrained vs from-scratch), tokenizer choice, multilingual support, and caption noise on downstream generation is not isolated or quantified.
- Latent bottleneck design space: Only d=64 and d=256 are examined. Systematic exploration of compression ratio (e.g., d∈{32,64,128,256,512,768}), patch sizes (f), hierarchical latents, spatial stride, and discrete vs continuous codes (VQ/RAE hybrids) is missing.
- Decoder design and two-stage training: The pixel decoder is a 4-layer ViT with a two-stage GAN fine-tuning while freezing the tokenizer. The impact of this freeze on latent semantics, potential drift, alternative decoders (conv, hybrid, diffusion-based decoders), and ablations of adversarial objectives are not reported.
- Theoretical underpinning vs correlation: The claim “understanding drives generation” is shown via empirical correlation plots, but there is no causal analysis that controls for confounders (e.g., reconstruction quality, batch size, data scale) or intervention studies (e.g., manipulate understanding metrics at fixed reconstruction).
- Metric coverage and standard usage: Generative evaluation focuses on FID without CFG; typical practice uses CFG, precision/recall, diversity, and human preference studies. The relationship between VTP gains and these broader metrics is unknown.
- Fairness of baseline comparisons: Results for baselines (VA-VAE, RAE, UniTok) are taken from original papers with differing data, compute, and training configs. A controlled reimplementation under identical budgets and datasets is missing to ensure apples-to-apples comparisons.
- High-resolution reconstruction fidelity: Reconstruction is primarily evaluated at 256px using rFID/PSNR. Fidelity, color accuracy, and texture preservation at higher resolutions, and their trade-offs against latent semantic richness, remain unexplored.
- Domain robustness and OOD generalization: How VTP latents behave under distribution shifts, OOD samples, corruptions, or adversarial inputs, and whether “semantic understanding” enhances robustness, is not studied.
- Interpretability and disentanglement of latents: Beyond linear probing and zero-shot classification, there is no analysis of spatial-semantic consistency, attribute disentanglement, or interpretable latent directions that affect generation.
- Joint end-to-end training with generators: The tokenizer is pre-trained and then used with fixed downstream DiT specs. Whether joint fine-tuning (or REPA-E-style end-to-end supervision) further improves ceilings or training efficiency is an open question.
- Compute–benefit trade-offs: While pretraining improves downstream FID and convergence, the total FLOPs cost, energy, training time, and memory trade-offs relative to alternative strategies (e.g., scaling the generator directly, using distilled latents) are not quantified.
- Stability analyses: Claims of GAN instability for ViT decoders and the stabilizing effect of QKNorm are not accompanied by quantitative stability metrics, gradient norm tracking, or ablations to confirm necessity and sufficiency.
- Negative side-effects and failure modes: The paper highlights artifacts in RAE (e.g., color shifts), but provides no systematic assessment of VTP’s own failure modes, category-specific degradation, or biases introduced by representation losses.
- Task diversity for “understanding” evaluation: Understanding is measured via ImageNet linear probing and zero-shot. Additional tasks (e.g., segmentation mIoU, detection AP, dense correspondence) could better capture spatial-semantic properties relevant to generation; these are absent.
- Scaling limits and diminishing returns: The observed scaling advantages (compute, parameters, data) extend to 10× compute, but eventual saturation points, diminishing returns, or non-monotonic behaviors at larger scales are not characterized.
- Multi-objective expansion: While CLIP+SSL+AE is proposed, other perceptual objectives (e.g., equivariance regularization, depth/surface normals, segmentation masks, motion cues for video) and principled ways to integrate them (conflict resolution, curriculum) are not explored.
- Cross-lingual and caption quality effects: If CLIP alignment contributes to generation, how do multilingual captions, noisy or short captions, and domain-specific text (e.g., typography, math, code) affect latent semantics and downstream generation?
- Compatibility with editing and controllability: It is unclear whether VTP latents improve controllable generation (e.g., precise attribute editing, masked editing, layout control), or how they interact with control signals (edges, depth, poses).
- Release gap for reproducibility: Although models are released, the internal data filtering and some hyperparameters/schedules are not fully specified. A reproducible recipe (data processing, augmentation specifics, loss implementations, batch construction) is needed.
- Negative mining and contrastive design choices: The CLIP objective uses in-batch negatives; exploration of hard-negative mining, debiased losses, temperature schedules, and cross-batch memory mechanisms on generative outcomes is missing.
- Downstream data interactions: The tokenizer is pre-trained on large-scale web data but the generator is trained on ImageNet. How matching or mismatched pretraining–downstream data distributions (and domain-specific tokenizer pretraining) affect generation is not studied.
- Speed at inference and memory footprint: VTP’s impact on inference latency, memory use, and throughput during generation—especially with larger decoders or higher-resolution latents—has not been reported.
- Continuous vs discrete latent trade-offs: The work focuses on continuous ViT AEs. Whether discrete tokenizers (VQ, hierarchical codebooks) or mixed discrete–continuous designs yield better controllability or compression for generation is an open question.
Practical Applications
Overview
The paper introduces VTP, a scalable pre-training framework for visual tokenizers that jointly optimizes reconstruction, self-supervised learning (MIM + self-distillation), and image–text contrastive learning (CLIP). The key empirical findings are:
- Understanding drives generation: latent spaces with stronger semantic structure yield better generative quality.
- Scalable pre-training: unlike reconstruction-only tokenizers, VTP’s generative performance scales with compute, parameters, and data.
- Practical benefits: faster convergence for downstream DiT training (4.1×), significant FID gains (up to 65.8%) by only improving tokenizer pre-training, and competitive understanding/reconstruction (78.2% zero-shot, 0.36 rFID).
Below are actionable applications grouped by deployment timeline.
Immediate Applications
These can be piloted or deployed with current tools, using released checkpoints and standard DiT/LDM training recipes.
- [Software/AI tooling] Drop-in replacement tokenizer for diffusion pipelines
- Use case: Replace existing VAEs in Latent Diffusion/DiT pipelines to improve FID and speed up convergence without changing generator training specs.
- Tools/workflow: Integrate VTP encoder/decoder into Stable Diffusion/DiT codebases; keep DiT config fixed; adopt two-stage reconstruction (L1 + perceptual pre-train, then GAN fine-tune for decoder); adopt batch-sampling strategy (CLIP ≈16k, SSL ≈4k, Rec ≈2k) and low reconstruction weight (e.g., λ_rec≈0.1).
- Dependencies/assumptions: Sufficient GPU memory for large-batch contrastive learning (use gradient accumulation if needed); availability of text encoder; compatibility testing with existing schedulers/UIs (e.g., ComfyUI, AUTOMATIC1111).
- [Content/Media, Marketing, Gaming] Higher-quality, semantically aligned image generation
- Use case: Produce brand-consistent visuals, ad creatives, game assets, and styling variants with better text–image alignment and finer details out of the box.
- Products: “VTP-powered” image generation SaaS or plugins for content design suites; template libraries with improved latent control.
- Dependencies/assumptions: Optional light finetuning on brand/product data; content safety filters; data licensing for any continued pre-training.
- [E-commerce/Retail] Scalable product imagery and background generation
- Use case: Bulk-generate catalog imagery, backgrounds, and consistent variants with improved fidelity and less prompt iteration.
- Workflow: Fine-tune DiT on category-specific images while keeping the VTP tokenizer frozen; automate batch rendering for product lines.
- Dependencies/assumptions: Access to de-duplicated, curated product datasets; brand guideline constraints.
- [Education/Publishing] Automated illustration and diagram generation with higher semantic faithfulness
- Use case: Create course figures, step-by-step visuals, and contextualized examples from text prompts.
- Workflow: Prompt-conditioned generation with stricter semantic control due to better latent alignment; integrate into LMS/authoring tools.
- Dependencies/assumptions: Institutional content policies; human-in-the-loop review.
- [Robotics/Autonomy, AV Simulation] Better synthetic data for perception training
- Use case: Generate rare scene variations (weather, occlusions, edge cases) with semantically coherent structure for training object detection/segmentation.
- Workflow: Domain-adapt the generator to sensor characteristics (e.g., fisheye, multispectral) while retaining VTP tokenizer; use latent controls for scene composition.
- Dependencies/assumptions: Domain shift addressed via targeted finetuning; calibration to sensor models.
- [Healthcare (non-diagnostic, research-only)] Synthetic data augmentation for medical imaging research
- Use case: Improve class balance and privacy-preserving augmentation for tasks like organ/tissue segmentation in research settings.
- Workflow: Pre-train or adapt VTP on de-identified, institution-approved datasets; freeze tokenizer, fine-tune DiT on domain images.
- Dependencies/assumptions: Strict IRB/ethics oversight; domain shift (medical vs. natural images) necessitates domain pre-training; no clinical deployment without validation.
- [MLOps/Infrastructure] Training cost rebalancing and faster iteration cycles
- Use case: Shift compute from repeated expensive generator training to a stronger reusable tokenizer that reduces downstream epochs (4.1× faster convergence reported).
- Workflow: Maintain a versioned “Tokenizer Model Zoo”; standardize DiT specs; run ablations only on tokenizer pre-training scale/data rather than generator hyperparameters.
- Dependencies/assumptions: Centralized governance of tokenizer versions; reproducibility checks; dataset lineage.
- [Search/Retrieval, Recommendation] Latent features for zero-shot tagging and multimodal search
- Use case: Use tokenizer bottleneck features (78.2% zero-shot ImageNet) for image tagging, similarity search, and prompt-based retrieval.
- Workflow: Index images by VTP latent codes; support text queries via shared CLIP-like embedding.
- Dependencies/assumptions: Domain calibration for niche taxonomies; evaluation beyond ImageNet.
- [Data/Storage] Efficient dataset preparation and caching via latents
- Use case: Store training sets in tokenizer latents to speed subsequent generator training runs and enable lightweight transformations.
- Workflow: Pre-encode large corpora; cache latents and metadata for MLOps pipelines; reconstruct on-demand for audits.
- Dependencies/assumptions: Storage policies for latent representations; decoder fidelity targets (rFID/PSNR thresholds).
- [Policy/Compliance (organizational)] Internal governance for scaling generative systems
- Use case: Establish internal standards to invest compute in tokenizer pre-training (better scaling returns) and to track environmental impact and data governance.
- Workflow: Compute allocation guidelines; dataset documentation and licensing audits; model cards detailing tokenizer scaling and performance impacts.
- Dependencies/assumptions: Cross-functional oversight (legal, privacy, sustainability); monitoring for misuse amplification due to higher-quality generation.
Long-Term Applications
These require further research, domain adaptation, larger-scale data, or productization.
- [Healthcare (clinical), Scientific Imaging] Domain-specialized tokenizers for regulated use
- Use case: Tokenizers pre-trained on de-identified medical scans (CT/MRI, histopathology) to improve generative realism for simulation, education, and eventually clinical decision support.
- Products: “Med-VTP” modules validated for specific modalities; synthetic cohorts for rare conditions.
- Dependencies/assumptions: Extensive clinical validation; regulatory approval; rigorous bias and artifact analysis; secure data pipelines.
- [Video/3D/AR-VR] Tokenizers that capture motion and geometry
- Use case: Extend VTP to video tokenizers encoding motion semantics for video generation; 3D-aware tokenizers for asset creation and XR scene synthesis.
- Products: Motion-aware video generators, 3D asset pipelines for games/film, AR content authoring.
- Dependencies/assumptions: Large-scale video/3D datasets with captions; scalable objectives for temporal consistency; decoding speed for interactive use.
- [Edge/On-device AI] Smaller generators powered by stronger tokenizers
- Use case: Deploy compact DiT/LDM models on mobile/embedded devices by offloading semantic load into a high-quality tokenizer.
- Products: On-device creative apps, camera filters with generative capabilities, offline design tools.
- Dependencies/assumptions: Efficient on-device inference for ViT-based tokenizers and decoders; memory-optimized batch strategies.
- [Standardization/Benchmarks] Tokenizer-centric scaling protocols and metrics
- Use case: Establish community benchmarks for tokenizer pre-training (e.g., zero-shot, rFID, generator FID under fixed DiT spec) and reporting standards.
- Products: Open leaderboards; standardized validation suites; audit checklists for tokenizer pre-training.
- Dependencies/assumptions: Community adoption; shared datasets with clear licenses; consistent evaluation code.
- [Safety/Security] Latent-level safety and provenance controls
- Use case: Integrate watermarking, NSFW/abuse filters, and bias mitigation directly into the tokenizer’s latent space.
- Products: “Safety-by-design” tokenizers; provenance-preserving latents for content authenticity frameworks.
- Dependencies/assumptions: Robust watermarking under editing; standardized detection protocols; minimal impact on generation quality.
- [Synthetic Data Economy] Tokenizer-as-a-Service (TaaS) and vertical model factories
- Use case: Offer managed services that pre-train vertical-specific tokenizers (fashion, interiors, sat-imagery) to accelerate downstream generator training for clients.
- Products: Managed pre-training jobs, domain-adapted checkpoints, SLAs around FID/speed.
- Dependencies/assumptions: Legal rights to train on client/third-party data; privacy-preserving setups (federated/DP where needed); cost models for large-batch contrastive training.
- [Compression/Streaming] Learned codecs for semantically faithful media
- Use case: Use VTP-like tokenizers as perceptual codecs to stream or archive content as latents with high-fidelity reconstruction.
- Products: Latent-based image/video streaming; hybrid rendering pipelines that decode on GPU.
- Dependencies/assumptions: Real-time decoding; encoder–decoder standardization; compatibility with existing media stacks.
- [AutoML for Multi-objective Pre-training] Automatic balancing of losses and batch schedules
- Use case: Optimize λ_rec/λ_ssl/λ_clip and batch allocation to meet task-specific targets (e.g., maximize generator FID under compute caps).
- Products: AutoML controllers for tokenizer pre-training; dashboards for Pareto fronts (understanding vs. reconstruction vs. generation).
- Dependencies/assumptions: Robust hyperparameter search at scale; reproducibility across data mixtures.
- [Public Policy] Compute- and data-governance frameworks centered on tokenizer scaling
- Use case: Policy guidance that recognizes tokenizer pre-training as a primary lever for generative capability, shaping environmental reporting, content risk assessment, and dataset governance.
- Products: Standards for compute disclosures; dataset documentation norms (provenance, consent); sectoral risk assessments.
- Dependencies/assumptions: Multistakeholder coordination; alignment with existing AI governance (e.g., model cards, data statements).
Notes on feasibility across applications:
- Scaling dependencies: VTP’s benefits appear when pre-training uses large, diverse data with effective CLIP/SSL objectives and large batches; limited compute or poor captions can bottleneck gains.
- Domain shift: For specialized sectors (healthcare, remote sensing), domain-specific pre-training is likely necessary to realize benefits.
- Ethical/legal: Data licensing, privacy, and safety considerations become more important as generation quality improves.
- Integration risk: Decoder GAN fine-tuning and inference-time performance should be profiled to avoid regressions in speed or artifacts.
Glossary
Autoencoder: An unsupervised learning model that attempts to convert input data into a concise latent space and then reconstruct the input from this compressed representation. "Typically, visual tokenizers are pre-trained in a separate stage using a reconstruction objective."
Contrastive Learning: A technique used in training models by contrasting positive pairs (pairs that should be similar) against negative pairs (pairs that should not be similar) to learn latent space representations. "First, cross-modal image-text contrastive learning is employed to instill a global semantic understanding."
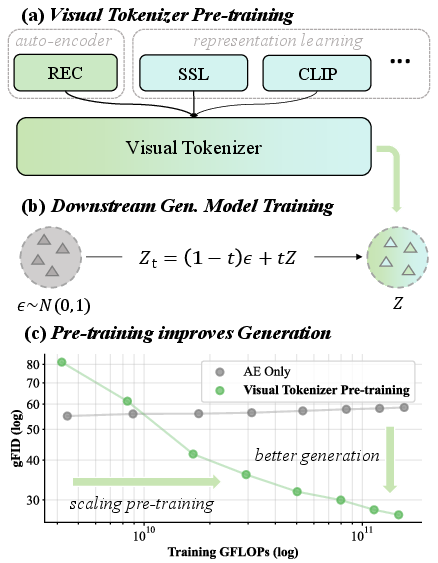
Diffusion Model: A type of generative model that incrementally refines samples via the diffusion process, which is essentially a Markov chain of slight changes. "Critically, while keeping the diffusion model (e.g., DiT~\cite{dit}) training configuration fixed, our method improves generation solely by scaling the tokenizer's pre-training."
EMA (Exponential Moving Average): A method used for maintaining a stable estimate of model parameters by weighing recent observations more heavily than older ones. "Encoder features are leveraged by the text encoder, EMA teacher, and pixel decoder to facilitate their distinct training objectives."
FLOPS (Floating Point Operations Per Second): A unit of computational performance or capability indicating how many floating point calculations a hardware can perform per second. "We observe a strong positive correlation between the semantic quality of the latent space and its generative performance, which improves steadily as we scale up training compute (FLOPS)."
Latent Diffusion Model (LDM): A variant of diffusion models that use a latent space learned by a visual tokenizer to streamline the generative process. "Latent Diffusion Models (LDMs)~\cite{ldm} employ a visual tokenizer, such as a VAE~\cite{vae}, to compress visual signals into a latent space."
Latent Space: A representation space where data is compressed into a more abstract or reduced form, allowing easier manipulation for tasks like generation or reconstruction. "The quality of the latent space in visual tokenizers (e.g., VAEs) is crucial for modern generative models."
Linear Probing: An evaluation technique where simple models are trained on top of deep learning representations to test their utility as features for downstream tasks. "For understanding evaluation, we evaluate representation performance on ImageNet using linear probing."
Mask Image Modeling: A self-supervised learning approach where parts of an image are masked and the model is tasked with predicting these masked components to build robust representations. "Notably self-distillation and mask image modeling~\cite{mae, ibot, dino, dinov2}, to enhance the model's spatial-semantic perception."
Perceptual Loss: A loss function used in training models, emphasizing the perceptual similarity between input and output images, rather than pixel-wise accuracy. "A composite loss function comprising the loss and a perceptual loss $\mathcal{L}_{\text{perceptual}$~\cite{lpips} between and ."
Pre-training: The process of training a model on a preliminary task or set of data, intending to establish useful representations for subsequent tasks. "We present VTP, a unified visual tokenizer pre-training framework, pioneering the joint optimization of image-text contrastive, self-supervised, and reconstruction losses."
Reconstructive Loss: The error between input data and its reconstruction through a model, often minimized during the training of autoencoders. "The reconstruction task is challenged by the poor compatibility of GAN loss~\cite{vqgan} with the ViT architecture, which causes large gradient norms and low training stability."
Self-distillation: A technique where a model is trained using its own predictions over multiple iterations or views, forming part of self-supervised learning. "Methods like MAE~\cite{mae} and BEiT~\cite{beit} adopt masked image modeling (MIM), training models to reconstruct masked patches."
Self-supervised Learning: A type of machine learning paradigm where models are trained by using the data's inherent structure, without relying on labeled outcomes. "Another branch, self-supervised learning (SSL), learns directly from unlabeled data."
Transformer: A model architecture that primarily relies on attention mechanisms to process data sequences, originally developed for natural language processing tasks. "Building on the flexibility of the ViT architecture for representation learning, we integrate a suite of diverse learning objectives."
Visual Tokenizer: A model that converts visual data into tokens in latent space, making it suitable for processing by generative models. "Critically, while keeping the diffusion model (e.g., DiT~\cite{dit}) training configuration fixed, our method improves generation solely by scaling the tokenizer's pre-training to learn a better-structured latent space."
Vision Transformer (ViT): A type of image model employing transformer architectures, using patches of images as tokens for processing. "Our core contribution is realized in the visual tokenizer architecture, built upon ViT."
Collections
Sign up for free to add this paper to one or more collections.

