M3DR: Towards Universal Multilingual Multimodal Document Retrieval
Abstract: Multimodal document retrieval systems have shown strong progress in aligning visual and textual content for semantic search. However, most existing approaches remain heavily English-centric, limiting their effectiveness in multilingual contexts. In this work, we present M3DR (Multilingual Multimodal Document Retrieval), a framework designed to bridge this gap across languages, enabling applicability across diverse linguistic and cultural contexts. M3DR leverages synthetic multilingual document data and generalizes across different vision-language architectures and model sizes, enabling robust cross-lingual and cross-modal alignment. Using contrastive training, our models learn unified representations for text and document images that transfer effectively across languages. We validate this capability on 22 typologically diverse languages, demonstrating consistent performance and adaptability across linguistic and script variations. We further introduce a comprehensive benchmark that captures real-world multilingual scenarios, evaluating models under monolingual, multilingual, and mixed-language settings. M3DR generalizes across both single dense vector and ColBERT-style token-level multi-vector retrieval paradigms. Our models, NetraEmbed and ColNetraEmbed achieve state-of-the-art performance with ~150% relative improvements on cross-lingual retrieval.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about building a smarter, fairer “search engine” for documents that works across many languages. Instead of relying only on typed text, it looks at the actual images of document pages (including layouts, charts, and fonts) and connects them with questions written in any language. The system is called M3DR, and the authors built two new models—NetraEmbed and ColNetraEmbed—to make this possible.
What were the researchers trying to do?
They asked a simple question: Can we make a document search system that:
- works well for documents in many different languages and scripts (like English, Hindi, Arabic, Chinese, etc.),
- understands both the words and the visual look of the page (not just plain text),
- and stays fast and easy to use at large scale?
How did they do it? (Methods in everyday language)
Think of search as matching “fingerprints”:
- The model turns a question and a document page into special number lists called “embeddings”—like unique fingerprints.
- If a question and a page talk about the same thing, their fingerprints should look similar.
To build and test this system, they did four main things:
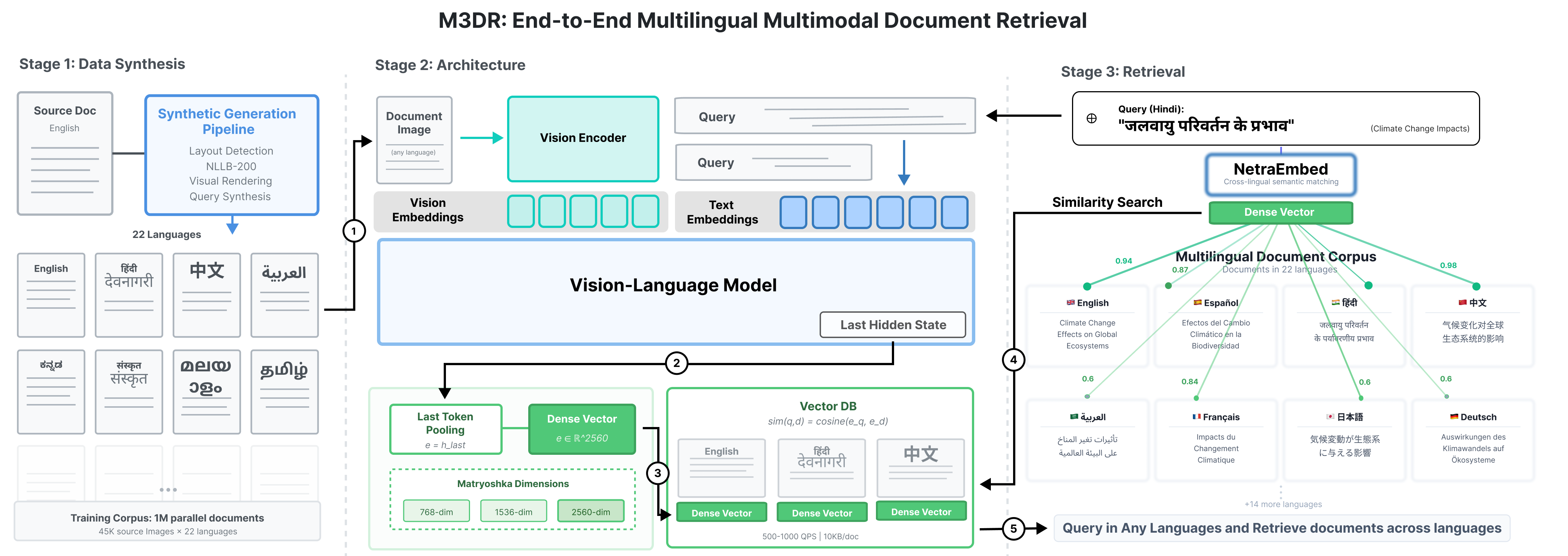
1) Created training data across 22 languages
- They started with many English document pages (like research papers, reports, slides).
- They used smart tools to detect where text and images are on the page.
- They translated the content into 22 different languages while keeping the original layout and look (fonts, left-to-right or right-to-left, etc.), then re-rendered the pages. That way, a translated page still “looks” like a real document in that language.
- They generated lots of practice questions (like “What is the main topic?”) using advanced AI models that can read images (such as Llama Vision). This produced about 1 million pairs of “document image + question” across languages.
2) Built a new benchmark to test models
- They made Nayana-IR, a large test set that checks performance in:
- monolingual search: question and document in the same language,
- cross-lingual search: question in one language, document in another.
- It covers 22 languages across different script families (Latin, Devanagari, Arabic, CJK like Chinese/Japanese/Korean, and more).
3) Trained two kinds of models
- NetraEmbed: a “single-vector” model. It turns every page and question into one compact fingerprint. This is very fast and memory-friendly—great for big databases.
- ColNetraEmbed: a “multi-vector” model. It keeps many small fingerprints per page, which can capture fine details, but uses more memory and time.
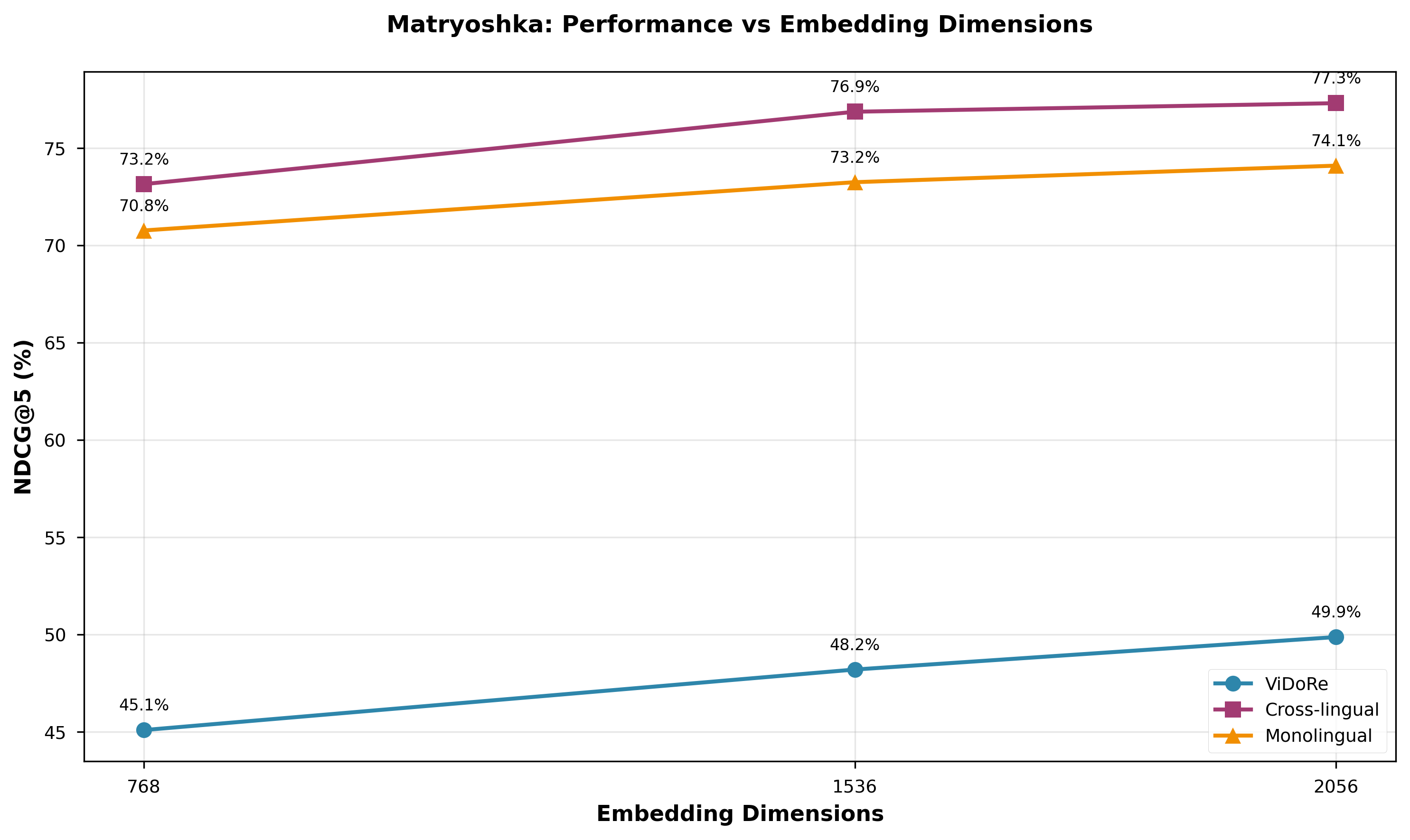
They also used a neat idea called “Matryoshka representation learning” (like nested Russian dolls): the fingerprint can be cut to different sizes (small, medium, full) after training. Smaller versions use less space and are still accurate.
4) Taught the models to match across languages
- They used contrastive learning (imagine a training game: pull true pairs closer together and push wrong pairs apart) so the model learns that a Hindi question and an English-looking page about the same topic still belong together.
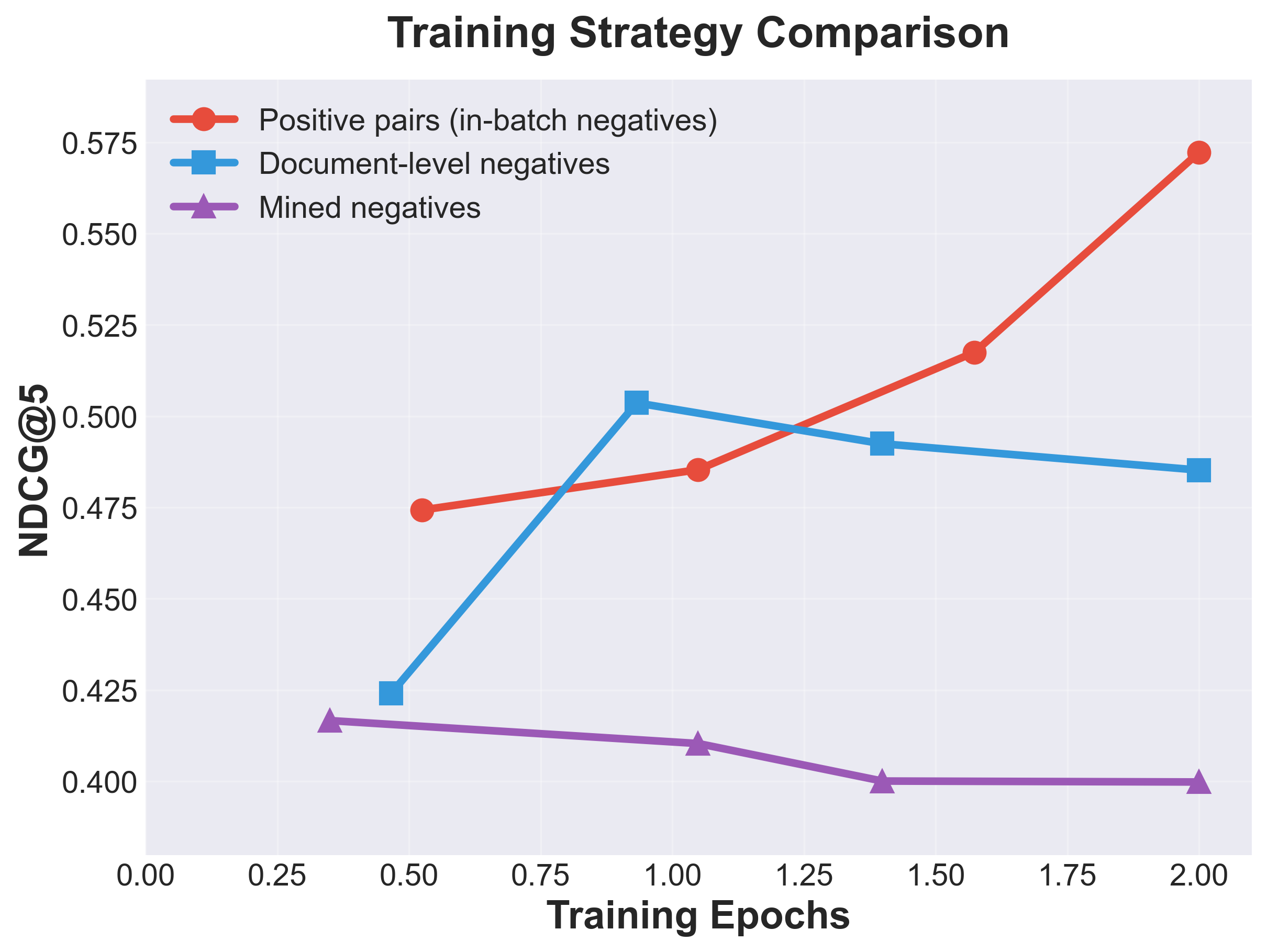
- Surprisingly, simple training with “in-batch” negatives (comparing with other examples in the same training batch) worked better than more complicated “hard negative” tricks.
What did they find? (Main results)
Here are the key takeaways, presented simply:
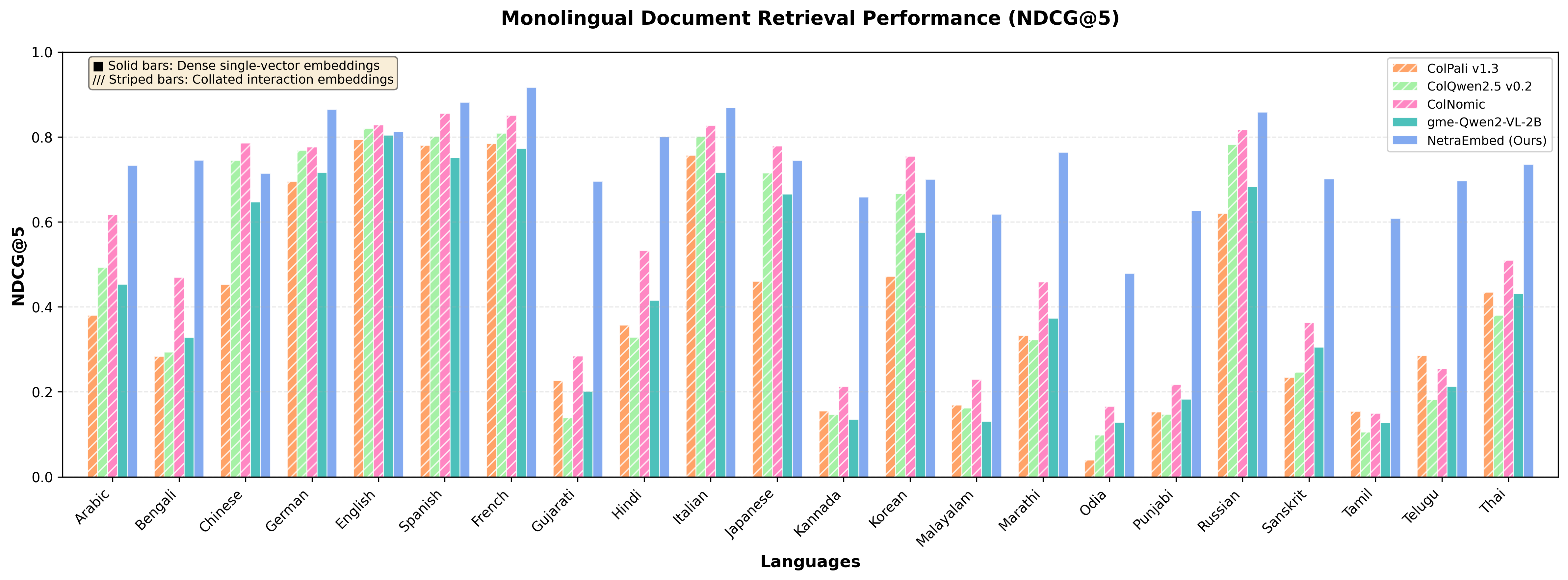
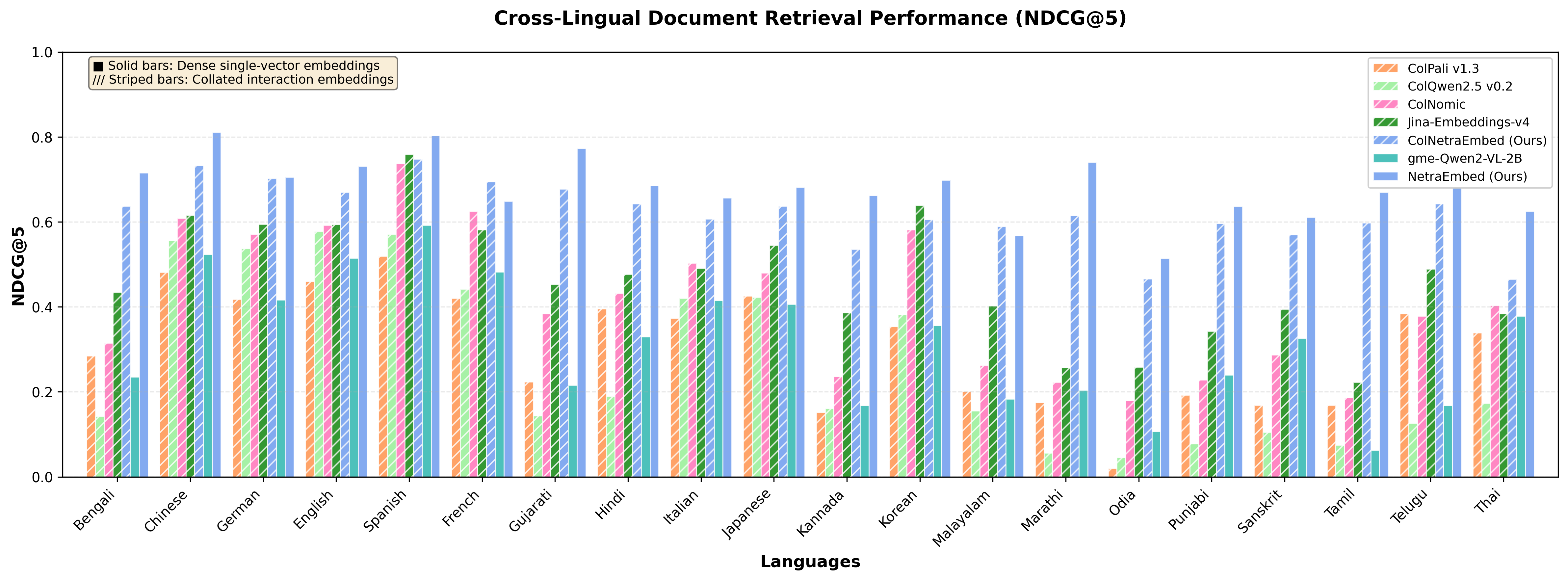
- Their best model, NetraEmbed, did much better than previous systems on cross-language document search.
- On a key score (NDCG@5), it reached about 0.716, compared to a strong baseline at 0.284. That’s roughly a 150% relative improvement.
- It also performed strongly in same-language search, and stayed competitive on English-only tests—so helping many languages didn’t make it worse at English.
- The single-vector model (NetraEmbed) was both:
- more accurate for cross-language tasks,
- and much more efficient (about 10 KB per document vs. megabytes for multi-vector).
- The Matryoshka idea worked well:
- Cutting the fingerprint size to about one-third (768 dimensions) kept about 95% of the full accuracy while saving ~70% storage. That’s perfect for huge libraries or devices with limited memory.
Why this matters:
- Most earlier systems focused on English and struggled with other scripts and fonts.
- This research shows we can build a reliable, multilingual, image-aware search tool that scales to millions or billions of pages—without throwing away visual information like charts or layout.
What’s the potential impact?
If widely used, this work could:
- Make information easier to find for people who don’t read English.
- Help schools, libraries, companies, and museums search mixed-language collections that include scans, forms, tables, and diagrams.
- Improve AI systems that answer questions using documents (RAG systems), especially when those documents are visual or multilingual.
The authors also note limits and future work:
- Some rare language pairs are still harder.
- Complex tables and different number formats remain tricky.
- They plan to move from page-level search to finding exact parts inside pages.
- Expanding to even more low-resource languages is a next step.
In short, this paper shows how to build a fairer and smarter document search engine that understands both words and visuals across many languages—and does it efficiently.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or unexplored in the paper, framed to be directly actionable for future research.
- Reliance on synthetic multilingual data: absence of evaluation on large-scale, real-world non-synthetic multilingual document sets (scanned PDFs, camera-captured pages, handwriting, noisy/low-quality images) to validate generalization beyond rendered Noto fonts.
- Query synthesis validity: no human evaluation or cross-lingual quality audit of VLM-generated queries (fluency, cultural adequacy, ambiguity), leaving potential biases, unnatural phrasing, and distribution mismatches unquantified.
- Code-switching and mixed-script scenarios: no explicit evaluation for documents and queries containing multiple languages/scripts on the same page or within a single query (e.g., English+Hindi, Arabic numerals within Devanagari text).
- Passage-/region-level retrieval: retrieval is document (page)-level; methods and metrics for fine-grained region-level retrieval (e.g., bounding-box targeting in tables or figure captions) are not developed or evaluated.
- Multi-page document retrieval: indexing and retrieval strategies for multi-page documents and cross-page reasoning are not addressed; open questions include page segmentation, aggregation, and multi-page scoring.
- Tables and numerals: robustness to language-specific number formats (Arabic-Indic digits, Hindi numerals) and complex tabular layouts is identified as challenging but not systematically studied with table-aware objectives or datasets.
- Equations and scientific notation: performance on math-heavy pages (equations, symbols) and domain-specific notation (chemistry, physics) remains untested, especially across scripts where formula rendering differs.
- Charts/figures and layout-heavy content: the contribution of visual elements (charts, diagrams) to retrieval accuracy and cross-lingual alignment is not isolated; need content-type-specific error analysis.
- Typographic variability: impact of real-world fonts, ligatures, kerning, RTL/LTR directionality, and script-specific line-breaking rules beyond Noto coverage is not quantified; typography ablation studies are missing.
- Document image degradations: robustness to skew, blur, compression artifacts, marginal crop, background noise, watermarks, and camera perspective distortions is not measured; need stress tests simulating field conditions.
- Strong OCR-based baselines: lack of head-to-head comparison against state-of-the-art multilingual OCR pipelines plus text retrievers (e.g., language-aware OCR + LaBSE/GTE/BGE-M3), including recall/latency trade-offs and error cascades analysis.
- Cross-modality queries: retrieval is text-to-document image; image-to-image, image-to-text (e.g., “find the page similar to this figure”), or speech-to-document queries are not explored.
- Romanization and transliteration: performance on romanized queries (e.g., “Hindi written in Latin script”) retrieving native-script documents is unknown; no evaluation on transliteration variants or dialectal spelling.
- Adversarial/noisy queries: robustness to misspellings, mixed scripts, colloquialisms, dialects, and adversarial prompts is not studied; need language-specific noise models and adversarial benchmarks.
- Scalability and efficiency beyond storage: end-to-end indexing time, HNSW parameterization, retrieval latency under varying corpus sizes (millions to billions), and energy/cost profiles are not reported.
- Compression/quantization: Matryoshka addresses dimensional truncation, but effects of product quantization, vector compression, and low-bit quantization on multilingual accuracy and latency are unexplored.
- Model scaling laws: no systematic study of backbone size and multilingual pretraining (256M → 4B) on retrieval performance; missing controlled ablations across architectures (Gemma/Qwen/SmolVLM) and training data scales.
- Pooling strategies: last-token pooling is favored, but alternative aggregations (mean/max/attention pooling, learned pooling) are not benchmarked across languages and content types.
- Loss/temperature sensitivity: InfoNCE temperature () and margin choices are fixed; sensitivity analyses across languages and query types are absent; potential for curriculum learning or language-aware temperature tuning.
- Hard negative mining: finding that in-batch negatives beat hard-mined negatives may be an artifact of synthetic data; need validation on real datasets and exploration of multilingual hard-negative mining with dynamic/adaptive strategies.
- Interpretability/explainability: no visualization or analysis of cross-lingual patch/token alignment (e.g., MaxSim maps), nor attribution of which regions drive retrieval; hinders debugging and fairness audits.
- Fairness across languages: performance equity metrics, calibration across high- vs. low-resource languages, and longitudinal monitoring strategies are not reported; need disparity analysis and mitigation to avoid marginalization.
- Benchmark size/diversity: Nayana-IR per-language test sets (~200 queries) may be statistically underpowered; require larger, more diverse, and real-world benchmarks, including domain-specific subsets (legal, medical, government).
- Domain transfer: generalization to novel domains (receipts, forms, invoices, handwritten notes, archival manuscripts) is untested; need domain-conditioned evaluations and adaptation strategies.
- Reranking and hybrid retrieval: integration of dense retrieval with multilingual rerankers (e.g., cross-attention VLMs, table-aware rerankers) is not explored; potential gains on hard queries left unquantified.
- Multi-vector efficiency: storage/latency claims for ColBERT-style embeddings lack detailed breakdown across token counts/resolutions; need empirical scaling curves and memory accounting under different visual tokenization schemes.
- Zero-shot to unseen languages/scripts: proposed as future work but not evaluated; need protocols to test transfer to truly unseen scripts (e.g., Georgian, Armenian) and extremely low-resource languages.
- Mixed-directionality pages: behavior on documents mixing RTL and LTR text (e.g., Arabic with English technical terms) is unknown; need targeted benchmarks and preprocessing/alignment strategies.
- End-to-end RAG evaluation: retrieval is evaluated standalone; downstream impact on multilingual document-centric RAG (answer accuracy, faithfulness, latency) across languages is not measured.
- Privacy and compliance: practical deployment considerations (PII handling, language-specific legal constraints, storage policies) are not addressed; research needed on privacy-preserving multilingual retrieval.
Practical Applications
Immediate Applications
The following applications can be deployed now using the released models (NetraEmbed and ColNetraEmbed), the Nayana-IR benchmark, and the described workflows (offline indexing, vector search, Matryoshka embeddings). Each bullet specifies sectors, suggested tools/products, workflows, and key assumptions/dependencies.
- Multilingual, OCR-free enterprise document search (finance, consulting, manufacturing, energy)
- Tools/products: NetraEmbed 768/1536/2560-d embeddings; FAISS/HNSW or Milvus/Pinecone indices; PDF-to-image conversion via Docling/Marker; simple UI for cross-lingual queries
- Workflow: Offline page-level indexing of scanned PDFs and reports; online cosine-similarity search supports queries in any of 22 languages
- Assumptions/dependencies: Access to document images (sufficient resolution), vector DB infrastructure, GPU/accelerator for initial encoding; policies for handling confidential data
- Cross-border compliance and audit retrieval (finance, pharma, telecom)
- Tools/products: “Compliance Finder” built atop NetraEmbed; dashboards for query logs and audit trails
- Workflow: Index regulatory filings, certifications, standards, and legal notices (scanned, mixed-language); cross-lingual search to quickly locate relevant clauses or forms
- Assumptions/dependencies: Proper data governance and retention; consistent page rendering; domain fine-tuning (optional LoRA, ~12 hours on 4×A100)
- Multilingual legal e-discovery for scanned filings and exhibits (legal services)
- Tools/products: Integration with e-discovery platforms; ColNetraEmbed where fine-grained token-level matching is needed
- Workflow: Ingest multi-language case materials; run cross-lingual queries against scans to find responsive documents
- Assumptions/dependencies: Chain-of-custody and provenance logging; sufficient compute for large corpora; fairness monitoring across languages
- Government citizen services: retrieval of forms, notices, and circulars in local languages (public sector)
- Tools/products: “Citizen Search” portal; NetraEmbed with Matryoshka for cost-effective storage; HNSW indexing for speed
- Workflow: Index scanned forms and notices; enable citizens and staff to query in their preferred language (including Devanagari, Dravidian, CJK, Arabic scripts)
- Assumptions/dependencies: Accessibility and privacy compliance; high-quality scanning; multilingual UX design
- Digital libraries and academic publishers: cross-lingual search of scanned journals and proceedings (academia, publishing)
- Tools/products: Library search plugins; BEIR-compatible evaluation with Nayana-IR; batch indexers for large collections
- Workflow: Page-level indexing of legacy archives; provide mixed-language discovery for research queries
- Assumptions/dependencies: Digitized content availability; licensing/rights management; storage planning (Matryoshka reduces storage by 40–70%)
- Cultural heritage archives: search across diverse scripts for manuscripts and historical documents (museums, archives)
- Tools/products: “Heritage IR” service for archivists; on-prem vectors (privacy-preserving)
- Workflow: Index scans with authentic script coverage; researchers query in their language to find cross-script items
- Assumptions/dependencies: Coverage matches included 22 languages; accurate digitization; metadata integration for provenance
- Campus/LMS material discovery: slides, handouts, and exams across languages (education)
- Tools/products: LMS plugins; course-level indexers; lightweight NetraEmbed deployment
- Workflow: Index course visuals and pages; students and faculty query in multiple languages without OCR errors
- Assumptions/dependencies: FERPA/GDPR compliance; consistent PDF-to-image rendering; edge caches for latency
- Healthcare administration document search: discharge summaries, forms, insurance claims (healthcare)
- Tools/products: “HealthDoc IR” internal search; on-prem deployment with strict access control
- Workflow: Index scanned administrative records; clinicians/admin staff query in local languages to find forms and instructions
- Assumptions/dependencies: PHI protection; strong access and audit controls; adequate image quality; optional domain fine-tuning
- Customer support and CX knowledge bases: retrieval over attachments, screenshots, and mixed-language manuals (software, telecom, consumer electronics)
- Tools/products: “Support IR” module; VisRAG-style RAG with visual retrieval + answer generation
- Workflow: Index tickets and product documents as images; support agents query cross-lingually to find solutions faster
- Assumptions/dependencies: Integration with existing helpdesk systems; latency budgets; optional reranking
- Multimodal RAG for document QA (SaaS, internal KM)
- Tools/products: Combine NetraEmbed retrieval with a VLM/LLM for answer generation; use Visa/VisRAG-style source attribution
- Workflow: Retrieve relevant pages (images) and ground them for answer generation; provide visual source references
- Assumptions/dependencies: RAG orchestration; model choice for generation; guardrails for hallucination
- Localization QA and translation consistency checks (localization industry)
- Tools/products: “Localization IR” to compare translated page images against originals; scripting around Nayana-style data synthesis
- Workflow: Index parallel documents; use cross-lingual retrieval to identify mismatches or missing content
- Assumptions/dependencies: Availability of parallel corpora or synthetic parallels; font/script fidelity
- Benchmarking and model selection workflows (industry/academia)
- Tools/products: Adopt Nayana-IR as a standard BEIR-compatible benchmark; CI pipelines to track NDCG/MRR across languages
- Workflow: Continuous evaluation of retrievers for multilingual document search readiness
- Assumptions/dependencies: Separation of train/test; representative language mix for target deployments
Long-Term Applications
The following applications are feasible with further research, scaling, or system development (e.g., region-level grounding, table-aware objectives, expansion to truly low-resource languages, privacy technologies).
- Region-level and passage-level retrieval with visual grounding (all sectors)
- Tools/products: Bounding-box aware retrievers; hybrid rerankers; UI for highlighting matched regions
- Workflow: Move from page-level to region-level hits; show exactly where the answer lies (figures, tables, clauses)
- Assumptions/dependencies: New training objectives; annotated data for visual grounding; efficient runtime region scoring
- Table-aware retrieval tolerant to locale-specific numerals and formats (finance, healthcare, logistics)
- Tools/products: “Table IR” extension; numeric-normalization modules
- Workflow: Robust retrieval of tabular evidence across scripts (e.g., Hindi numerals, Arabic-Indic digits)
- Assumptions/dependencies: Table-centric training data; format-aware pre/post-processing; evaluation suites
- Expansion to more (truly low-resource) languages and unseen scripts via synthetic data and zero-shot transfer (public sector, academia)
- Tools/products: Extended Nayana-style synthesis; language adapters
- Workflow: Scale model/benchmark beyond 22 languages; maintain state-of-the-art cross-lingual performance
- Assumptions/dependencies: Font coverage, layout rules, high-quality translation models; compute for training
- Mobile, on-device multimodal retrieval for personal document vaults (daily life)
- Tools/products: Edge inference with 768-d Matryoshka truncation; compact encoders (SmolVLM-class)
- Workflow: Index bills, forms, manuals on-device; voice/text queries in local languages retrieve exact page/images
- Assumptions/dependencies: Efficient on-device VLM encoding; battery and storage constraints; private indexing
- Voice-to-document cross-lingual retrieval (public services, call centers)
- Tools/products: ASR + NetraEmbed pipeline; multi-language speech interfaces
- Workflow: Users speak queries; system retrieves relevant pages in any language
- Assumptions/dependencies: Accurate ASR per language; latency constraints; speech privacy
- Cross-modal query types: retrieve diagrams/figures by image or sketch (engineering, education)
- Tools/products: Image-to-image/document retrievers; figure-centric embeddings
- Workflow: Query with a diagram/photo to find matching design pages or manuals
- Assumptions/dependencies: Data for image-to-document alignment; fine-grained visual token matching
- Privacy-preserving and federated retrieval (policy, regulated industries)
- Tools/products: Differential privacy for embeddings; federated indexing; encrypted vector search
- Workflow: Keep document images on-prem; share only privacy-preserving embeddings across federations
- Assumptions/dependencies: Robust PP techniques; regulatory acceptance; performance overheads
- Fairness monitoring and language equity dashboards (policy, governance)
- Tools/products: Metrics for per-language NDCG/MRR, drift detection; governance frameworks
- Workflow: Continuous monitoring to avoid marginalization of lower-resource languages; alerting and remediation
- Assumptions/dependencies: Instrumentation pipelines; representative test sets; organizational processes
- E-discovery with compliant audit logs and explainability (legal)
- Tools/products: Retrieval provenance; explainable matching (token-level reason codes)
- Workflow: Provide defensible search results with traceable logic
- Assumptions/dependencies: Standardization of explanations; court acceptance; integration with legal tooling
- Multi-document, multi-page RAG with reasoning over visual layouts (research, enterprise KM)
- Tools/products: Long-context VLMs; layout-aware chain-of-thought; hierarchical retrieval + summarization
- Workflow: Answer complex queries requiring synthesizing content across pages/documents
- Assumptions/dependencies: Efficient long-context handling; layout-aware training; cost control
- Industry-specific fine-tuned variants (e.g., healthcare PHI, financial filings) (healthcare, finance)
- Tools/products: Domain LoRA adapters; curated synthetic data
- Workflow: Tailor retrieval to jargon, forms, and layouts of each sector
- Assumptions/dependencies: Domain data availability; safe training on sensitive content; periodic re-evaluation
- Multimodal search-as-a-service for multilingual documents (software/SaaS)
- Tools/products: Managed vector indices; indexing pipelines; SLAs for multilingual performance
- Workflow: Offer hosted APIs for cross-lingual, OCR-free document retrieval at scale
- Assumptions/dependencies: Cloud cost optimization; throughput scaling; security certifications (SOC2/ISO27001)
- Knowledge graph enrichment from retrieved visual documents (enterprise data platforms)
- Tools/products: IE pipelines that attach entities/relations to retrieval results; graph databases
- Workflow: Convert retrieved pages into structured facts to power analytics
- Assumptions/dependencies: Reliable IE over images; human-in-the-loop validation; error mitigation
These applications build directly on the paper’s contributions: robust multilingual multimodal retrieval across 22 languages, OCR-free alignment of text and document images, practical efficiency via Matryoshka embeddings, a standardized benchmark (Nayana-IR), and deployable 4B-parameter models that generalize across dense and ColBERT-style paradigms.
Glossary
- Approximate nearest neighbor search: Indexing technique that quickly finds vectors close to a query in high-dimensional spaces, trading exactness for speed. "enabling efficient retrieval via approximate nearest neighbor search~\cite{faiss2017, hnsw2016}."
- BEIR: A standardized benchmark and data format for evaluating information retrieval systems. "BEIR compatible structure \cite{beir2021} enables standardized evaluation."
- BM25: A classical term-weighting retrieval function used to score document relevance from text. "Text similarity using BM25~\cite{bm25}"
- ColBERT-style late interaction: A retrieval paradigm that keeps per-token embeddings and compares them at query time to capture fine-grained matches. "M3DR generalizes across both single dense vector and ColBERT-style token-level multi-vector retrieval paradigms."
- Contrastive learning: A training approach that pulls matching pairs closer and pushes non-matching pairs apart in embedding space. "Modern dense retrievers rely on contrastive learning with InfoNCE loss~\cite{infonce2018} and hard negative mining."
- Cross-lingual retrieval: Retrieving documents written in languages different from the query language. "152\% relative improvement over baselines on cross-lingual retrieval (0.716 vs 0.284 NDCG@5)"
- Dense retriever: A retrieval model that maps queries and documents to continuous vectors for similarity search. "Modern dense retrievers rely on contrastive learning with InfoNCE loss~\cite{infonce2018} and hard negative mining."
- Hard negative mining: Selecting challenging non-relevant examples to improve discriminative training. "Positive-only (in-batch negatives) training strategy substantially outperforms document-level negative and hard negative mining (combined text+visual) strategies"
- HNSW: Hierarchical Navigable Small World; a graph-based ANN index for fast vector search. "Single-vector cosine similarity via HNSW vs. expensive MaxSim computation"
- In-batch negatives: Using other samples in the same training batch as negative examples for contrastive loss. "Our baseline employs InfoNCE~\cite{infonce2018} with in-batch negatives."
- InfoNCE loss: A popular contrastive loss that maximizes similarity to positives while normalizing over negatives. "we employ InfoNCE loss with in-batch negatives following ColPali~\cite{colpali2024}."
- L2-normalization: Scaling vectors to unit length so cosine similarity equals dot product. "Embeddings are L2-normalized and similarity computed via:"
- Last-token pooling: Aggregation strategy that uses the final token’s hidden state as the sequence embedding. "We apply last token pooling to obtain document-level embeddings."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning technique that injects low-rank adapters. "With LoRA fine-tuning on 4A100 GPUs requiring only 12 hours for SOTA results"
- MAP@10: Mean Average Precision at cutoff 10; measures average precision across queries up to rank 10. "Metrics: NDCG@5 and NDCG@10, Recall@5 and Recall@10, MAP@10, and MRR@10."
- Matryoshka representation learning: Training embeddings to be truncatable to smaller dimensions while preserving performance. "Matryoshka representation learning enables flexible post-deployment dimension selection without retraining"
- MaxSim: The operation in late interaction models that, for each query token, takes the maximum cosine similarity over document tokens. "Similarity is computed via late interaction using MaxSim:"
- MRR@10: Mean Reciprocal Rank at 10; averages the reciprocal rank of the first relevant result up to rank 10. "Metrics: NDCG@5 and NDCG@10, Recall@5 and Recall@10, MAP@10, and MRR@10."
- Multimodal: Involving multiple data modalities (e.g., text and images) jointly. "multilingual multimodal document retrieval"
- NDCG@5: Normalized Discounted Cumulative Gain at 5; evaluates ranking quality with graded relevance, emphasizing top results. "Metrics: NDCG@5 and NDCG@10, Recall@5 and Recall@10, MAP@10, and MRR@10."
- OCR: Optical Character Recognition; converting images of text into machine-encoded text. "OCR-based pipelines"
- Recall@10: The fraction of relevant documents retrieved in the top 10 results. "Metrics: NDCG@5 and NDCG@10, Recall@5 and Recall@10, MAP@10, and MRR@10."
- Reciprocal rank fusion: A method to combine ranked lists by summing inverse rank scores. "Fusion via reciprocal rank fusion where ."
- Single dense vector: A retrieval representation where each item is encoded into one fixed-length embedding for ANN search. "NetraEmbed ... a single dense vector model using Matryoshka representation learning"
- Temperature parameter: A scaling factor in softmax-based losses that controls distribution sharpness. "where is the temperature parameter."
- Token-level representations: Per-token embeddings produced by a model before pooling or interaction. "token-level representations and ."
- Typologically diverse languages: Languages that differ structurally (scripts, morphology, syntax), used to stress cross-linguistic generalization. "22 typologically diverse languages"
- VLM (Vision-LLM): A model jointly trained on visual and textual data to align the two modalities. "vision LLMs (VLMs)"
Collections
Sign up for free to add this paper to one or more collections.

