- The paper introduces a reinforcement learning framework that converts noisy multimodal queries into concise text, boosting retrieval accuracy.
- The approach employs FORGE for denoising via comprehensive visual captioning and RL training, paired with LENS for effective text retrieval.
- Empirical results show a 46% reduction in the performance gap, with complementary gains in nDCG@10 when integrated with existing retrievers.
BRIDGE: Multimodal-to-Text Retrieval via Reinforcement-Learned Query Alignment
Problem Statement and Motivation
The proliferation of multimodal queries—those integrating both natural language and visual content—exposes crucial deficiencies in current retrieval systems, particularly when the target corpus is text-only. On benchmarks like MM-BRIGHT, vision-language embedding solutions systematically underperform compared to text-only retrievers, with leading multimodal encoders achieving 27.6 nDCG@10, well below the strongest text retrievers at 32.2. The paper "BRIDGE: Multimodal-to-Text Retrieval via Reinforcement-Learned Query Alignment" (2604.07201) provides a systematic analysis demonstrating that this discrepancy is primarily due to the noisy entanglement of conversational, visual, and intent signals within raw multimodal queries, not model capacity limitations of existing retrievers.
BRIDGE Framework Overview
The BRIDGE architecture explicitly addresses the query representation bottleneck. The system is decomposed into two coordinated yet modular components: FORGE (Focused Retrieval Query Generator) and LENS (Language-Enhanced Neural Search). The core pipeline transduces a multimodal query into a succinct text string optimized for dense retrieval, eliminating reliance on multimodal encoders at inference.
The process begins with comprehensive visual captioning of the query image using GPT-4o. The resultant caption, concatenated with the raw text query, is handed to FORGE, a Qwen2.5-7B-Instruct-based LLM trained with reinforcement learning to distill intent and denoise extraneous content. The cleansed query then enters LENS—a reasoning-optimized bi-encoder retriever—yielding robust performance across diverse domains.
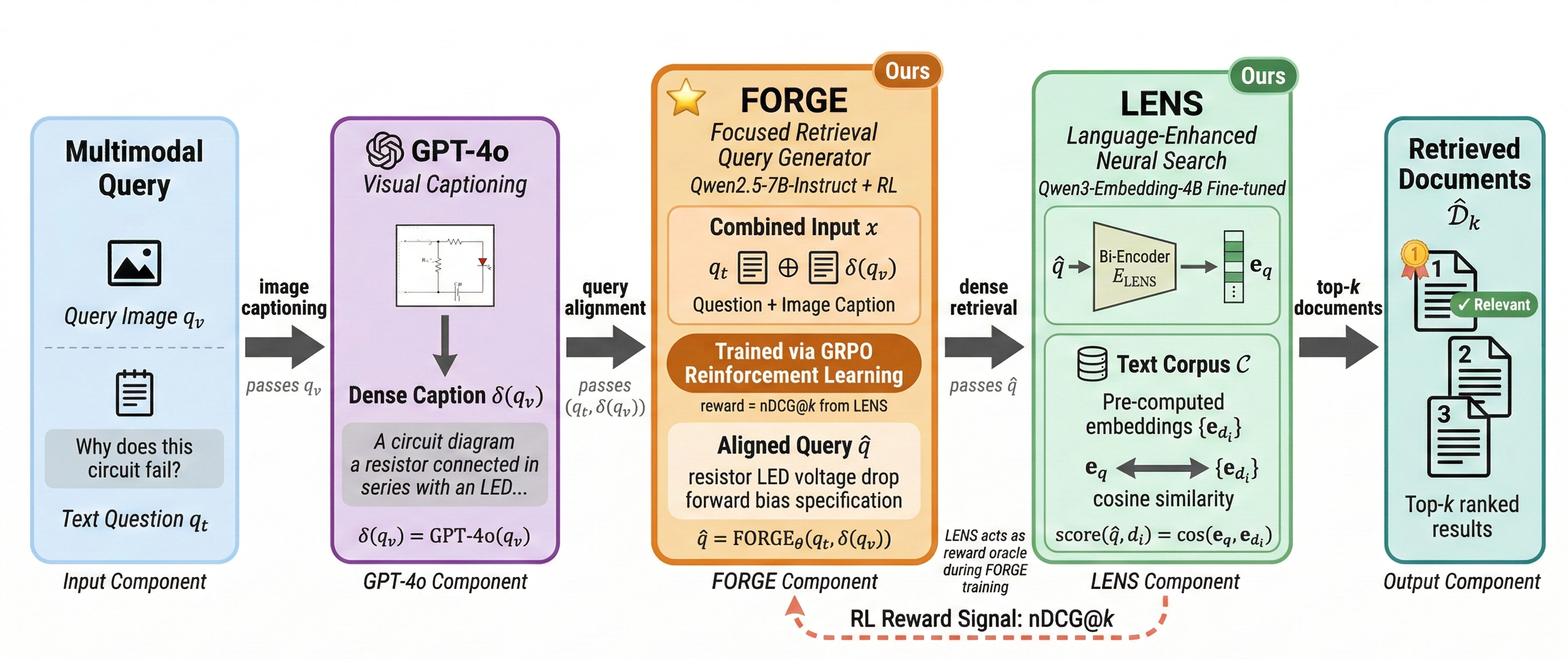
Figure 1: Overview of the BRIDGE framework. Multimodal queries are mapped to dense, optimized text strings for retrieval with LENS, removing the need for multimodal encoders at inference.
FORGE: Reinforcement-Learned Query Alignment
FORGE is differentiated from typical query rewriting approaches by its direct optimization for downstream retrieval quality using reinforcement learning. Specifically, the policy network (FORGE) is rewarded for generating compact queries that allow LENS to rank ground-truth documents highly (nDCG@k-based reward). Training employs Group Relative Policy Optimization (GRPO), facilitating robust and stable convergence without referencing human-annotated rewrites. Ablations demonstrate that this RL-based training yields superior results to both supervised rewriting and zero-shot prompting, elevating retrieval robustness even with smaller models.
Empirically, the backbone selection for FORGE is significant but non-monotonic with respect to model scale. Llama-3.2-11B achieves the highest mean nDCG@10 (31.0), surpassing both larger and smaller Qwen2.5 variants. Nevertheless, Qwen2.5-7B is preferred due to optimal cost-performance.
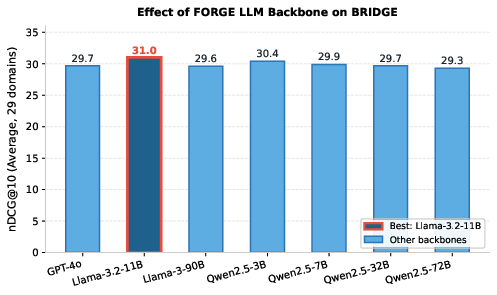
Figure 2: Effect of FORGE LLM backbone on BRIDGE performance. Llama-3.2-11B achieves 31.0 nDCG@10, with Qwen2.5-7B providing optimal efficiency at 29.7.
Query Denoising and Modality Gap Closure
A primary insight validated by extensive experiments is that query alignment—rather than retriever scaling or multi-modal embedding complexity—is the missing factor for effective multimodal-to-text retrieval. By transforming multimodal queries into retrieval-optimized text, BRIDGE closes a significant portion (46%) of the performance gap between the best vision-language and text-only retrievers. This is validated by the strong nDCG@10 improvements in highly visual or reasoning-dependent domains such as Ubuntu, Biology, and Travel, with BRIDGE achieving up to 50.4 in Ubuntu and showing marked improvements where visual cues carry dense, domain-specific information.
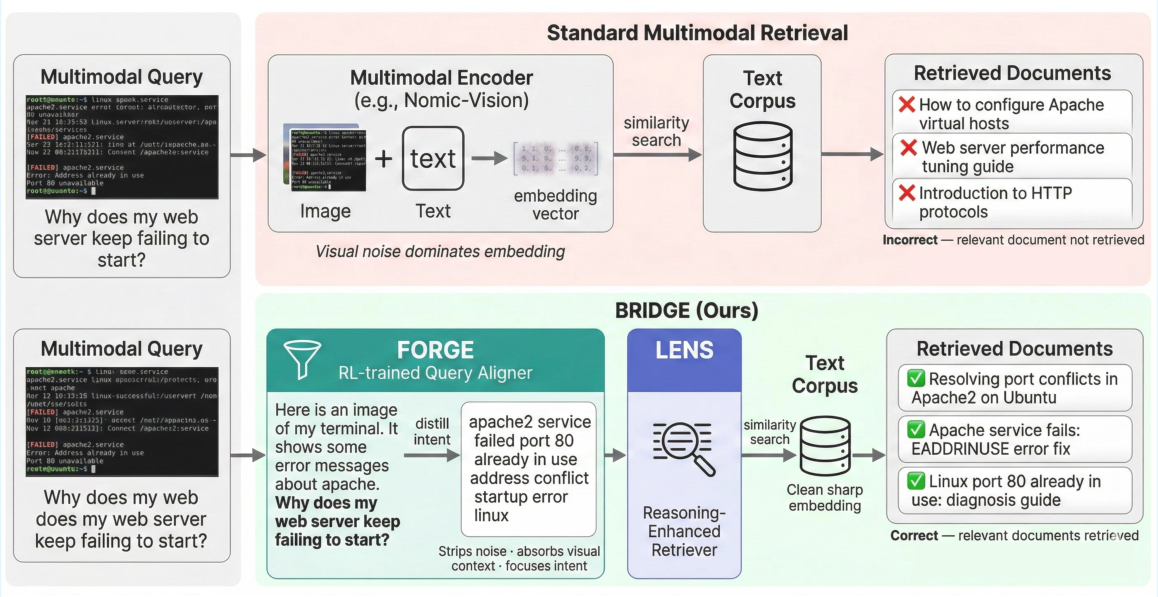
Figure 3: An illustrative case showing how raw multimodal queries yield noisy embeddings, while FORGE distillation enables correct retrieval via LENS.
Component and Baseline Analysis
Component ablations expose the relative contributions of each system part. Captioning only (LENS + GPT-4o) already boosts relevance by +2.4 nDCG@10 over raw text alone. Supervised rewriting adds +0.7, while full RL-trained FORGE secures a +1.2 point gain, providing 29.7 total. Comparison with alternative rewriting paradigms (HyDE, Query2Doc) shows these approaches degrade with noisy multimodal inputs, often amplifying irrelevant content.
Furthermore, FORGE demonstrates plug-and-play alignment efficacy: paired atop existing retrievers (e.g., BM25, Nomic-Vision, GME-7B), it leads to complementary gains of up to +7.3 nDCG@10, confirming the retriever-agnostic value of the denoised query approach. Notably, when applied atop Nomic-Vision, performance reaches 33.3 nDCG@10—surpassing the best text-only system—though this configuration reintroduces the need for a multimodal encoder at inference.
Implications and Future Directions
The empirical evidence provided decisively supports the conclusion that multimodal-to-text retrieval is fundamentally constrained by query representation noise, not the absence of vision-LLM capacity. BRIDGE offers a modular, scalable, encoder-free solution, making it compelling for large-scale, resource-sensitive deployments where multimodal inference is prohibitive.
Theoretically, this work reframes the modality gap as a solvable pre-processing problem. Practically, it enables leveraging advances in language-only retrieval architectures without sacrificing multimodal query support. Future research may extend this strategy to multi-hop, open-domain, and more interactive retrieval paradigms, further closing the residual gap to the text-only upper bound.
Conclusion
BRIDGE demonstrates that reinforcement-learned query alignment is the dominant missing factor in the multimodal-to-text retrieval pipeline. By distilling multimodal user queries into intent-focused, dense-retrieval-optimized text strings and utilizing reasoning-optimized retrievers, it reduces the domain gap between vision-language and text retrieval by nearly half. The results and methodology in this work establish a robust foundation for further advances in practical, scalable knowledge-intensive multimodal interfaces (2604.07201).