- The paper introduces AIBench, a benchmark that decouples logical consistency from aesthetic quality using hierarchical QA evaluation.
- The paper presents a compositional framework that employs text-to-logic graph construction and multi-level QA generation to assess diagram fidelity.
- The paper demonstrates that closed-source models achieve higher logical scores while open-source models lag, highlighting challenges in method diagram generation.
AIBench: Benchmarking Visual-Logical Consistency in Academic Illustration Generation
Motivation and Limitations of Existing Approaches
The recent surge in T2I and unified multimodal models has advanced generative capability for a broad spectrum of visual content. However, the automatic generation of academic illustrations—method diagrams that require both dense informational content and consistent logical structure—remains a domain with stringent requirements unmet by current evaluation protocols. Legacy benchmarks such as PaperBananaBench and AutoFigure depend on holistic VLM-as-Judge paradigms, which entangle logical accuracy with aesthetic quality and obfuscate failure factors due to VLM instability. The challenge amplifies when evaluating alignment between complex, long-form methodological texts and their visual counterparts, where logical interpretability and cross-modal reasoning are paramount.
The AIBench Framework
AIBench introduces a rigorous, compositional, and fine-grained evaluation pipeline that explicitly decouples logical consistency from subjective aesthetics, establishing a new protocol for academic illustration generation evaluation (Figure 1).
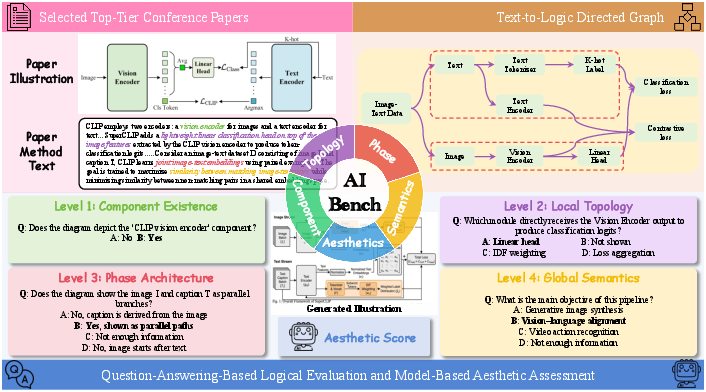
Figure 1: Overview of AIBench, emphasizing its bidimensional evaluation: logical consistency via multi-level QA and aesthetics by model assessment.
Data Acquisition and Curation
The benchmark dataset is curated from 2025 papers spanning CVPR, ICCV, NeurIPS, and ICLR, ensuring both topical and methodological diversity (Figure 2). Each entry comprises a method text, a reference diagram, and carefully-constructed multi-level QA pairs.

Figure 3: Data statistics reflecting source, hierarchical evaluation breakdown, and topic diversity.
Key dataset statistics:
- 300 samples, 5,704 QA pairs
- Four logic levels: Component, Topology, Phase, Semantics
- Full topical coverage: diffusion models, LLMs, multimodal learning, 3D reconstruction
Multi-Level Logic QA Construction
A two-stage pipeline underpins QA synthesis:
- Text-to-Logic Directed Graph Construction: Gemini 3 Flash synthesizes a G=(V,E,P) logic graph from method text, grounding modular architecture in nodes (V: modules and artifacts), edges (E: data flows), and phases (P: procedural segments). This ensures structural faithfulness, preserves domain terminology, and mitigates unstructured textual ambiguity (Figure 4).
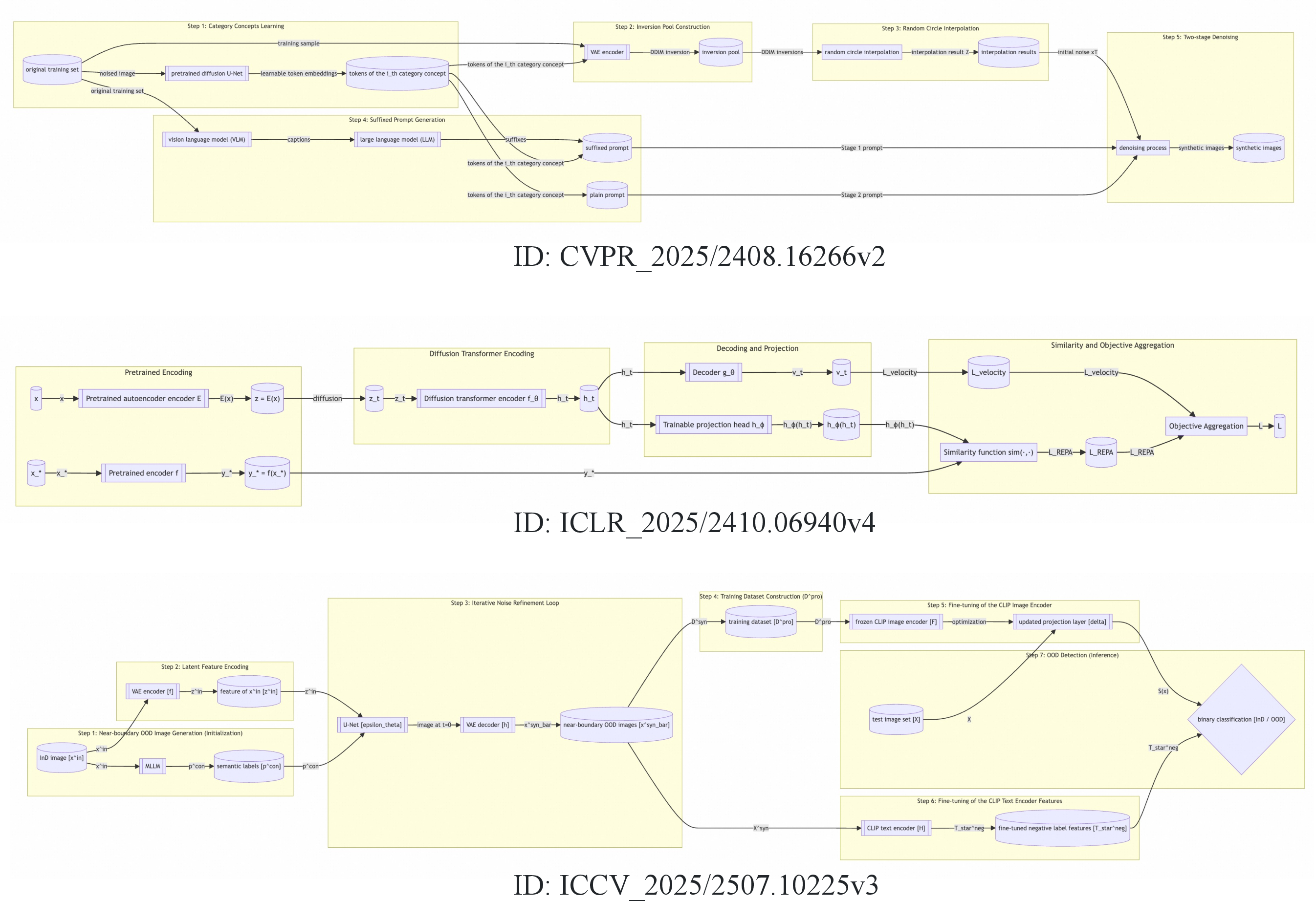
Figure 2: Example text-to-logic graphs, illustrating node/edge/phase correspondence for semantic parsing.
- Hierarchical QA Generation: Level-specific generators produce multiple-choice QAs at four scales:
- Component Existence: Node presence and annotation correctness.
- Local Topology: Inter-node connectivity and routing fidelity.
- Phase Architecture: Macro-structural composition, spatial organization, feedback paths.
- Global Semantics: End-to-end design intent and paradigm mapping.
Manual filtering eliminates QA hallucinations (by cross-verification with Gemini and human experts), ensuring high factual integrity.
Evaluation Protocol
Evaluation proceeds along two axes (Figure 5):
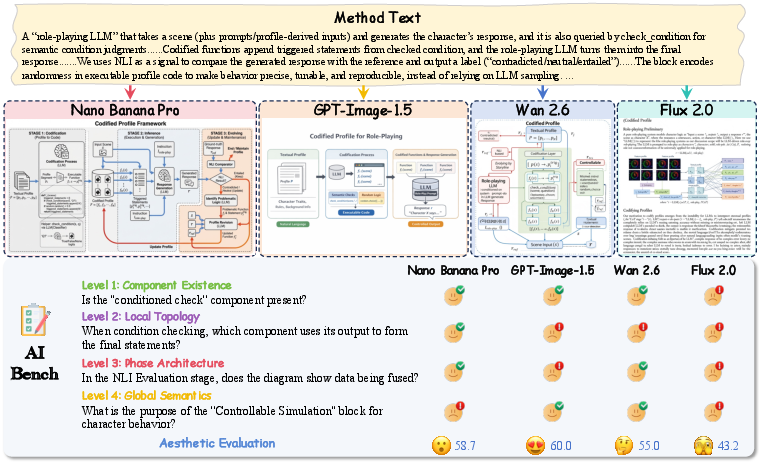
Figure 5: The dual-track pipeline decomposes evaluation into explicit logical QA and aesthetic scoring.
- VQA-based Logic Assessment: For each figure and associated QA pairs, an MLLM solver (Qwen3-VL-235B-A22B-Instruct) predicts answers without external textual cues. Each of the four hierarchical logic levels is scored independently, aggregating to a global accuracy metric.
- Model-based Aesthetic Judgment: Aesthetics are assessed via UniPercept, a specialized perceptual model providing continuous [0,100] quality scores, outperforming generic VLM and CLIP-based methods in correlation with human preferences (Figure 6).
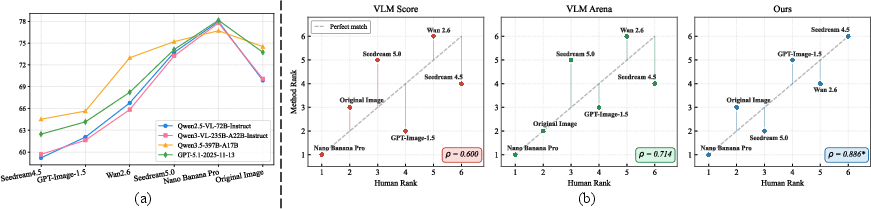
Figure 7: Empirical robustness analysis of VLM solvers and correlation of evaluation ranks with human judgments.
The composite AIBench score is defined as the arithmetic mean of the four logic dimension scores (scaled [0,100]) with the aesthetic score.
Empirical Evaluation and Observations
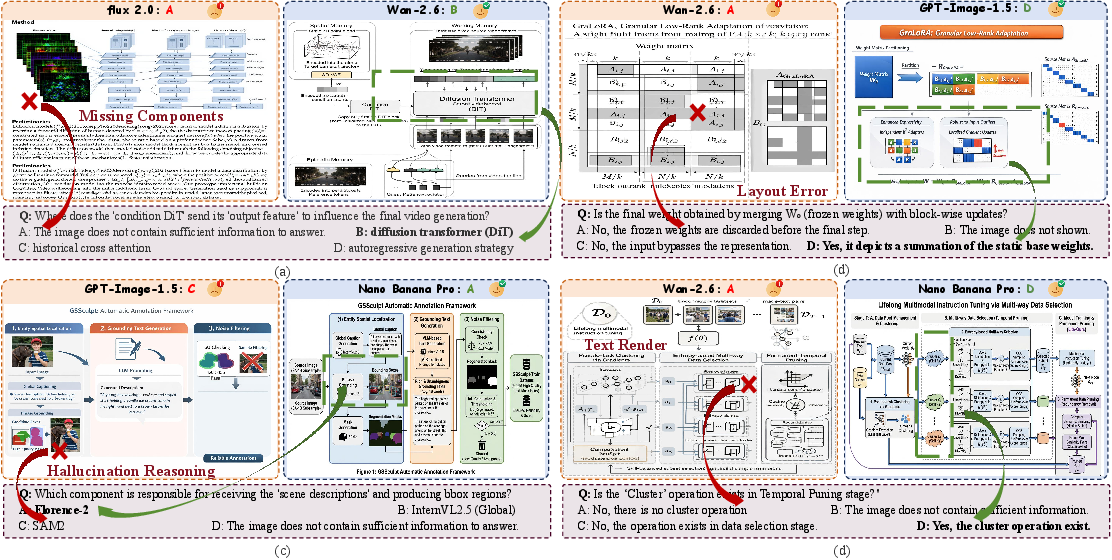
AIBench exposes a marked performance stratification between closed- and open-source models. Closed-source models (e.g., Nano Banana Pro, Seedream 5.0) achieve overall scores above 73, outperforming the Original Image reference in several logic categories. Open-source models (e.g., Qwen-Image, FLUX2-dev) remain limited (<43 overall), and unified open-source models (e.g., BAGEL, UniWorld) underperform on both structure and fidelity due to deficient methodological text understanding and weak scene composition.
Qualitative failure analysis (Figure 7) reveals the prevalent deficits:
Logical vs. Aesthetic Trade-off
Notably, there exists a pronounced trade-off: models achieving higher logical scores often incur aesthetic penalties (e.g., SVG-based pipeline outputs). Conversely, models prioritizing aesthetics (e.g., GPT-Image-1.5) can underperform in logical dimensions, underscoring the dual-nature challenge of academic illustration generation.
Test-Time Scaling Strategies
AIBench paves the way for effective test-time scaling (TTS) interventions, empirically validated in the study:
- Reasoning-Phase Scaling: LLM-driven prompt rewriting or intermediate SVG code planning dramatically boosts the scores of open-source T2I models, e.g., rewriting raises Qwen-Image-2512 from 42.8 to 58.4.
- Generation-Phase Scaling: Post-hoc editing (e.g., Best-of-N sampling, MLLM-based correction/refinement) improves rendering accuracy in models with adequate planning ability (e.g., Wan2.6 rising by several points).
Yet, rigid intermediates (SVG code) provide diminishing returns for models with strong native comprehension, and can bottleneck models unable to parse such structures, highlighting that TTS efficacy is model-capacity dependent.
Robustness and Human Alignment
AIBench demonstrates low sensitivity to the evaluation VLM choice at a relative ranking level, and its scores correlate strongly with aggregate human expert rankings (Spearman ρ=0.89), surpassing alternative VLM-judge metrics. This robustness is essential for reliable longitudinal and comparative studies.
Broader Implications and Future Research Directions
By establishing a reproducible, interpretable, and fine-grained benchmark, AIBench enforces new standards for evaluation in academic illustration generation, a critical capability for scientific communication. The decoupled dual-track evaluation clarifies distinctions between logical incompleteness and stylistic flaws, enabling more targeted diagnostic research.
Several implications and future trajectories emerge:
- Architectural advances are required to boost long-context structured comprehension, explicit reasoning, and robust scene planning.
- Generalization beyond AI: Expanding the benchmark to non-AI scientific fields (biology, chemistry, etc.) to assess cross-domain transfer and new diagrammatic conventions is a natural next step.
- Unified logic-visual alignment: Model innovation should emphasize joint optimization of logic fidelity and aesthetics, possibly via reinforcement learning reward specification directly tied to multi-level logic objectives and perceptual quality.
- Diagram-type expansion: Beyond method diagrams, future tasks should include flowcharts, process trees, and discipline-specific illustrations.
Conclusion
AIBench constitutes a rigorous, compositional, and interpretable framework for academic illustration generation evaluation. By combining hierarchical logic-grounded QA with perceptually aligned aesthetic assessment, it exposes real capability gaps that are invisible to legacy benchmarks. The insights derived steer research towards next-generation generative AI systems with deep logical grounding and high visual fidelity, catalyzing progress in scientific communication tools for the research community.
Reference: "AIBench: Evaluating Visual-Logical Consistency in Academic Illustration Generation" (2603.28068).