- The paper introduces HIVE, which uses LLM-based hypothesis generation to synthesize compensatory queries that improve reasoning on multimodal inputs.
- It employs an iterative process—initial retrieval, compensatory query synthesis, secondary retrieval, and LLM reranking—to refine document relevance.
- Experimental results on MM-BRIGHT show HIVE outperforming state-of-the-art models by up to 14.1 nDCG@10 points across 28 of 29 domains.
Motivation and Problem Statement
The increasing prevalence of multimodal queries—which combine textual and visual elements such as diagrams, charts, or screenshots—poses a critical challenge for retrieval systems. While dense neural retrievers and multimodal embedding models have demonstrated strong performance on conventional semantic retrieval tasks, they fundamentally underperform on reasoning-intensive multimodal queries. In particular, state-of-the-art multimodal models consistently yield lower effectiveness compared to text-only retrievers when evaluated on the MM-BRIGHT benchmark, underlining a persistent and significant visual reasoning gap in current approaches. This gap arises because existing multimodal retrieval systems lack explicit mechanisms for reasoning about the implications of visual content on document relevance.
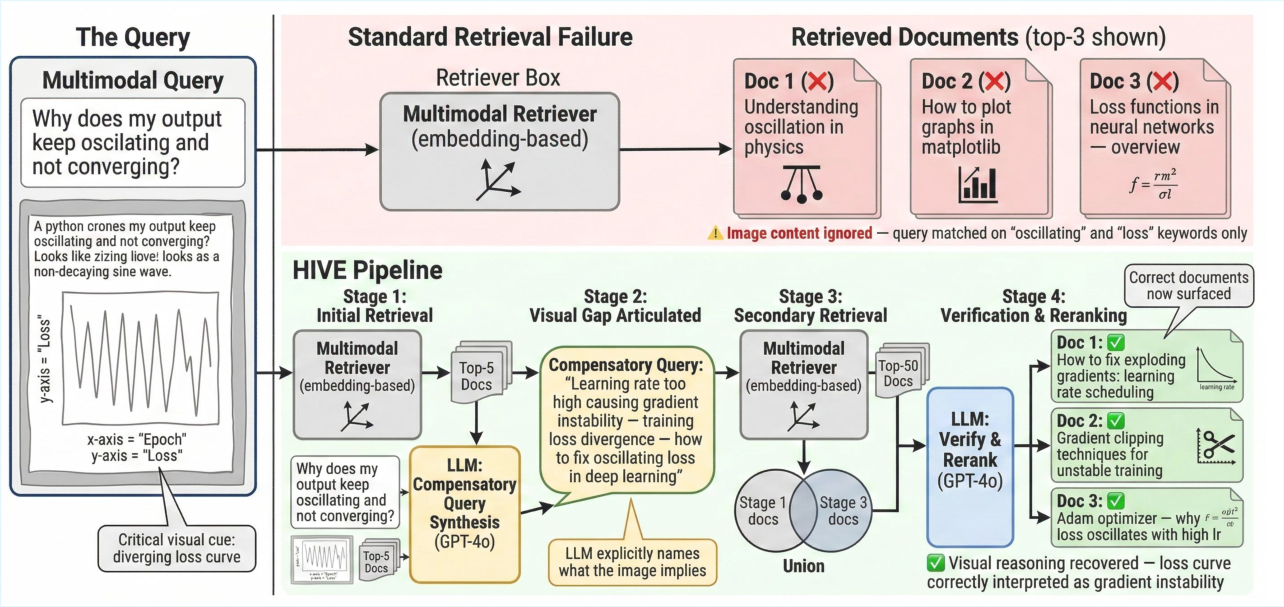
Figure 1: An example where standard multimodal retrievers fail to identify the relevant document because the query image (a circuit diagram) contains critical visual cues that text-only or embedding-based matching cannot capture. HIVE generates a compensatory query that explicitly articulates these visual gaps, enabling successful retrieval.
HIVE Framework Design
The HIVE (Hypothesis-driven Iterative Visual Evidence Retrieval) framework introduces a novel, model-agnostic solution: LLM-mediated visual hypothesis generation and verification is injected at inference time, requiring no retraining or modification of base retrievers. HIVE’s architecture is composed of four sequential stages:
- Initial Retrieval: A standard dense retriever retrieves a probe set of top-k1 candidates using the original multimodal query.
- Compensatory Query Synthesis: An LLM (e.g., GPT-4o), provided with the probe set and a machine-generated image caption, identifies missing visual or logical cues and synthesizes a targeted compensatory query.
- Secondary Retrieval: This compensatory query is used for a broader retrieval over the corpus, yielding a second set of candidate documents.
- Verification and Reranking: The LLM verifies and reranks the combined candidate pool in light of the original multimodal query.
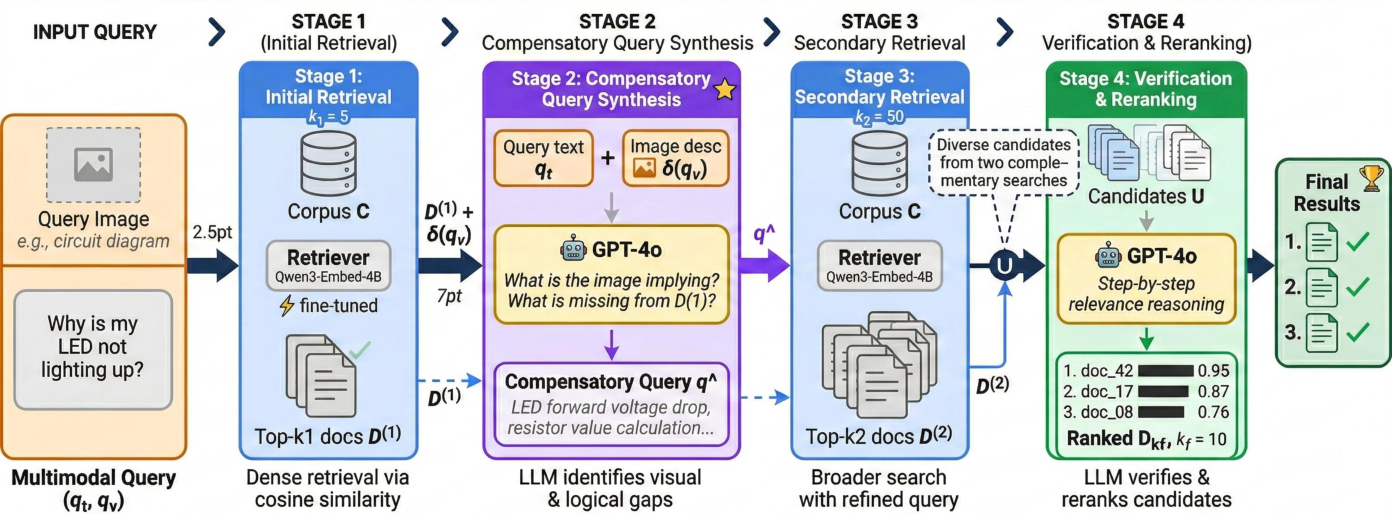
Figure 2: Overview of the HIVE framework. Given a multimodal query (qt,qv), HIVE operates in four stages: initial retrieval, compensatory query synthesis, secondary retrieval, and verification/reranking.
This iterative refinement mechanism systematically exposes and bridges the reasoning deficiencies of the initial retrieval pass, leveraging the LLM’s ability to interpret visual information and contextualize the relevance of both text and image data.
Experimental Results on MM-BRIGHT
The HIVE framework is evaluated using the MM-BRIGHT benchmark, which consists of 2,803 queries across 29 technical domains, including STEM fields, software, law, and applied sciences. Each query pairs textual intent with an associated image (diagram, chart, or screenshot), and the task is to retrieve the most relevant documents from a text-only corpus.
HIVE achieves an aggregated nDCG@10 of 41.7, which is +9.5 points higher than the strongest text-only retriever (DiVeR: 32.2) and +14.1 points higher than the leading multimodal embedding model (Nomic-Vision: 27.6).
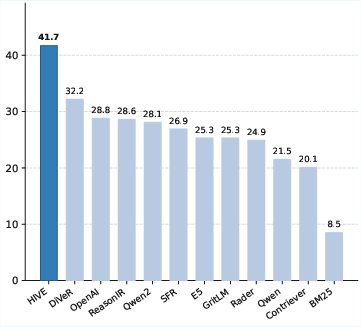
Figure 3: Average nDCG@10 on MM-BRIGHT (multimodal-to-text track) for all evaluated models. HIVE achieves 41.7, outperforming the best multimodal baseline (Nomic-Vision: 27.6) by +14.1 points.
HIVE achieves the top performance in 28 out of 29 domains, showing superior generalization. The gains are particularly marked in visually intensive domains, such as Gaming, Law, Economics, and Sustainability, demonstrating that compensatory query synthesis is highly effective when the visual modality encapsulates substantial domain-specific semantics.
Ablation, Plug-and-Play Flexibility, and Hyperparameter Sensitivity
Comprehensive ablation validates the independent and synergistic contributions of the compensatory query generation and LLM-based reranking stages. Applying these stages in isolation yields significant gains, yet the full pipeline yields the highest effectiveness, confirming their complementarity.
Crucially, HIVE maintains its efficacy across a variety of base retrievers, demonstrating consistent improvements on both vision-LLMs and reasoning-enhanced text retrievers. The framework’s plug-and-play character underscored by its substantial improvements even when wrapped around weaker base retrievers (e.g., CLIP: +10.1 nDCG@10).
Hyperparameter sensitivity analysis confirms that modest probe and retrieval candidate set sizes suffice for significant gains, striking a practical balance between retrieval coverage and LLM inference costs.
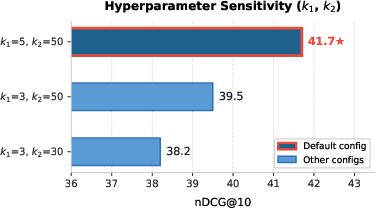
Figure 4: Hyperparameter sensitivity on MM-BRIGHT. Each bar shows nDCG@10 for a (k1,k2) configuration. The default setting (k1=5, k2=50) achieves the best performance of 41.7.
Theoretical and Practical Implications
HIVE highlights the limitations of embedding-only representations for multimodal reasoning tasks, reinforcing that direct integration of visual and textual cues through a shared vector space is insufficient for reasoning about complex, real-world multimodal problems. The results show that LLMs, when systematically invoked as “visual hypothesis” generators and verifiers, can substantially close this gap. Practically, HIVE’s inference-only, retriever-agnostic architecture lowers the operational barriers for practitioners to deploy reasoning-aware multimodal retrieval without retraining or access to labeled multimodal data.
Theoretically, the work demonstrates the feasibility and benefits of decomposing multimodal retrieval into iterative reasoning stages—each explicitly diagnosing and compensating for modality-specific retrieval failures. This opens the door for further research on finer-grained, interpretable diagnostic interventions and the integration of multi-hop vision-language reasoning over multimodal corpora.
Limitations and Future Directions
HIVE’s gains are attenuated in domains where visual input carries limited or highly abstract semantic value, such as Quantum Computing or Cryptography. These cases suggest new research directions in visual confidence estimation and adaptive query grounding. Future extensions include scaling HIVE for multi-image/video queries, reducing reliance on expensive proprietary LLMs by leveraging compact open-source variants, and optimizing compensatory query synthesis via reinforcement learning from retrieval feedback.
Conclusion
HIVE establishes a new paradigm for reasoning-intensive multimodal retrieval by operationalizing LLM-driven hypothesis generation and verification as inference-time modules, delivering state-of-the-art results in both aggregate and per-domain evaluation. This framework evidences that explicit, iterative LLM mediation can overcome fundamental modality mismatches that defeat embedding-based systems, representing a substantive step toward robust, general-purpose multimodal information retrieval.