- The paper introduces dual self-consistency reinforcement learning to enforce both visual fidelity and symbolic code alignment in TikZ synthesis.
- It leverages an execution-centric SciTikZ-230K dataset spanning 11 scientific domains to reduce syntax errors and achieve precise geometric rendering.
- Empirical results show a 97.2% compilation rate and superior performance over state-of-the-art MLLMs, highlighting robust, high-fidelity synthesis.
Scientific Graphics Program Synthesis via Dual Self-Consistency Reinforcement Learning
Motivation and Challenges
Graphics program synthesis seeks to recover editable, high-fidelity symbolic code from static visual data, with TikZ as the gold standard for scientific schematics due to its expressiveness and spatial precision. MLLMs have recently demonstrated compelling code generation capabilities, yet TikZ synthesis exposes their limitations: existing open-source MLLMs systematically fail on strict syntactic requirements, hallucinate dependencies, and do not achieve adequate geometric alignment (Figure 1).
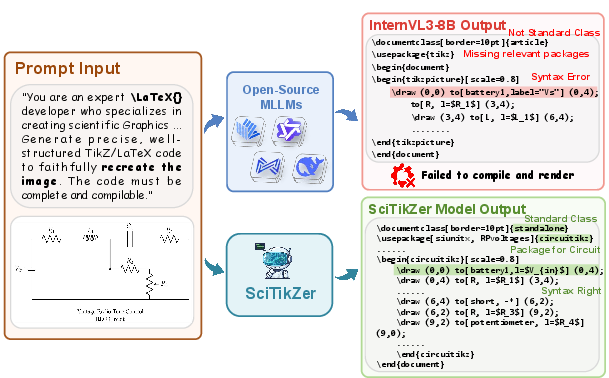
Figure 1: Core failure modes in MLLMs for TikZ synthesis, including syntax hallucinations, missing dependencies, and misaligned geometry.
This deficiency largely arises from two core gaps: (1) a lack of strictly-compilable and visually-aligned image–TikZ corpora to drive supervised learning; and (2) the absence of benchmarks encompassing both visual and code-level fidelity for robust model evaluation. This limits both the capacity to train models that align visuals with TikZ’s structure and the ability to systematically compare methods.
SciTikZ-230K and the Execution-Centric Data Engine
To ameliorate the data quality gap, the authors propose the SciTikZ-230K dataset generated by an Execution-Centric Data Engine (Figure 2). Rather than passively filtering noisy web-scraped datasets, this pipeline implements active, MLLM-guided remediation, iteratively repairing uncompilable samples using diagnostic logs and LLM interventions. Heuristic and fine-grained semantic filtering using large vision-LLMs further eliminate redundancy, enforce standardization, and guarantee visual–code isomorphism.
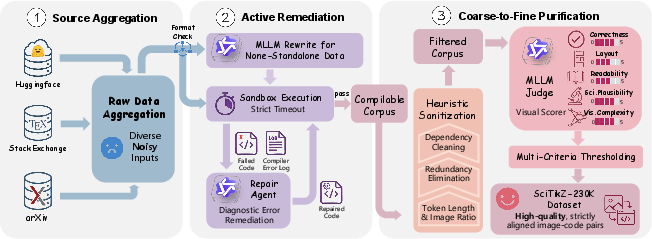
Figure 2: The Execution-Centric Data Engine integrates diagnostic remediation and multi-granular evaluation to curate robust, compilable visual–TikZ pairs.
The resulting dataset spans 11 scientific domains and over 90 subcategories, covering both broad and specialized schematic structures (Figure 3). This curation produces a highly diverse and high-quality corpus (230K instances), directly addressing the limitations of synthetic or fragmented corpora prevalent in prior work.
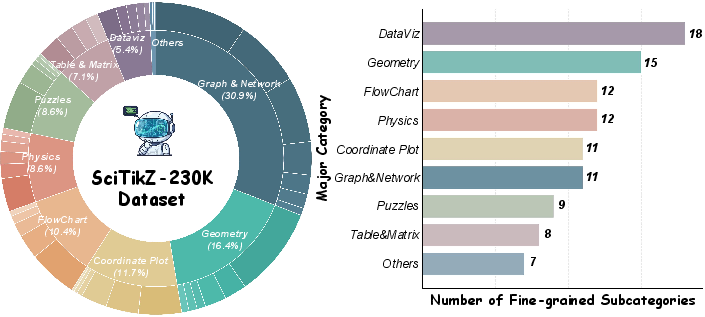
Figure 3: Distribution of SciTikZ-230K, capturing the domain heterogeneity critical for robust program synthesis.
SciTikZer Model and Dual Self-Consistency Reinforcement Learning
The proposed SciTikZer model leverages a three-stage training framework (Figure 4):
- Supervised fine-tuning (SFT) initializes the policy on the curated dataset, enforcing canonical TikZ syntax.
- Curriculum Data Selection selects RL data focusing on intermediate-difficulty instances determined via visual complexity and model confidence, ensuring efficient use of RL resources.
- Dual Self-Consistency (DSC) Reinforcement Learning comprises two RL stages—visual fidelity alignment (with render-based rewards) followed by round-trip symbolic self-consistency (DSC-RL). The DSC paradigm demands that generated code is both visually faithful and structurally invertible: the model must reconstruct its own code from the rendered image, penalizing degenerate or logically inconsistent outputs.
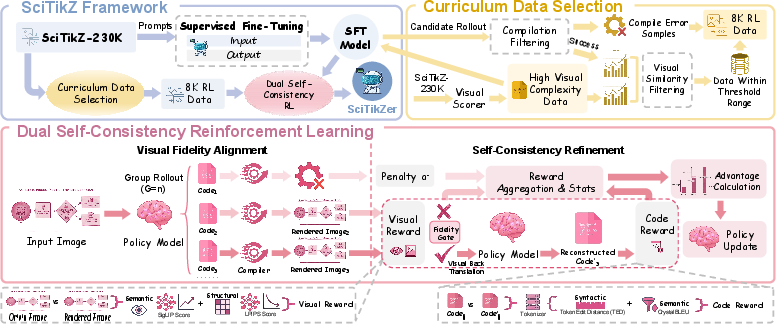
Figure 4: Overview of SciTikZ's training framework: SFT, curriculum selection, and DSC-RL drive both pixel-level and symbolic alignment.
Unlike SFT or standard visual RL that can tolerate logical degeneracies, DSC explicitly enforces consistency between the visual output and the underlying code, closing reward-hacking loopholes and integrating execution feedback directly into the optimization loop.
Benchmarking: SciTikZ-Bench and Evaluations
To facilitate rigorous, multi-dimensional evaluation, the authors construct SciTikZ-Bench—a 611-sample, stratified benchmark with human and automated verification, encompassing basic (Easy), intermediate (Medium), and complex (Hard) scientific diagrams (Figure 5).
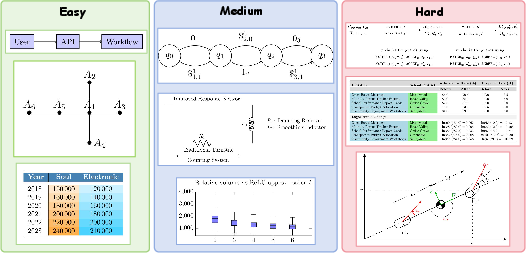
Figure 5: SciTikZ-Bench samples categorized by difficulty, supporting granular diagnostic evaluation of model performance.
Evaluation protocols combine semantic and structural image similarity (SigLIP, CLIP, LPIPS, SSIM, DreamSim) with code-level metrics (CrystalBLEU, Token Edit Distance). Compilation success rate acts as a hard constraint, penalizing non-executable generations.
Experimental Results
Main Results
SciTikZer-8B outperforms all evaluated proprietary, open-source, and task-specific MLLMs—including Gemini-2.5-Pro and Qwen3-VL-235B—on SciTikZ-Bench, achieving a 97.2% compilation rate, SigLIP of 93.8, and lowest perceptual distance (LPIPS of 29.7). While certain baselines score marginally higher on n-gram overlap (C-BLEU), SciTikZer maintains lower TED, evidencing better structural alignment and less lexical overfitting.
Training Dynamics and Ablation
Progressive training analysis (SFT → RL → DSC-RL) confirms cumulative improvements: visual RL stage provides the largest boost in perceptual fidelity; DSC-RL then further enhances logical consistency, as evidenced by improved compilation and code alignment metrics.
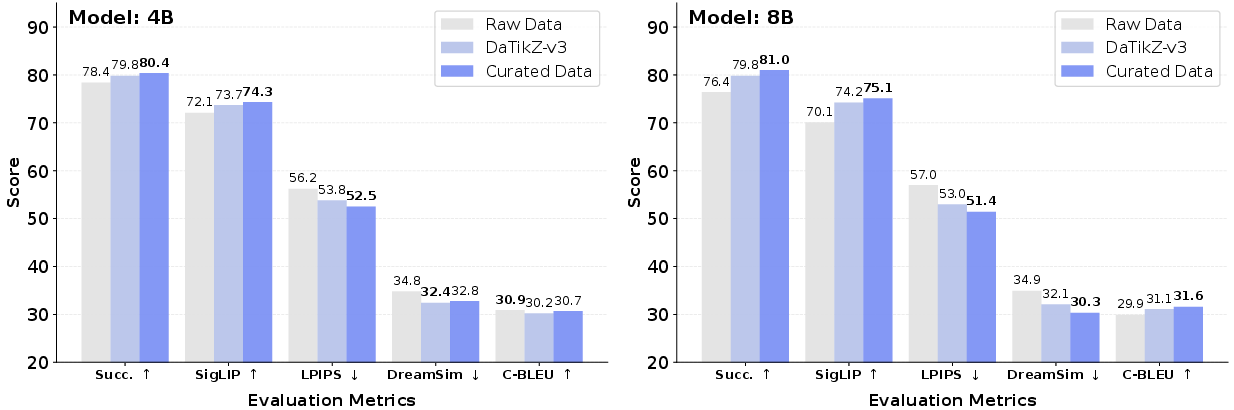
Figure 6: Impact of data curation on compilation rates and visual fidelity, showing substantial improvements over raw or less curated data.
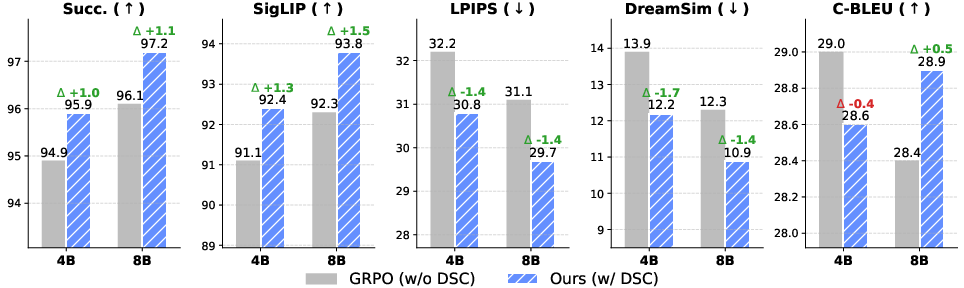
Figure 7: Ablation demonstrates the added value of the DSC paradigm versus standard RL.
Qualitative Assessments
Qualitative and human evaluations corroborate the automated findings: SciTikZer-8B consistently produces structurally and visually faithful TikZ code, reducing syntax hallucinations and topological errors compared to SOTA baselines.
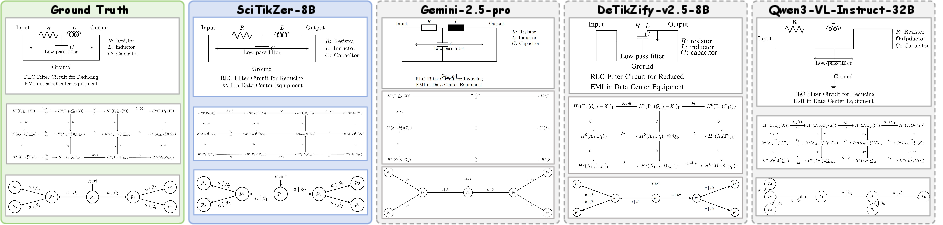
Figure 8: Case analysis comparing SciTikZer-8B and baselines, highlighting superior geometric and dependency alignment.

Figure 9: Qualitative remediation results across diverse cases, evidencing robust error correction and high-fidelity synthesis.

Figure 10: Detailed synthesis example reveals SciTikZer’s strong code hygiene, idiomatic usage, and minimal artifacts.
Generalization and Framework Versatility
Application of the DSC-RL methodology to Python (Matplotlib) synthesis settings confirms its generality: performance improvements extend to imperative visual code domains, indicating that the paradigm is not TikZ-specific but of broader utility in visual program synthesis.
Implications and Future Directions
This framework delivers robust, visually-grounded TikZ synthesis from images, addressing both practical (editable schematic recovery, semi-automated diagram editing) and theoretical (multimodal consistency regularization, closed-loop RL for program synthesis) research objectives. It sharply improves over prior architectures where RL could enable reward exploitation or SFT-induced rigidity.
Future research directions include inference-time iterative self-correction using compiler feedback, interactive sketch-to-TikZ, and expansion to other formal graphics languages (e.g., SVG, Asymptote). Systemic limitations remain, notably the computational overhead of DSC-RL and sensitivity to LaTeX environment configuration.
Conclusion
This work presents an end-to-end pipeline for scientific graphics program synthesis, delivering strong performance through data curation, a dual self-consistency RL paradigm, and comprehensive evaluation infrastructure. Empirically, the proposed system pushes the Pareto frontier in visual and structural fidelity for TikZ synthesis, suggesting reinforcement learning with dual, verifiable signals is essential for robust, executable neural program synthesis in scientific domains.