- The paper introduces MARVEL, a multimodal retrieval pipeline that integrates LLM query expansion, a reasoning-aware retriever, and chain-of-thought reranking.
- The paper demonstrates significant performance improvements with up to 40.8 nDCG@10 on MM-BRIGHT by addressing underspecified queries and similarity-only ranking.
- The paper highlights a modular design enabling plug-and-play enhancements and suggests future directions for open-source LLM optimization and end-to-end fine-tuning.
MARVEL: Multimodal Adaptive Reasoning-Intensive Pipeline for Expand-Rerank and Retrieval
Motivation and Problem Characterization
Multimodal retrieval over textual corpora is an essential component of numerous knowledge-intensive tasks, including retrieval-augmented generation and agentic systems. Recent advances in vision-LLMs (VLMs) have yielded strong visual-text alignment, but these approaches consistently underperform on benchmarks requiring genuine cross-modal reasoning, notably MM-BRIGHT. This is a reasoning-intensive multimodal retrieval benchmark where the best standalone VLM achieves only 27.6 nDCG@10, trailing behind strong text-only retrievers.
Three compounding failures are identified:
- Underspecified Queries: Multimodal queries often conflate visual description, conversational noise, and retrieval intent, corrupting the embedding.
- Weak Retrieval: Standard encoders are not trained for abstract reasoning required by complex multimodal queries.
- Similarity-Only Ranking: Candidates are ranked purely by embedding similarity, without explicit reasoning about relevance.
Existing approaches tackle at most one failure in isolation, failing to produce coherent solutions for reasoning-intensive multimodal retrieval.
MARVEL Pipeline Architecture
MARVEL introduces a unified pipeline integrating LLM-driven query expansion, a reasoning-enhanced dense retriever (MARVEL-Retriever), and chain-of-thought reranking using GPT-4o, with optional multi-pass reciprocal rank fusion. Four stages constitute the pipeline:
- Visual Captioning: The query image is captioned via GPT-4o to yield a domain-rich textual description.
- Query Expansion: The combined multimodal context is expanded by an LLM into a retrieval-dense, terminology-rich representation.
- MARVEL-Retriever: Fine-tuned on complex cross-modal queries, MARVEL-Retriever encodes the expanded queries for dense retrieval.
- Chain-of-Thought Reranking: GPT-4o evaluates candidates step-by-step, optionally aggregating multiple reranking passes via reciprocal rank fusion.
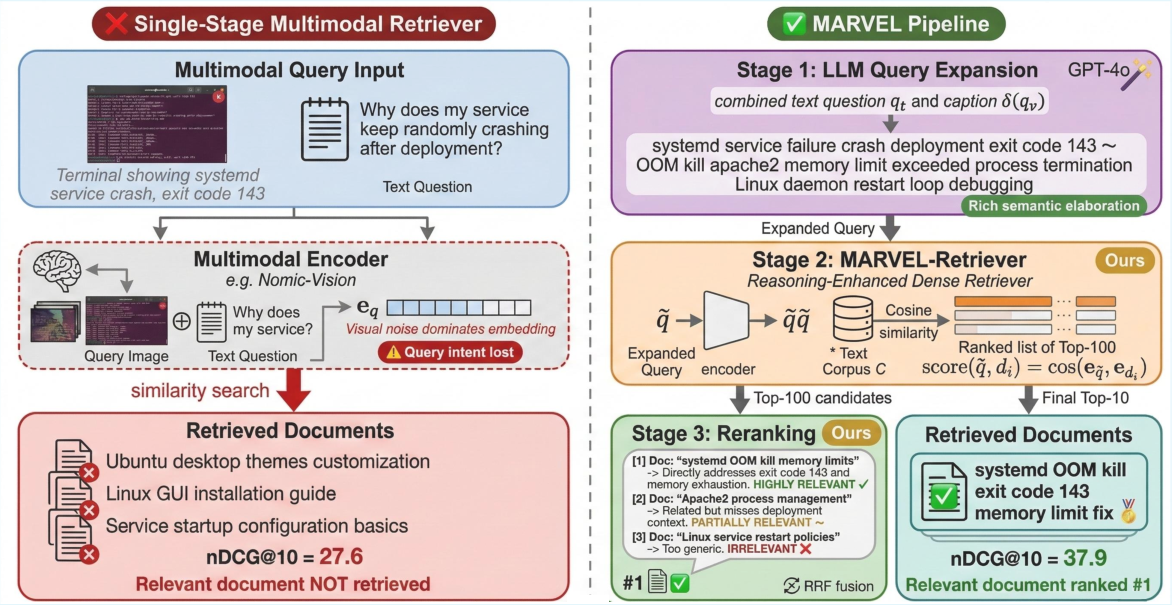
Figure 1: Example contrasting failure of single-stage multimodal retrievers and MARVEL’s multi-stage intent expansion, reasoning-driven retrieval and chain-of-thought reranking.
Figure 2: MARVEL pipeline overview, visualizing the sequential stages from multimodal query input through captioning, LLM-driven elaboration, retrieval, and chain-of-thought reranking.
Methodological Innovations
MARVEL advances the field with three key innovations:
- LLM Query Expansion: Explicit elaboration of complex user intent is performed, producing queries dense in relevant terminology and context. This drastically increases recall at retrieval.
- Reasoning-aware Retriever: MARVEL-Retriever is specifically fine-tuned to encode the outputs of the expansion stage; contrastive learning is applied with hard negatives drawn from reasoning-intensive domains.
- Chain-of-Thought Reranking: GPT-4o provides stepwise reasoning over candidate documents, enabling high-precision relevance evaluation missed by embedding-based ranking. Reciprocal rank fusion mitigates variance in LLM outputs.
Experimental Evaluation
MARVEL is evaluated on MM-BRIGHT, comprising 2,803 queries across 29 technical domains (from STEM, medicine, law, and engineering, to humanities and applied fields). The ablations and comparative experiments are thorough:
- Per-domain Results: MARVEL obtains 37.9 nDCG@10, beating Nomic-Vision (best multimodal baseline, 27.6) by +10.3 points and outperforming all single-stage baselines in 27 of 29 domains.
- Component Ablation: Captioning yields +2.6, expansion +4.5, single-pass reranking +3.7, and double-pass RRF +1.7 point gains, confirming additive value of each stage.
- Retrieval Depth (K0): MARVEL continues to outperform baselines even with shallow reranking (e.g., at K0=20, MARVEL achieves 34.1 vs. Nomic’s 27.6). Performance peaks at K0=100 (default, 37.9), plateaus at K0=200 (40.8), balancing API cost and latency.
(Figure 3)
Figure 3: MARVEL nDCG@10 vs. candidate retrieval depth, showing monotonic improvement and substantial gains vs. Nomic-Vision baseline.
- Plug-and-Play Gains: MARVEL expansion and reranking applied to diverse base retrievers consistently produce large gains (e.g., BM25 +10.7, GME-7B +11.1, Nomic-Vision +7.6, MARVEL-Retriever +12.5).
- Query Expansion Comparison: Conventional expansion methods (HyDE/Query2Doc) drastically underperform unless image captions are appended, and even then, MARVEL expansion is substantially superior (36.2 vs. 21.3/23.1).
Technical and Practical Implications
MARVEL demonstrates that the primary bottleneck in multimodal retrieval is not visual encoding, but reasoning capacity. Even state-of-the-art vision-language encoders are dwarfed by gains achieved through explicit intent elaboration and stepwise LLM-driven reranking. The results indicate that retrieval precision is fundamentally a pipeline problem, not merely a model scaling issue.
Practically, MARVEL’s plug-and-play architecture is retriever-agnostic, facilitating deployment with diverse dense or sparse base retrievers. The synergy between expansion and reranking yields consistent improvements, even when integrated atop strong baselines.
Theoretically, the pipeline underscores the importance of modular reasoning layers in multimodal retrieval, promoting future research in joint optimization of elaboration and retrieval modules, domain-specialized expansion prompts, and fully open-source LLM deployment for cost efficacy.
Future Directions
- Replacement of commercial LLMs (GPT-4o) with open-source alternatives in expansion/reranking to reduce inference latency and cost.
- Joint end-to-end fine-tuning of MARVEL-Retriever coupled with the LLM expansion stage for further performance amplification.
- Extension to multi-image and video retrieval scenarios.
Conclusion
MARVEL establishes a new paradigm for reasoning-intensive multimodal retrieval: unified expansion, retrieval, and reranking outperform all embedding-only approaches. Strong numerical evidence confirms the additive benefit of each stage, the retriever-agnostic character of the pipeline, and the critical role of explicit reasoning in complex multimodal retrieval settings. This framework sets a foundation for subsequent research in modular reasoning pipelines, open-source LLM optimization, and generalization to broader multimodal scenarios (2604.07079).