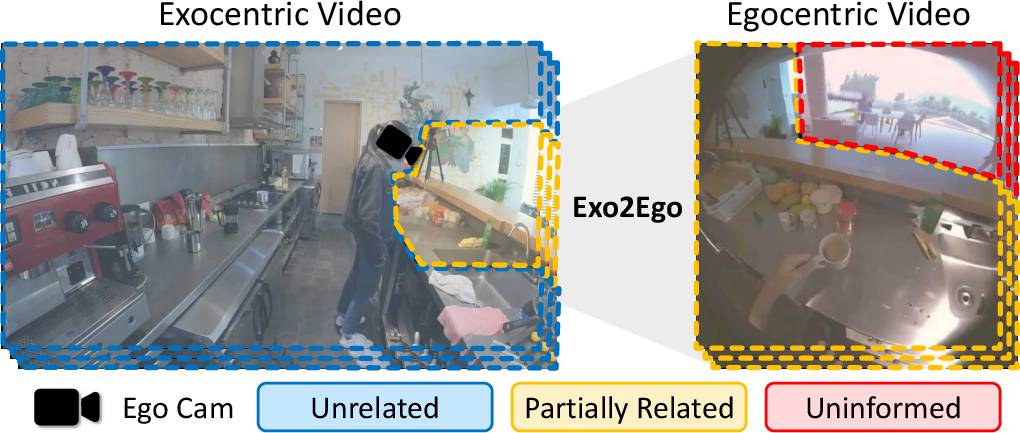
EgoX: Egocentric Video Generation from a Single Exocentric Video
Abstract: Egocentric perception enables humans to experience and understand the world directly from their own point of view. Translating exocentric (third-person) videos into egocentric (first-person) videos opens up new possibilities for immersive understanding but remains highly challenging due to extreme camera pose variations and minimal view overlap. This task requires faithfully preserving visible content while synthesizing unseen regions in a geometrically consistent manner. To achieve this, we present EgoX, a novel framework for generating egocentric videos from a single exocentric input. EgoX leverages the pretrained spatio temporal knowledge of large-scale video diffusion models through lightweight LoRA adaptation and introduces a unified conditioning strategy that combines exocentric and egocentric priors via width and channel wise concatenation. Additionally, a geometry-guided self-attention mechanism selectively attends to spatially relevant regions, ensuring geometric coherence and high visual fidelity. Our approach achieves coherent and realistic egocentric video generation while demonstrating strong scalability and robustness across unseen and in-the-wild videos.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces EgoX, an AI system that can take a normal third‑person video (like a scene filmed by someone standing nearby) and turn it into a first‑person video (as if you were seeing through the main actor’s eyes). Think of watching a soccer match on TV (third‑person) versus wearing a player’s head‑mounted camera (first‑person). EgoX tries to create that player‑eye view from just one regular video.
What questions are the researchers trying to answer?
- Can we generate convincing first‑person videos using only a single third‑person video, even when the camera angle changes a lot?
- How can we keep important details (like people and objects) consistent while inventing parts of the scene the third‑person camera never saw?
- Can we guide the AI to focus on the useful parts of the third‑person video and ignore distracting background areas?
- Do these ideas work well on new, real‑world videos, not just controlled lab clips?
How did they do it?
The team combines three main ideas. Here they are in everyday language:
Step 1: Make a rough 3D guess of the scene to get a first‑person “preview”
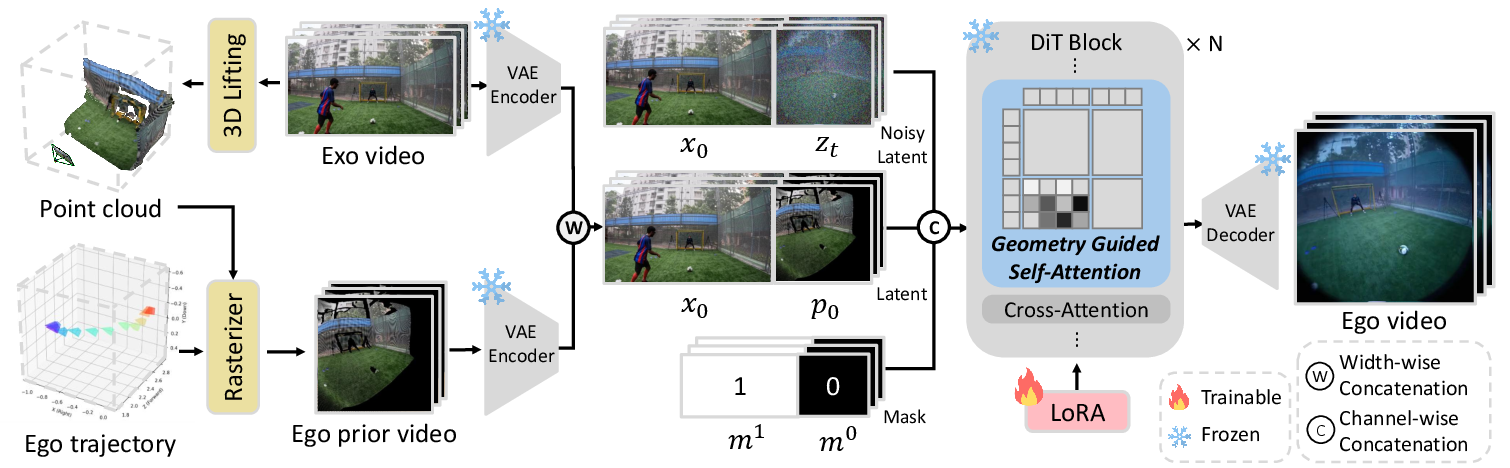
- The system estimates depth for each frame—how far away things are—so it can rebuild the scene as a 3D “point cloud” (imagine a cloud of tiny dots in space that trace the shapes of walls, tables, people, etc.).
- Then it “moves” a virtual camera to where the actor’s head would be and “renders” what that camera would see. This creates an egocentric prior: a rough first‑person video guess. It’s helpful but incomplete, because some parts were never visible in the original shot.
Analogy: It’s like building a quick Lego model of a room from photos and then taking a picture from a new spot inside the room.
Step 2: Use a powerful video‑making AI with two helpful hints
- They use a large video diffusion model. You can think of this as an artist who starts with a noisy, blurry video and repeatedly cleans it up until it looks real.
- The model is given two hints at the same time: 1) The rough first‑person “preview” (good for matching the correct viewpoint). 2) The original third‑person video (good for filling in missing details).
- The system feeds these hints in a special way:
- Channel‑wise with the first‑person preview: tells the model, “Here’s what the camera at the character’s eyes should roughly see.”
- Width‑wise with the third‑person video: tells the model, “Here’s the full scene context—use it to recover details even if the view is different.”
- They keep the third‑person hint “clean” (not noisy), so the model can copy fine details more reliably as it denoises the target.
- They fine‑tune the big model lightly using LoRA (small add‑on layers), which is like adding a tiny adapter instead of retraining the entire system.
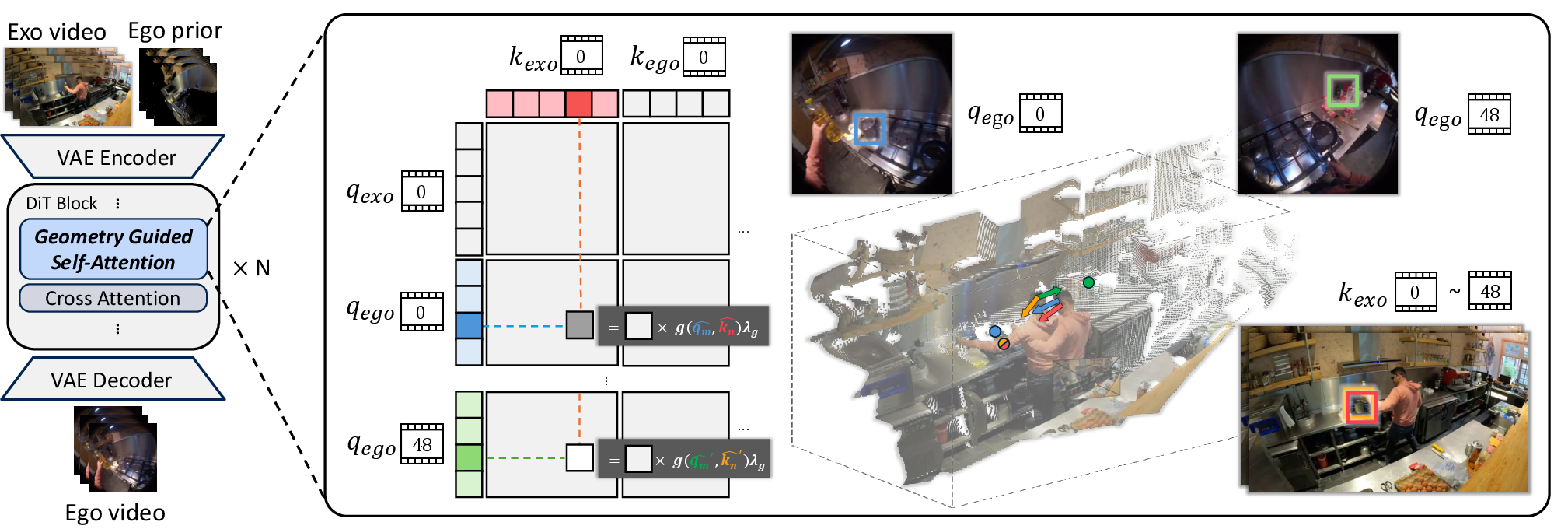
Step 3: Keep geometry consistent with smart attention
- The model has a self‑attention mechanism—like a spotlight that decides which parts of the input to focus on while generating each new frame.
- The researchers guide this spotlight with 3D geometry. They compare directions in 3D space (from the virtual first‑person camera to points in the scene) to decide which areas of the third‑person video truly line up with the first‑person view.
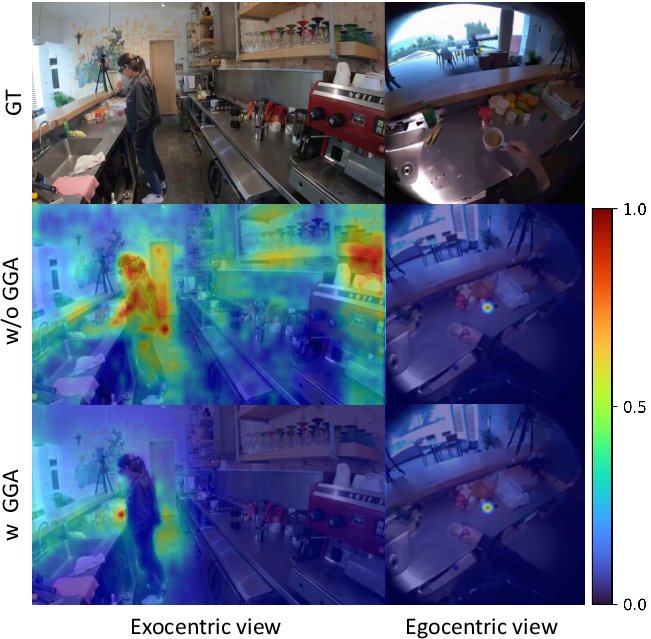
- If a region points in a similar direction, it gets more attention; if it doesn’t match, it gets less. This helps the model focus on the right content and ignore unrelated background.
Analogy: Imagine matching two maps by checking which landmarks line up from the same angle. If the angles match, you trust that landmark; if not, you ignore it.
What did they find, and why is it important?
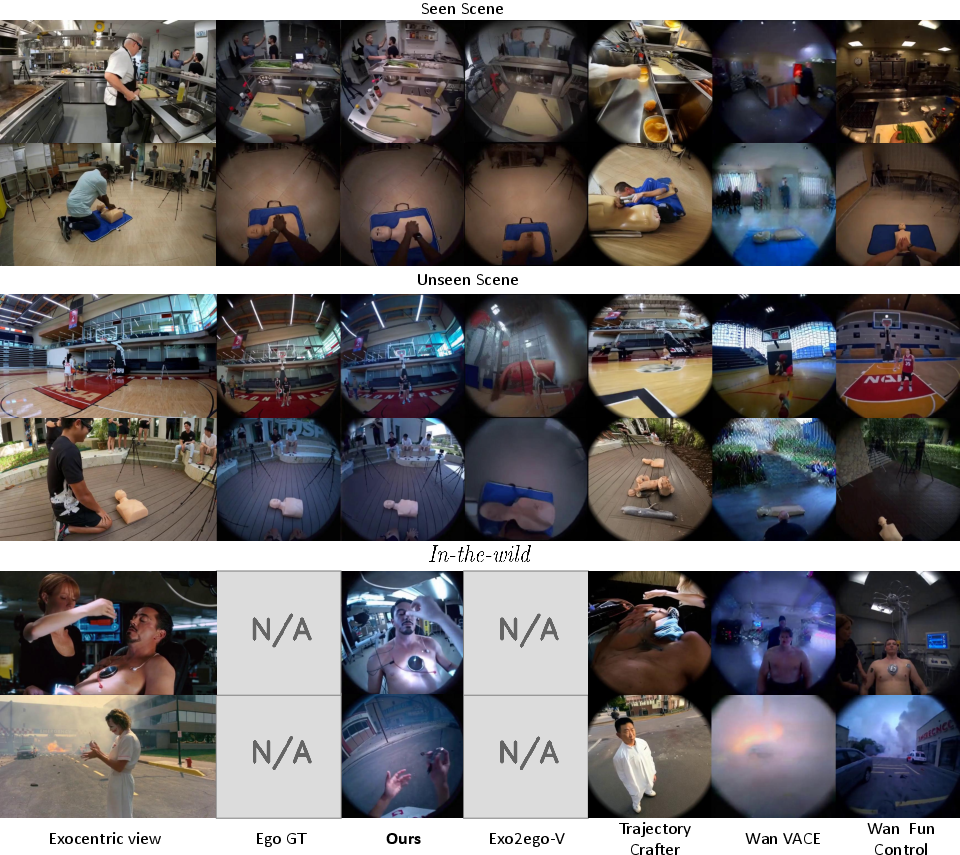
- Better quality videos: EgoX produced clearer, more realistic first‑person videos than other methods. It did well on scores for image quality, object accuracy (like where objects are and their shapes), and video smoothness over time.
- Stronger object consistency: It kept important scene geometry and object positions more accurate, which means the first‑person result made sense spatially.
- Works on new, real‑world clips: EgoX handled “in‑the‑wild” videos (like movie scenes) and still made convincing first‑person views.
- Every piece matters: When they removed any single part—like the 3D‑guided attention, the first‑person preview, or the clean third‑person hint—results got noticeably worse. This shows each idea adds value.
Why it matters:
- Creating first‑person views from ordinary videos helps filmmaking (immersive replays or alternate POV scenes), VR/AR (step inside a scene), and robotics (teaching robots by showing what a human would see while doing a task).
- It solves a tough problem: huge viewpoint changes with little overlap between cameras.
What could this change in the future?
- Entertainment and education: Viewers could “step into” famous scenes or sports moments. Students could experience lab demos or historical reenactments from the main character’s view.
- Training robots and assistants: First‑person views are closer to how a robot or a headset user sees the world, which could improve learning and interaction.
- AR/VR tools: Easier creation of immersive content from existing videos.
- Next step: Right now the system needs the actor’s head pose (where the first‑person camera should be). In the future, automatically estimating this from the video could make EgoX even easier to use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following items unresolved:
- Dependence on a known egocentric camera pose (
φ): no automatic estimation from the exocentric input, no sensitivity analysis to pose errors, and no method to recoverφwhen intrinsics/extrinsics are unknown or partially known. - Assumed availability of accurate camera intrinsics (exo and ego): handling unknown intrinsics, lens distortion, rolling shutter, or calibration drift is not addressed.
- Egocentric prior rendering masks dynamic objects (e.g., hands, moving people), limiting reconstruction of the most salient ego foreground; strategies to model/render dynamic components (e.g., 4D scenes, dynamic SLAM) are missing.
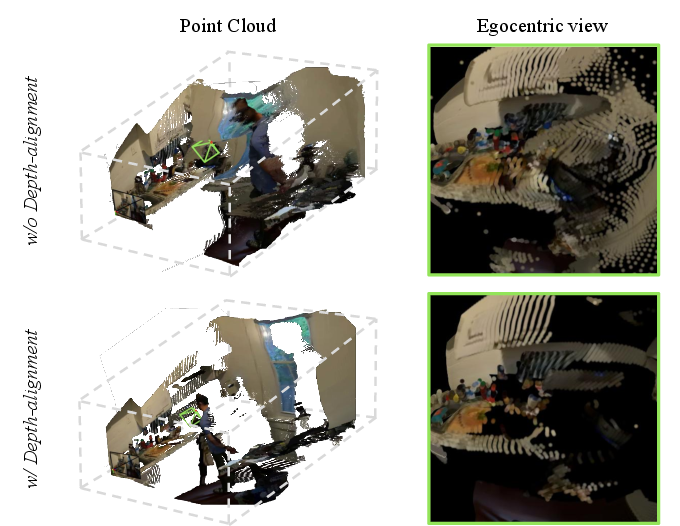
- Reliance on monocular/video depth alignment: failure modes under heavy occlusions, reflective/translucent surfaces, extreme lighting, or fast motion are not analyzed; no comparison across depth estimators or end-to-end learned geometry modules.
- Geometry-Guided Self-Attention (GGA) efficiency is unquantified: memory/time overhead for per-query–per-key geometry biases, scalability to higher resolutions/longer sequences, and real-time viability in AR/VR or robotics remain open.
- Ambiguity in mapping tokens to 3D points for GGA: how
\tilde{q}/\tilde{k}are defined when the point cloud is sparse/incomplete, and robustness to noisy/missing geometry are not specified; selection ofλ_gand its impact lacks ablation. - Unified concatenation may introduce seam artifacts or content leakage: mask design (
m) and boundary handling are under-specified; alternatives (e.g., learned warping fields, deformable/cross-attention, spatial transformers) are not explored. - Robustness to erroneous or low-quality egocentric priors (
P) is not evaluated: the model’s ability to correct wrong geometry, handle misaligned priors, and maintain world consistency is unclear. - Evaluation limitations in in-the-wild scenarios: absence of ground-truth egocentric views precludes quantitative assessment; no user studies or perceptual evaluation protocols for plausibility and embodiment fidelity.
- Dataset scale and coverage: training on 3,600 Ego-Exo4D clips may limit diversity; systematic generalization tests across cinematic footage, outdoor/nighttime, crowded scenes, and different domains are missing.
- Lack of metrics for first-person embodiment: fidelity of hand/body presence, hand–object interaction quality, gaze/heading realism, and near-field rendering are not directly measured.
- Baseline fairness and capacity: exclusion of certain exo-to-ego methods (e.g., EgoExo-Gen) and parameter mismatches across baselines (vs. Wan 14B) raise questions about comparability; no parameter-normalized or data-parity comparisons.
- Sensitivity to exocentric video artifacts: robustness to motion blur, stabilization artifacts, camera shake, compression, and heavy editing is not analyzed; preprocessing modules (stabilization, deblurring) are not integrated.
- Sequence length and drift: maximum supported duration, temporal drift over longer sequences, and memory constraints are not reported; no strategies for long-horizon consistency.
- AR/VR and robotics applicability: latency, hardware requirements, and feasibility of closed-loop, interactive use are not quantified; no discussion of safety-critical failure modes.
- Adaptation strategy breadth: LoRA rank/layer placement choices are fixed without ablations; trade-offs between reconstruction accuracy and hallucination quality as adaptation strength varies are unexplored.
- Ethical/privacy considerations: generating first-person views of identifiable individuals without consent and potential misuse are not discussed; safeguards and data governance are absent.
- Multi-actor/crowded scenes: disambiguation of which actor’s viewpoint to synthesize, selection of target identity, and handling occlusions between multiple agents are not addressed.
- Egocentric FOV and intrinsics selection: user control over FOV and intrinsics, their impact on output, and automatic inference/calibration remain open.
- Modeling ego–exo motion relationships: beyond geometric alignment, learning typical head–body motion couplings and behavioral priors for realistic ego motion is unexplored.
- Multi-view extension: although designed for single-view input, it is unclear how EgoX would fuse additional exocentric views when available and what performance gains/trade-offs result.
- Uncertainty quantification and controllability: no mechanism to estimate confidence in synthesized unseen regions, control hallucination levels, or expose diversity in plausible ego views.
- Reproducibility and accessibility: limited implementation details (e.g., exact LoRA injection points, masking policy, hyperparameters) and reliance on large compute (Wan 14B, 8×H200) hinder replication; code/model availability not stated.
Glossary
- 3D point cloud: A set of 3D points reconstructing scene geometry from depth, used for rendering new views. "we convert it into a 3D point cloud representation using the corresponding camera intrinsics."
- additive bias attention mask: A mask added to attention logits to bias attention scores toward certain key–query pairs. "use this term as an additive bias attention mask"
- affine transformation parameters: The parameters of a linear scaling and offset used to align signals across frames. "we optimize affine transformation parameters using a momentum-based update strategy"
- affine-invariant: Unchanged under affine transformations like scaling and translation. "produces a temporally smooth yet affine-invariant depth estimate."
- attention kernels: Optimized low-level implementations of attention operations reused for efficiency. "allowing us to reuse optimized attention kernels."
- attention logits: The pre-softmax scores computed from query–key similarity in attention. "the modified attention logits are formulated as:"
- attention weight: The normalized attention coefficient after applying softmax to logits. "the attention weight is computed as:"
- binary mask: A 0/1 map indicating which regions are conditioned versus synthesized. "and is the binary mask specifying whether each spatial region is used for conditioning or for synthesis."
- camera extrinsic parameters: Pose parameters (rotation/translation) that place the camera in world coordinates. "conditions the diffusion model directly on camera extrinsic parameters"
- camera intrinsics: Internal calibration parameters mapping 3D rays to image pixels. "using the corresponding camera intrinsics."
- channel-wise concatenation: Concatenating feature tensors along the channel dimension. "Wan Fun Control applies channel-wise concatenation for conditioning"
- clean latent: A non-noisy latent representation used as a stable conditioning signal during denoising. "Without the clean latent, the exocentric latent is concatenated in a noisy state"
- CLIP-I: An image-level similarity metric based on CLIP embeddings. "We measured PSNR, SSIM, LPIPS, and CLIP-I to assess how closely each generated frame matches the ground-truth distribution."
- cosine similarity: A measure of directional alignment between vectors based on the cosine of their angle. "we compute the cosine similarity between the two direction vectors and incorporate it into the attention computation as a multiplicative geometric prior."
- cross-attention: An attention mechanism where queries attend to a different set of keys/values to inject conditioning information. "employ cross-attention mechanisms to condition the generation on exocentric views."
- denoising function: The function predicting a cleaner latent from a noisier one in diffusion sampling. "where denotes a single-step denoising function of the VDM"
- denoising timesteps: The iterative steps in the reverse diffusion process during sampling. "throughout all denoising timesteps"
- DINOv3: A self-supervised vision transformer used here to match object correspondences. "and DINOv3~\cite{dinov3} to establish correspondences."
- egocentric camera pose: The first-person camera trajectory or poses used to render the ego view. "Given an exocentric video sequence and egocentric camera pose "
- egocentric prior: A rendered first-person video used as spatially aligned guidance for generation. "which becomes an egocentric prior video ."
- exocentric-to-egocentric video generation: Translating third-person videos into first-person perspectives. "Exocentric-to-egocentric video generation makes this possible by converting a third-person scene into a realistic first-person perspective."
- FVD: Fréchet Video Distance, a distributional metric for video quality and coherence. "We measured FVD~\cite{fvd} to evaluate how closely the generated video aligns with the ground-truth distribution."
- geometry-guided self-attention (GGA): Self-attention augmented with 3D geometric cues to focus on spatially aligned regions. "we introduce a Geometry-Guided Self-Attention (GGA) that adaptively emphasizes spatially corresponding regions between exocentric and egocentric representations."
- inpainting variant: A model variant that supports masked conditioning and channel-wise latent fusion. "we adopt the inpainting variant of Wan 2.1 (14B) Image-to-Video model~\cite{wan} as our base model."
- Intersection-Over-Union (IoU): The overlap ratio between predicted and ground-truth regions used to assess segmentation quality. "Intersection-Over-Union(IoU)"
- latent space: The compressed feature space produced by the encoder (e.g., VAE) in which diffusion operates. "combined via width-wise and channel-wise concatenation in the latent space"
- LPIPS: Learned Perceptual Image Patch Similarity, a perceptual image distance metric. "We measured PSNR, SSIM, LPIPS, and CLIP-I to assess how closely each generated frame matches the ground-truth distribution."
- LoRA: Low-Rank Adaptation, an efficient finetuning method that injects small trainable rank-decomposed updates. "We fine-tuned the model using LoRA (rank = 256) with a batch size of 1"
- monocular depth map: Depth estimated from a single RGB frame without stereo/multi-view input. "we first estimate a monocular depth map "
- momentum-based update strategy: An optimization approach using momentum to stabilize parameter updates. "using a momentum-based update strategy"
- multiplicative geometric prior: A geometry-derived factor incorporated into attention to bias it toward aligned directions. "incorporate it into the attention computation as a multiplicative geometric prior."
- pixel-wise correspondence: One-to-one alignment between source and target pixels across views. "preserves pixel-wise correspondence."
- Plücker coordinates: A line representation in 3D space used for camera/geometry formulations. "often represented as raw matrices or Plücker coordinates."
- point cloud renderer: A renderer that projects 3D point clouds into images from specified camera poses. "using a point cloud renderer~\cite{pytorch3d}"
- PSNR: Peak Signal-to-Noise Ratio, an image reconstruction fidelity metric. "We measured PSNR, SSIM, LPIPS, and CLIP-I to assess how closely each generated frame matches the ground-truth distribution."
- SAM2: A segmentation and tracking system used to evaluate object-level consistency. "We used SAM2~\cite{sam2} to segment and track objects"
- SDEdit: A diffusion-based editing method that conditions generation via noisy inputs. "which utilizes SDEdit~\cite{sdedit} by concatenating a noisy conditioning latent with a noisy target latent"
- SSIM: Structural Similarity Index, an image quality metric reflecting perceived similarity. "We measured PSNR, SSIM, LPIPS, and CLIP-I to assess how closely each generated frame matches the ground-truth distribution."
- temporal depth estimator: A model that estimates depth across frames to ensure temporal consistency. "using a temporal depth estimator~\cite{vda}"
- VAE: Variational Autoencoder, used to encode videos into latents for diffusion. "Both inputs are encoded by a frozen VAE encoder"
- VBench: A benchmark for evaluating video generation quality across temporal criteria. "we assessed VBench~\cite{vbench}-Temporal Flickering, Motion Smoothness, and Dynamic Degree"
- video diffusion model (VDM): A diffusion model that generates videos via iterative denoising in latent space. "where denotes a single-step denoising function of the VDM"
- width-wise concatenation: Concatenating feature tensors along the spatial width dimension. "combined via width-wise and channel-wise concatenation in the latent space"
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now or with minimal integration, along with target sectors, potential products/workflows, and key dependencies.
- Media post-production: switch-to-POV scenes without reshoots (Entertainment, Software)
- What: Generate actor’s-eye shots from a single on-set camera take for trailers, alternate cuts, or immersive releases.
- Tools/workflows: NLE/After Effects/Premiere/DaVinci plugins wrapping EgoX; pipeline = ingest exocentric clip → specify/estimate egocentric camera path → depth-and-render prior → EgoX generation → editorial review.
- Assumptions/dependencies: Access to scene camera trajectory or user-specified head pose; adequate exocentric coverage; compute budget for diffusion-based generation; rights/consent and IP clearance.
- Sports fan engagement highlights in player-POV (Sports media)
- What: Create curated “what the player saw” reels from broadcast footage for social and streaming platforms.
- Tools/workflows: Broadcast pipeline add-on with athlete pose/heading estimation (from pose trackers or manual annotation) feeding EgoX; batch generation during post-game.
- Assumptions/dependencies: Reliable head-pose estimation from single-view broadcast; scene depth quality in dynamic, occluded environments; editorial guardrails to avoid misleading depictions.
- E-learning and skill training conversion to first-person (Education, Corporate L&D)
- What: Turn third-person tutorials (e.g., cooking, assembly, lab procedures) into egocentric videos that improve learner transfer.
- Tools/workflows: LMS authoring plugin; instructors choose a camera path aligned with typical head motion; automated depth prior + EgoX generation; side-by-side exo/ego assets.
- Assumptions/dependencies: Consistent framing of the actor’s hands/tools; tolerable hallucination for unseen regions; disclosure that content is synthesized.
- Robotics research: egocentric data augmentation for imitation learning (Robotics, Academia)
- What: Convert exocentric demonstrations to first-person sequences to bridge viewpoint mismatch in policy learning.
- Tools/workflows: Dataset preprocessor wrapping EgoX; integration with behavior cloning / VLA pipelines; conditioning with approximate head/eye pose from skeleton or markers.
- Assumptions/dependencies: Not for safety-critical deployment without validation; label consistency and provenance; alignment with downstream reward/observation models.
- AR/VR previsualization for UX and scene design (Software, AR/VR)
- What: Preview user-perspective experiences from a single walkthrough video before building full interactive scenes.
- Tools/workflows: Unity/Unreal plug-in to import clips → set user path → synthesize ego sequences as previs references.
- Assumptions/dependencies: Non-real-time; approximate physics and occluders; designer-provided camera path when head pose is unavailable.
- Academic dataset bootstrapping for egocentric benchmarks (Academia)
- What: Expand egocentric datasets (e.g., Ego4D-style tasks) by generating paired exo↔ego clips from existing third-person libraries.
- Tools/workflows: Curated conversion scripts; uncertainty flags for hallucinated regions; automatic metadata, masks, and camera paths for reproducible splits.
- Assumptions/dependencies: Use only for pre-training/augmentation; strong evaluation against real egocentric ground truth to avoid bias.
- Consumer content: “relive-the-moment” from your eyes (Daily life, Consumer apps)
- What: Turn a friend’s phone video of you into a first-person memory for VR/phone playback.
- Tools/workflows: Mobile or desktop app with an interactive “camera path painter” UI; lightweight server-side generation.
- Assumptions/dependencies: Consent from all filmed parties; simplified head-path input; lower compute profiles with smaller backbones or cloud offload.
- Video diffusion R&D: geometry-guided attention and unified conditioning (Software, Research)
- What: Reuse GGA and clean-latent + width/channel concatenation to improve cross-view video editing and camera-control tasks.
- Tools/workflows: PyTorch modules for GGA; ControlNet-style conditioning adapters; LoRA recipes for large VDMs.
- Assumptions/dependencies: Access to pretrained video diffusion weights; stable depth/prior estimation.
- Policy & compliance add-ons: provenance and disclosure (Policy, Media)
- What: Watermarking and C2PA metadata insertion for all exo→ego outputs; standardized “synthetic POV” badges in UIs.
- Tools/workflows: Post-generation watermarking and manifest bundling; on-platform labels and content policies.
- Assumptions/dependencies: Platform support; consensus guidelines for egocentric synthesis disclosure.
Long-Term Applications
These opportunities require further research, scaling, or engineering (e.g., real-time performance, robust head-pose estimation, uncertainty quantification, or regulatory frameworks).
- Real-time AR/VR from fixed cameras to HMDs (AR/VR, Telecom)
- What: Live “see as me” experiences synthesized from a single room camera to a wearer’s HMD in telepresence or events.
- Tools/workflows: Low-latency head-pose tracking + fast depth priors + accelerated diffusion (distillation/streaming inference).
- Assumptions/dependencies: Real-time head/eye pose; fast geometry updates; compute at the edge; guardrails against motion sickness and artifacts.
- Coaching and rehab: near live athlete/student POV from venue cams (Sports, Healthcare)
- What: Provide immediate POV feedback for form, gaze, and situational awareness without wearable cameras.
- Tools/workflows: On-venue pose estimation + calibrated camera models + EgoX; coach dashboards with synchronized exo/ego views.
- Assumptions/dependencies: Accurate head/gaze inference; bias and artifact detection; athlete consent and privacy protections.
- Teleoperation/telepresence: operator-centric views from robot/external cams (Robotics)
- What: Synthesize “operator eyes” for better situational awareness using third-person robot feeds.
- Tools/workflows: Multi-sensor fusion; uncertainty overlays for hallucinated regions; fail-safes to prevent overtrust.
- Assumptions/dependencies: Safety-grade uncertainty estimation; latency control; regulatory approval for human-in-the-loop systems.
- Driver/pilot training simulators using surveillance feeds (Transportation, Education)
- What: Recreate approximate first-person scenarios from roadway/airfield cameras to broaden rare-event training data.
- Tools/workflows: City/airport camera calibration; scenario scripting; integrated uncertainty flags and quantitative validation.
- Assumptions/dependencies: Verified geometry; measurement of error bounds; barred from evidentiary use without strict validation.
- Forensics and insurance viewpoint approximation (Public safety, Insurance)
- What: Provide illustrative, non-evidentiary reconstructions of what a participant might have seen from CCTV.
- Tools/workflows: Judicial toolkits with strong provenance, confidence maps, and counterfactual warnings.
- Assumptions/dependencies: Clear disclaimers; legal standards; independent verification to avoid misuse and bias.
- Interactive media: switchable character POV in films/games (Entertainment, Gaming)
- What: Seamless viewer-controlled POV toggling in playback or cloud gaming from a single master take.
- Tools/workflows: Streaming platforms integrating per-character head-paths + on-demand generation caches.
- Assumptions/dependencies: Scalable inference; content rights and actor likeness agreements; latency constraints.
- Workplace ergonomics and safety analytics without bodycams (Manufacturing, Construction)
- What: Approximate worker POV from ceiling/fixed cameras to analyze reachability, visibility, and hazards.
- Tools/workflows: Facility camera calibration; annotated head paths by HSE specialists; automatic reporting.
- Assumptions/dependencies: Privacy-by-design; robust head-pose estimation under occlusion; validation against real headcam baselines.
- Large-scale synthetic egocentric corpora with auto head-pose (Academia, AI)
- What: Replace costly headcam data collection by converting open exocentric datasets to ego viewpoints for pretraining.
- Tools/workflows: Head-/gaze-pose estimators; dynamic-object-aware priors; quality metrics and filtering pipelines.
- Assumptions/dependencies: Bias audits; distribution shift tracking; licensing for original footage and generative models.
- Mobile/on-device consumer POV generation (Consumer software, Hardware)
- What: On-phone “instant POV” for short clips, integrated into camera/gallery apps.
- Tools/workflows: Distilled or sparse diffusion models; hardware acceleration (NPU/GPU); simplified user-driven head paths.
- Assumptions/dependencies: Energy and memory limits; privacy; acceptable quality-speed tradeoffs.
- Standards and governance for egocentric synthesis (Policy)
- What: Develop norms for consent, provenance, disclosure, and watermark durability specific to first-person reconstructions.
- Tools/workflows: Cross-industry working groups; C2PA profiles for video; automated platform labeling and audit logs.
- Assumptions/dependencies: Multi-stakeholder adoption; alignment with deepfake legislation; international harmonization.
Cross-cutting dependencies and assumptions
- Pose availability: EgoX requires an egocentric camera pose trajectory; when not available, robust head-/gaze-pose estimation is needed.
- Geometry priors: Quality of monocular+temporal depth and dynamic-object masking impacts fidelity; indoor/static scenes are easier than fast, cluttered outdoor sports.
- Compute and model access: Large video diffusion backbones and GPU resources (or distilled variants) are required; licensing of pretrained weights must be respected.
- Safety and trust: Outputs can plausibly synthesize unseen regions; for safety-critical or evidentiary uses, uncertainty quantification, provenance, and human oversight are essential.
- Rights and privacy: Consent from subjects, compliance with privacy laws, and clear disclosure/watermarking are necessary for deployment in products and platforms.
Collections
Sign up for free to add this paper to one or more collections.