- The paper introduces a layered scheduling framework that uses coarse output token priors to enable semi-clairvoyant admission, allocation, and ordering decisions.
- It employs adaptive Deficit Round Robin for inter-class allocation and urgency-weighted heuristics for intra-class ordering to optimize latency and throughput.
- Empirical evaluations demonstrate that using coarse priors nearly matches oracle performance, significantly improving SLO compliance and useful goodput under varied workloads.
Semi-Clairvoyant Scheduling for Black-Box LLM Inference: A Layered Decomposition
Problem Setting and Motivation
The paper "Scheduling the Unschedulable: Taming Black-Box LLM Inference at Scale" (2604.06970) addresses the problem of client-side scheduling for black-box LLM APIs, where internal server-side scheduling, batching, and queuing are opaque to the client. Traditional approaches offer limited leverage because request cost, largely determined by output token length, is not observable at submission time. However, building on recent advances in output-length prediction, the authors demonstrate that coarse, per-request output token priors can transform the client’s role into a semi-clairvoyant scheduler, enabling more principled admission, allocation, and ordering decisions prior to submission.
The scheduling challenge is restructured as a three-way decomposition:
- Allocation: Inter-class share management via adaptive Deficit Round Robin (DRR).
- Ordering: Intra-class selection through slowdown-aware, urgency-weighted heuristics.
- Overload Control: Explicit, bucketed admit/defer/reject at admission, targeting cost-aware service objectives.
Empirical evaluation and ablation demonstrate how these layers, empowered with coarse magnitude information, substantially improve latency SLOs, completion rate, and useful goodput under various workload regimes.
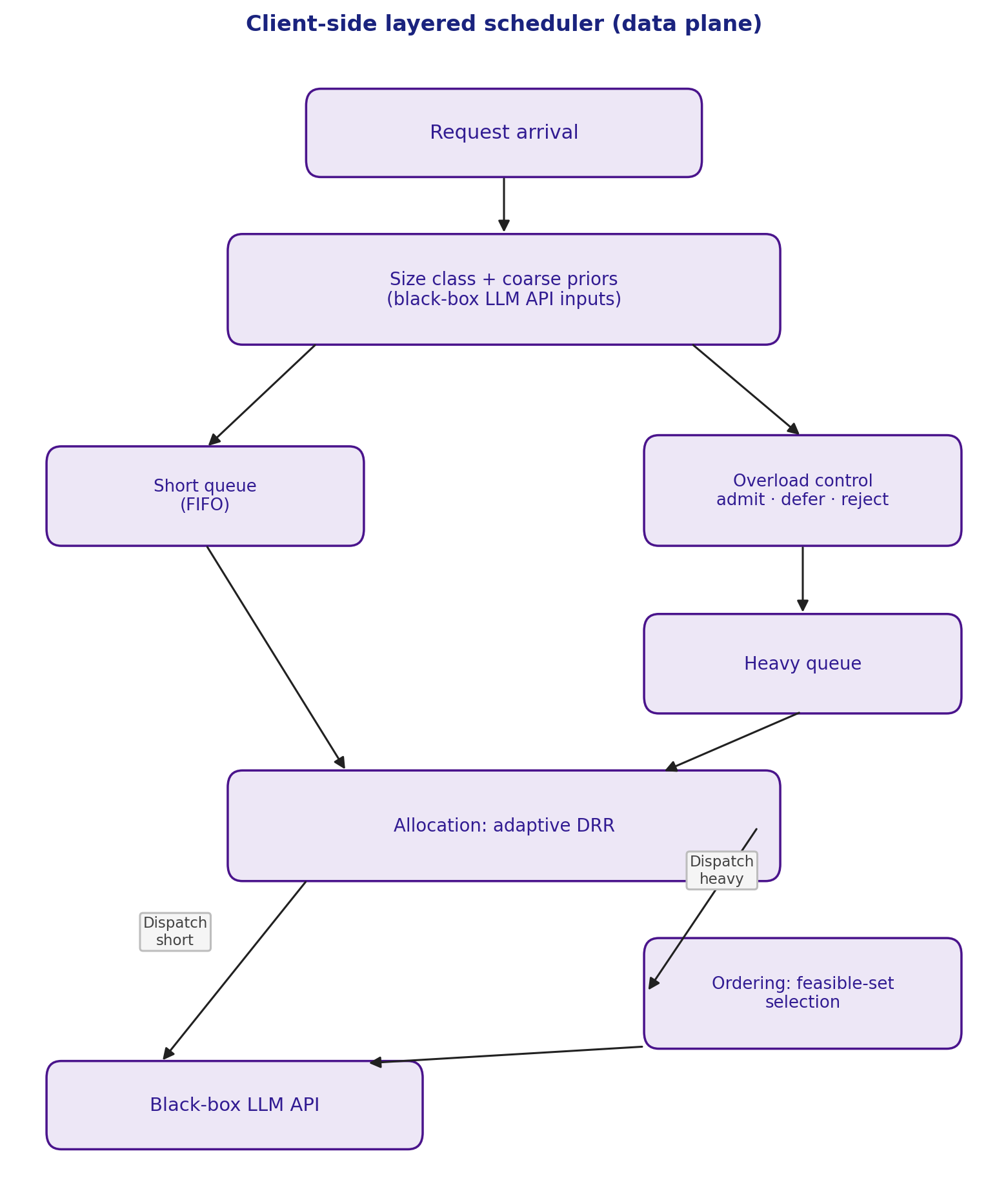
Figure 1: Data flow for the client scheduling stack, with allocation, ordering, and overload control layered before the black-box LLM API.
Three-Layer Scheduling Stack: Design and Rationale
The decomposition into allocation, ordering, and overload control is not only analytically clean but operationally meaningful, mapping distinct pathologies and interventions to separate layers:
- Allocation employs adaptive DRR with weight scaling based on observed congestion, ensuring interactive requests maintain protected share under stress. The client’s share decision adjusts dynamically as load fluctuates, optimizing both fairness and responsiveness.
- Ordering within classes, particularly the heavy class, uses a feasible-set score considering queue residence, predicted cost, and deadline urgency: w1⋅(wait/cost)−w2⋅(size/ref)+w3⋅urgency. This structure mitigates head-of-line blocking and preserves deadline-sensitive work.
- Overload Control is implemented as a severity-based admit/defer/reject decision at admission, with explicit mapping from estimated cost (medium/long/xlong) to action. The process replaces implicit timeouts and provider-side failures with interpretable, client-side shedding.
Decoupling these concerns allows for independent diagnosis and policy adaptation. Failures in completion, tail latency, or deadline satisfaction can be traced to their corresponding layer, as corroborated by the paper’s layerwise progression analysis.
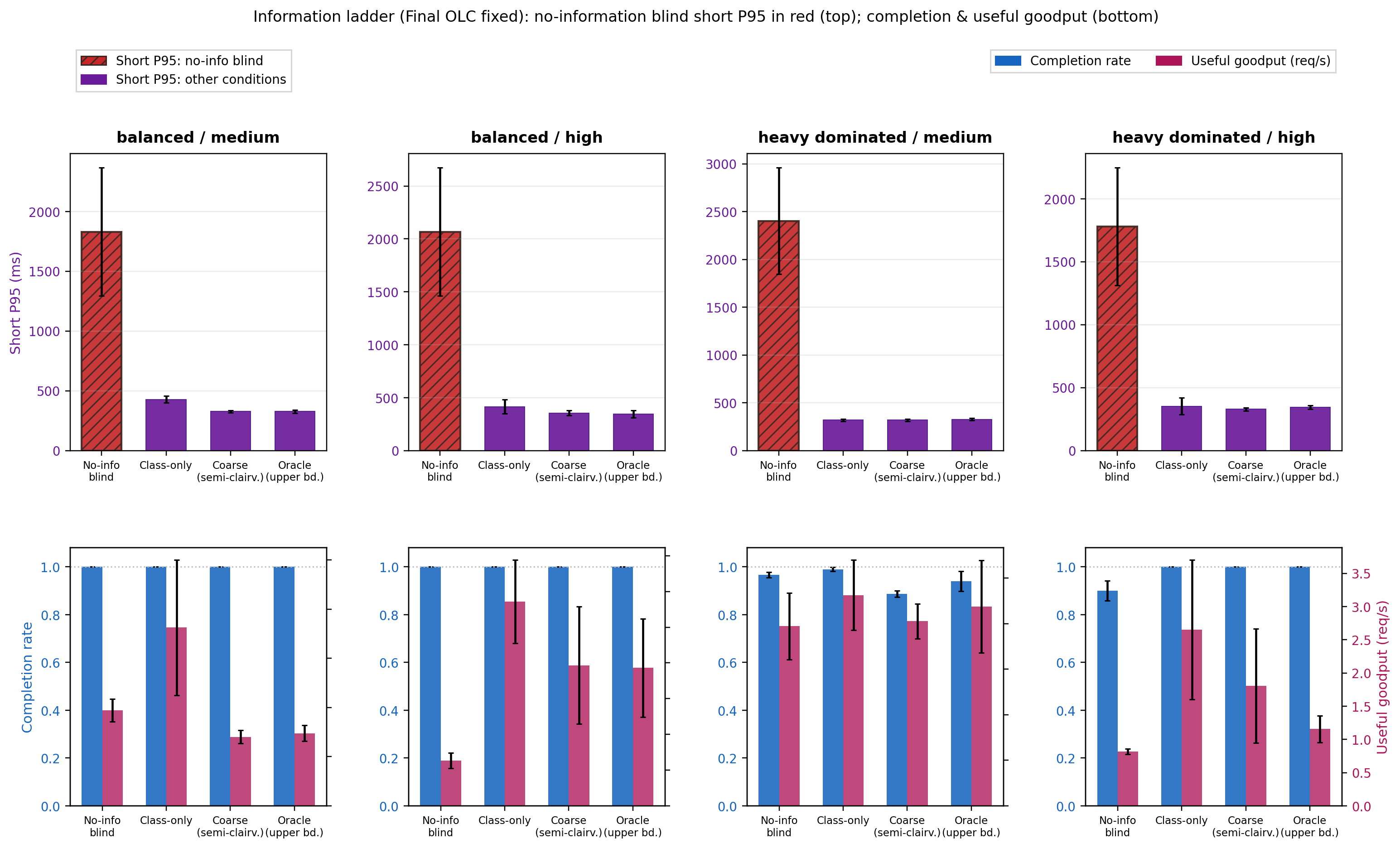
An information ladder experiment highlights the necessity of per-request magnitude priors versus class-only or no-information controls.
Policy Comparisons and Regime Sensitivity
The main policy evaluations, conducted on a calibrated congestion-aware mock provider, reveal:
- In balanced regimes, the full stack (allocation, ordering, overload control) achieves 100% completion, 100% deadline satisfaction, and short P95 within tens of milliseconds of simpler quota-tiered isolation, but with higher useful goodput and explicit overload actions.
- In heavy-dominated regimes, trade-offs become sharper: quota-tiered policies can minimize global tail at the cost of lower completion, while the full stack optimizes all joint metrics except for cases of heavy request starvation.
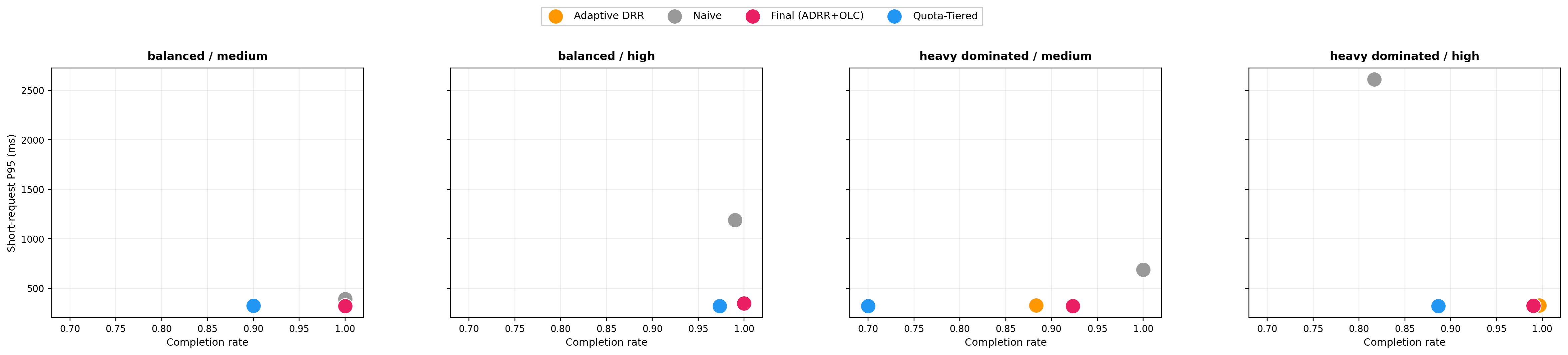
Figure 3: Short-request P95 vs. completion rate for core policy variants—structured semi-clairvoyant stacks outperform blind/naive dispatch especially under stress.
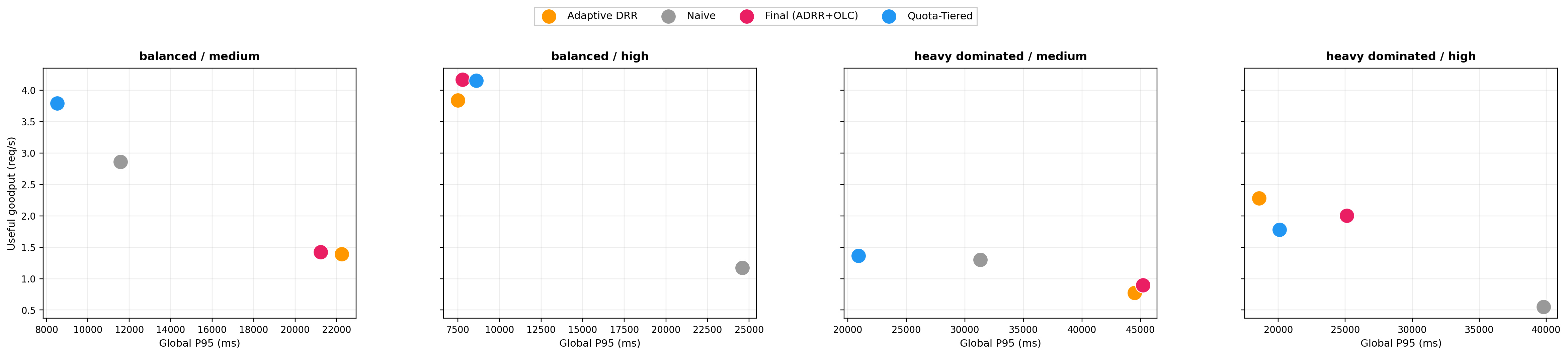
Figure 4: Useful goodput vs. global P95 demonstrates distinct regime-dependent trade-offs for structured policies.
Alternative Allocation and Overload Control
Allocation Layer: Comparing Short-Priority (biased toward interactive) with Fair Queuing (round-robin), Fair Queuing provides a better balance—improving short-request P90 by +32% with only +17% overhead for long requests, compared to Short-Priority’s +27% / +116%. This exposes a tunable fairness-performance spectrum without rearchitecting the stack.
Overload Control: The cost-ladder bucket policy ensures that rejections concentrate on the most expensive (xlong) requests, protecting interactivity and SLO-compliance for short and medium jobs.
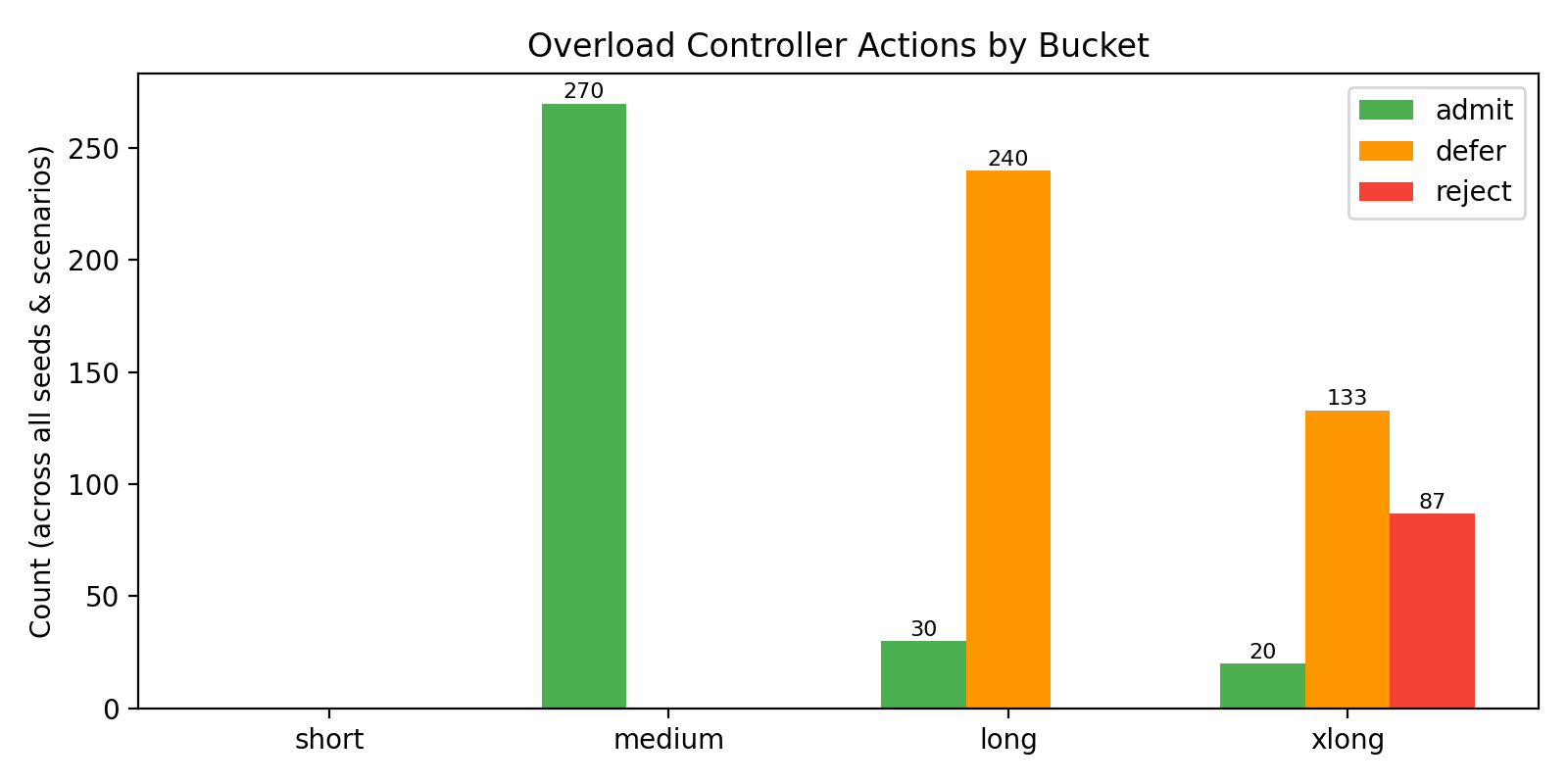
Figure 5: Overload actions under the default bucket policy—sacrifice is focused on xlong requests.
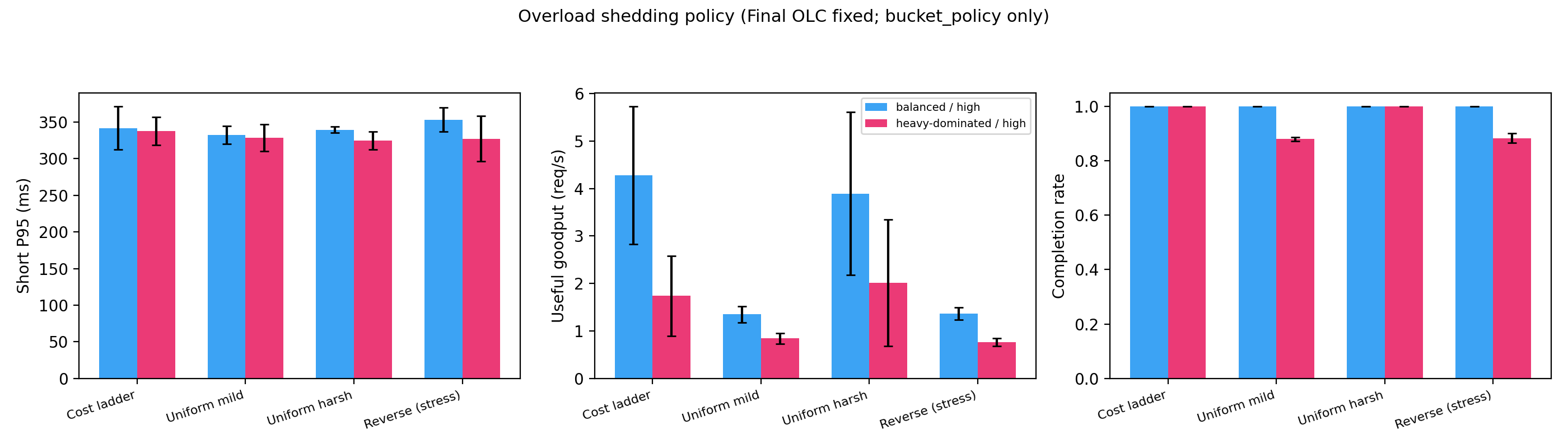
Figure 6: Comparison across overload policies—cost ladder maximizes useful goodput and SLO satisfaction with explicit, interpretable control.
Robustness: Ablations, Layerwise Progression, and Sensitivity
Layerwise ablation (Figure 7) demonstrates that each layer contributes orthogonally to joint metrics, with final policies avoiding naive trade-offs that starve completion or inflate tails for short requests.
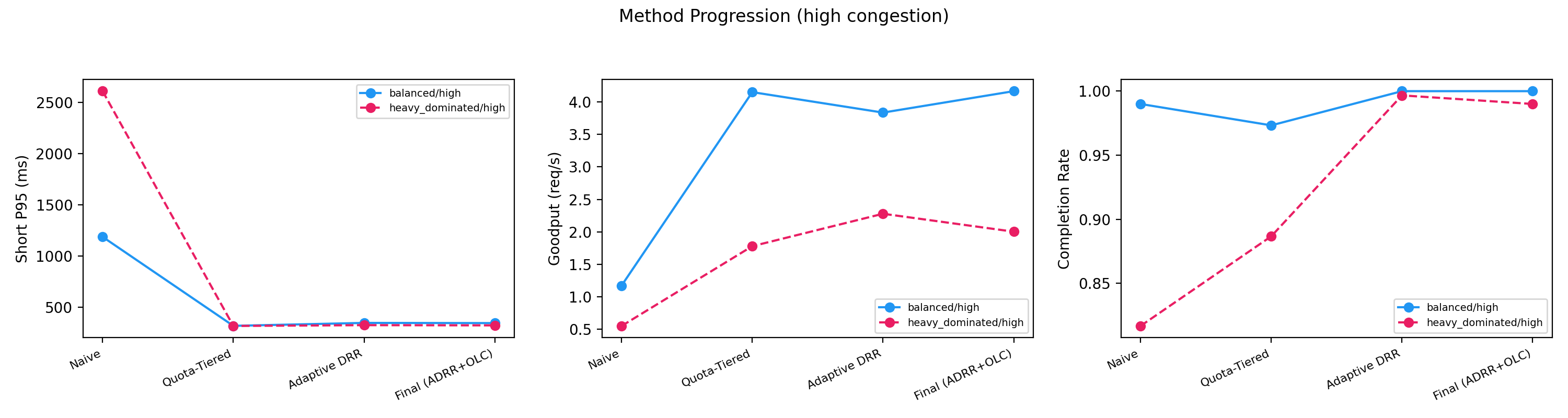
Figure 7: Progression from naive dispatch to quota, adaptive DRR, and full stack elucidates the layered impact on short P95, goodput, and completion.
Sensitivity sweeps confirm operational stability: overload threshold perturbation (±20%) leads to bounded, smooth changes in completion and goodput. Predictor quality sweeps (up to 60% multiplicative noise) result in graceful, regime-dependent degradation—underscoring that coarse, not oracle, priors are sufficient for robust scheduling.
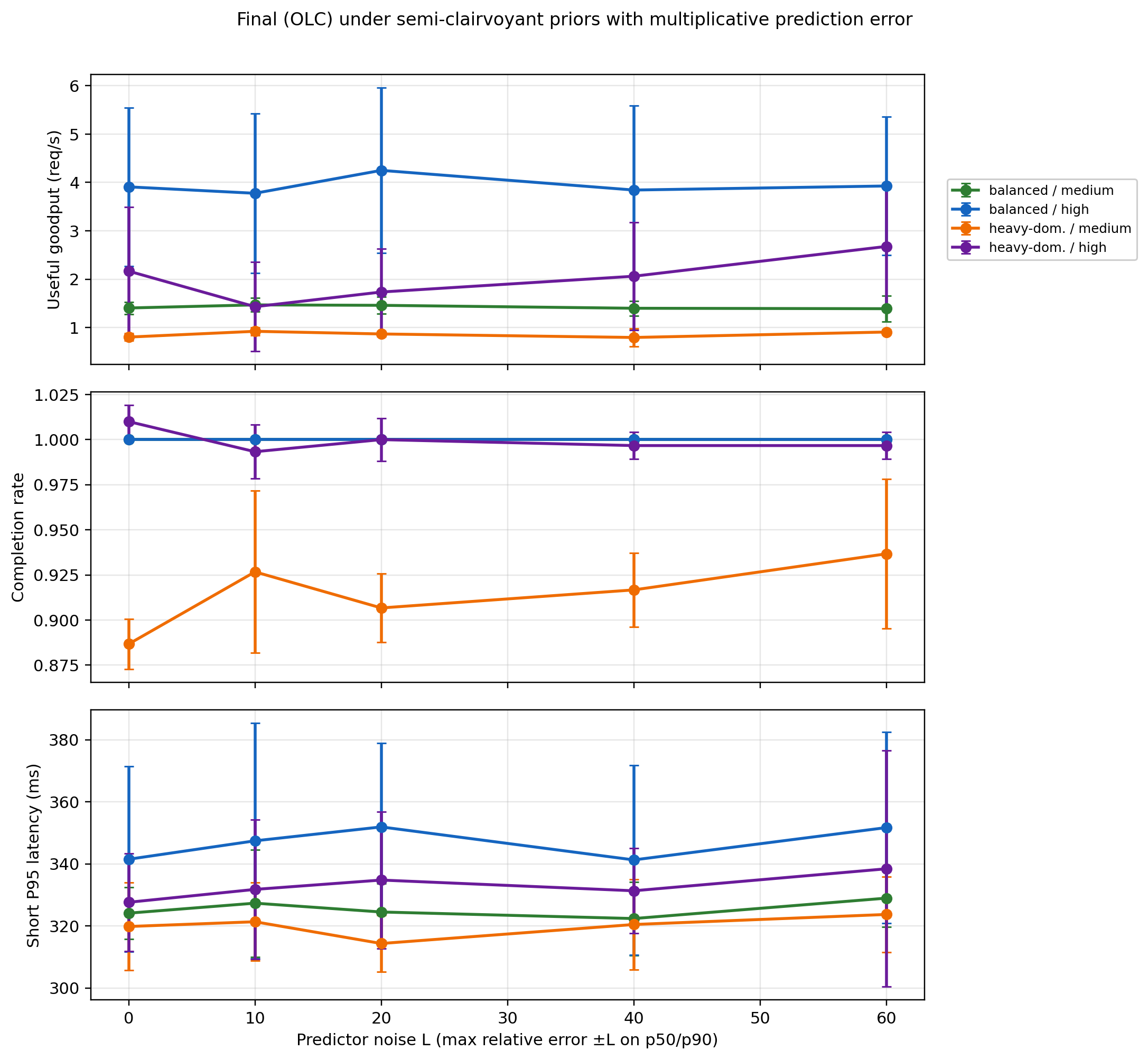
Figure 8: Predictor noise sweep—metrics drift smoothly with increasing error in length prediction, demonstrating resilience of the layered stack.
Practical and Theoretical Implications
This research formalizes the client-API boundary as a semi-clairvoyant scheduling problem and demonstrates that meaningful, actionable controls over SLOs and throughput can be achieved with only coarse, pre-dispatch length priors. The decomposition allows for modular tuning: allocation policies can be selected for fairness or prioritized class performance, overload rejection can be shaped transparently, and system-induced sacrifices are interpretable externally.
Practically, this advances the maturity of client etiquette for multi-tenant LLM APIs, bridging the gap between server-side scheduling (e.g., vLLM/PagedAttention, DistServe, Sarathi-Serve) and the levers available before the black-box boundary. Theoretically, the explicit mapping of regime-dependent Pareto frontiers for joint metrics grounds future work in deployable, data-driven evidence.
Limitations and Future Directions
The study relies on a mock provider with linear latency scaling, calibrated but not representative of proprietary vendor models. Thresholds are hand-tuned; full trace-driven evaluation and automated parameterization remain open. Heavy-dominated workloads are more sensitive to predictor error, exposing opportunities for adaptive or hybrid admission control.
Potential avenues for future exploration include:
- Integration with production predictor pipelines and real-time traces,
- Automated or learning-based adaptation for thresholds and heuristics,
- Closer coupling with in-engine scheduling by exposing additional feedback signals,
- Extension to non-token-dominated resource models.
Conclusion
By systematically structuring client-side scheduling into allocation, ordering, and overload control—and empirically validating their separability and robustness under semi-clairvoyant information—the paper provides both a practical toolset and a conceptual foundation for effective request shaping at the black-box LLM API boundary. This layered decomposition enables tunable, transparent policies that optimize latency, throughput, and fairness, extending the frontier for AI service operators in diverse production contexts.