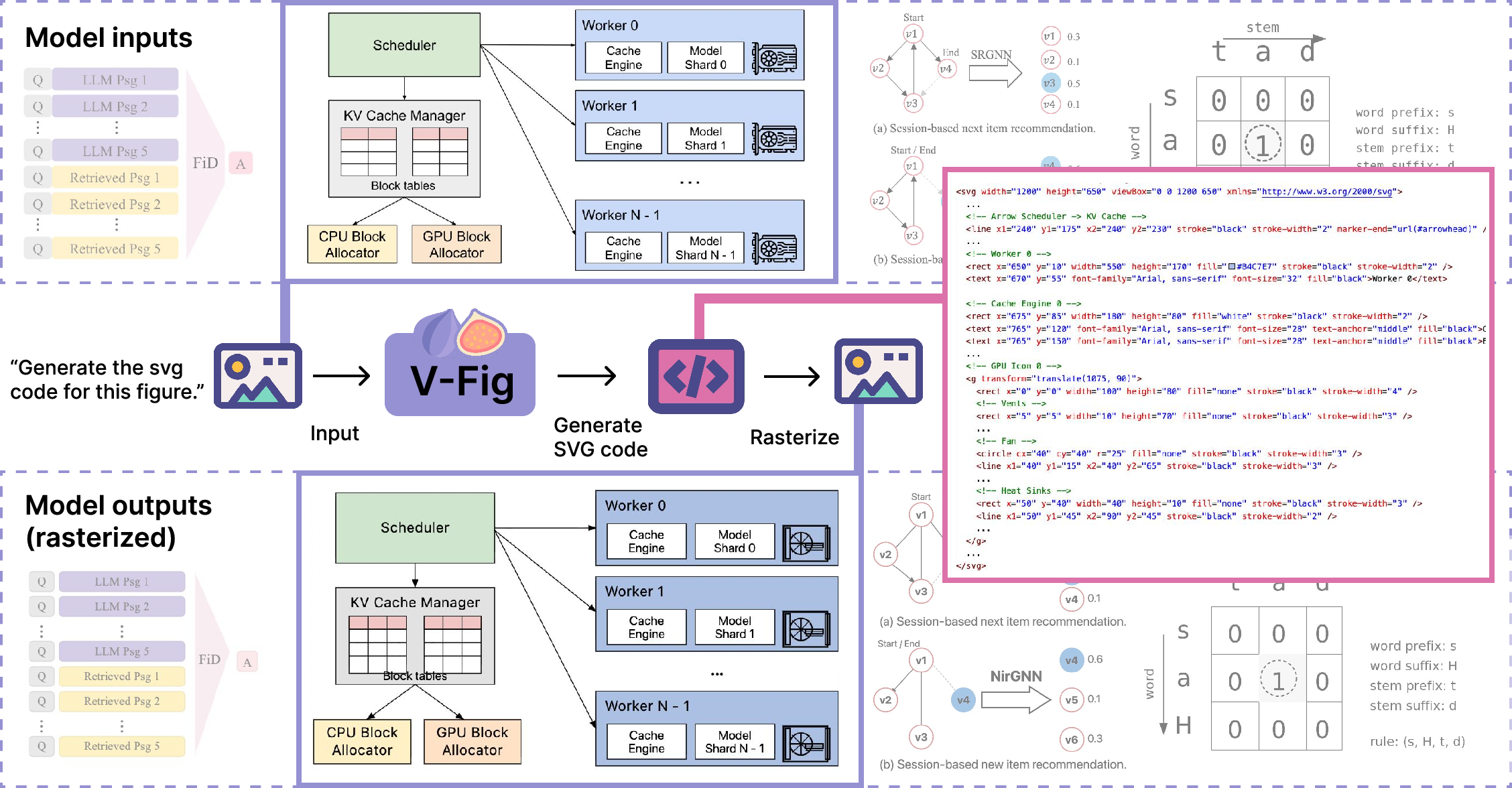
VFIG: Vectorizing Complex Figures in SVG with Vision-Language Models
Abstract: Scalable Vector Graphics (SVG) are an essential format for technical illustration and digital design, offering precise resolution independence and flexible semantic editability. In practice, however, original vector source files are frequently lost or inaccessible, leaving only "flat" rasterized versions (e.g., PNG or JPEG) that are difficult to modify or scale. Manually reconstructing these figures is a prohibitively labor-intensive process, requiring specialized expertise to recover the original geometric intent. To bridge this gap, we propose VFIG, a family of Vision-LLMs trained for complex and high-fidelity figure-to-SVG conversion. While this task is inherently data-driven, existing datasets are typically small-scale and lack the complexity of professional diagrams. We address this by introducing VFIG-DATA, a large-scale dataset of 66K high-quality figure-SVG pairs, curated from a diverse mix of real-world paper figures and procedurally generated diagrams. Recognizing that SVGs are composed of recurring primitives and hierarchical local structures, we introduce a coarse-to-fine training curriculum that begins with supervised fine-tuning (SFT) to learn atomic primitives and transitions to reinforcement learning (RL) refinement to optimize global diagram fidelity, layout consistency, and topological edge cases. Finally, we introduce VFIG-BENCH, a comprehensive evaluation suite with novel metrics designed to measure the structural integrity of complex figures. VFIG achieves state-of-the-art performance among open-source models and performs on par with GPT-5.2, achieving a VLM-Judge score of 0.829 on VFIG-BENCH.
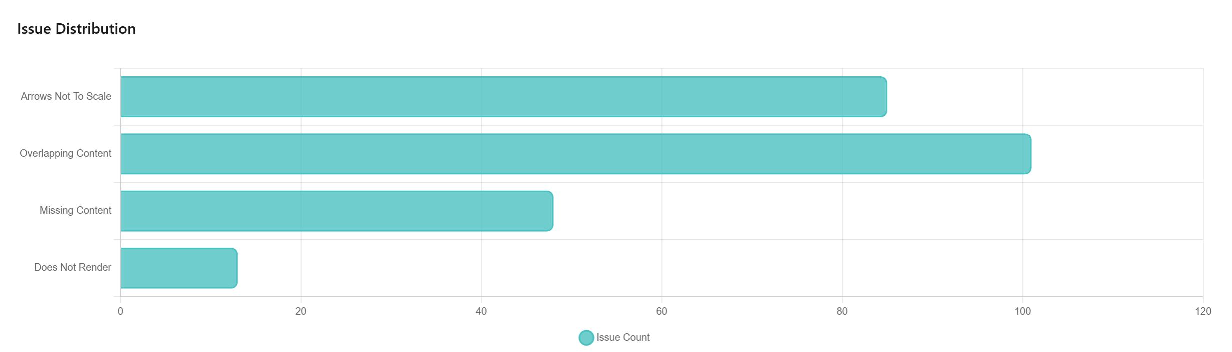
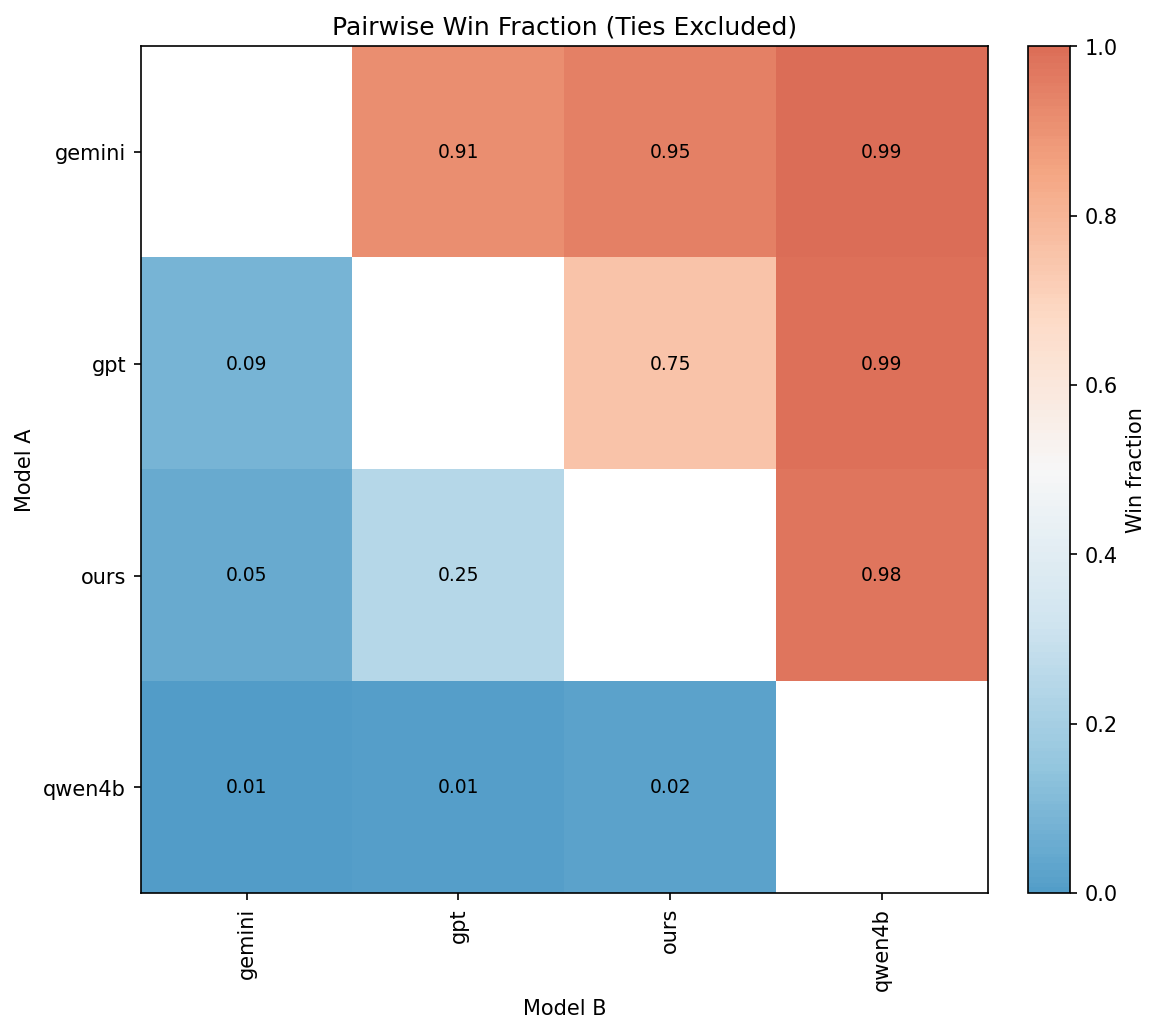
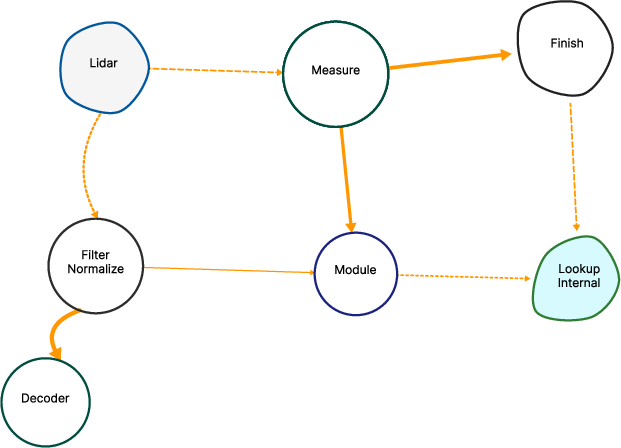
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces VFig, an AI system that turns pictures of complex diagrams (like flowcharts or science figures saved as PNG/JPG) back into clean, editable vector graphics called SVGs. Think of it like taking a photo of a poster and recreating the original design file so you can change the text, move shapes, or resize it without getting blurry.
SVGs are great because they’re:
- Sharp at any size (no pixel blur).
- Easy to edit (they’re made of shapes and text, not just colored dots).
- Written as code, so both people and programs can understand and modify them.
But people often lose the original SVGs and only have images. Manually rebuilding them is slow and hard. VFig aims to do this automatically, even for complicated figures with many boxes, arrows, and labels.
What questions did the researchers ask?
They focused on four simple questions:
- Can modern AI models turn complex diagram images into accurate, editable SVGs?
- Does teaching the AI from simple to complex examples (a “curriculum”) help it learn better?
- If the AI gets feedback on how its drawings look (like a coach scoring its results), does it improve?
- Is high-level, structure-based feedback (Are the boxes aligned? Do the arrows connect correctly?) more helpful than low-level pixel comparisons (Do the pictures look similar)?
How did they try to solve it?
They combined smart data, careful training, and better evaluation. Here’s the idea in everyday terms.
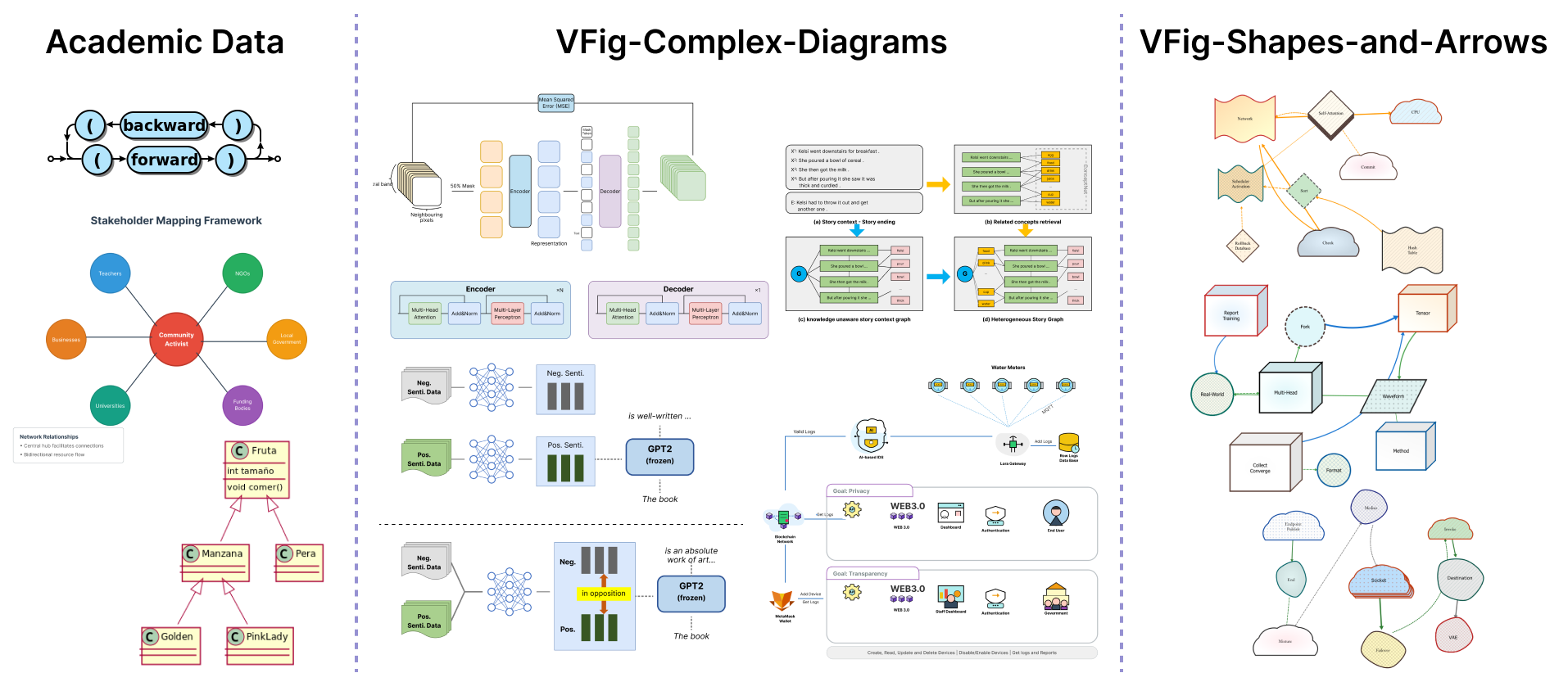
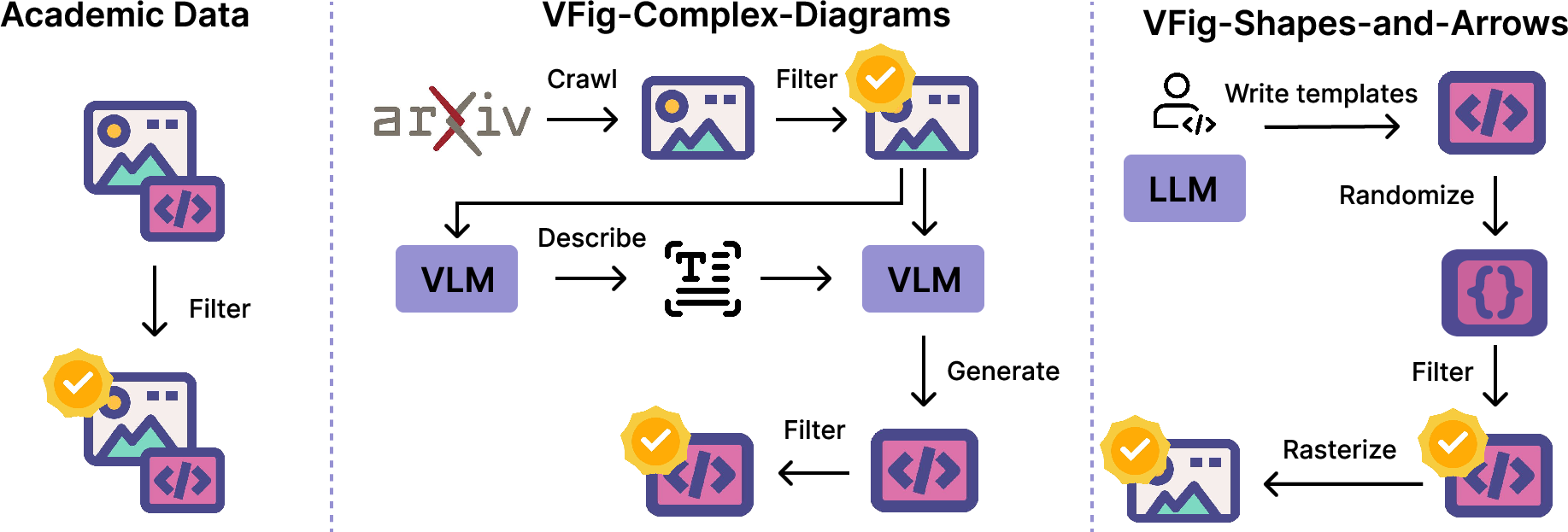
Building the training data
- They created VFig-Data, a large set of 66,000 pairs of images and their matching SVGs. These include:
- Real figures from scientific papers (flowcharts, model diagrams, multi-panel layouts).
- Programmatically generated diagrams created from templates with randomized shapes, arrows, fonts, and styles, so the AI sees many variations.
- They filtered out things that don’t convert well to clean SVGs, like natural photos, screenshots, and heavy math equations.
- They also removed “path-heavy” SVGs (which are like long squiggly lines with tons of coordinates) because those are hard to edit and hard for the AI to learn from. Instead, they prefer simple shapes like rectangles, circles, and lines.
Analogy: They gave the AI a huge workbook filled with clear, well-organized examples instead of messy ones.
Teaching the model in two stages
- Step 1: Supervised Fine-Tuning (SFT)
- The AI learns by copying examples. First, it practices on simpler diagrams to master basic “primitives” (rectangles, circles, text) and neat layouts. Then it moves to more complex scientific figures.
- Analogy: Learn to draw basic shapes and arrange them before tackling full posters.
- Step 2: Reinforcement Learning (RL) with visual feedback
- After the basics, the AI “draws” SVGs from images and gets scored by another AI “judge” on:
- Presence: Are all the right parts there (boxes, arrows, labels)?
- Layout: Are things placed and aligned correctly?
- Connectivity: Do arrows connect the right things?
- Details: Are fonts, colors, and text right?
- The AI improves by trying different versions and keeping the ones that score better.
- Analogy: A student draws a diagram, a coach grades it on several rubrics, and the student iterates to improve.
Technical note in simple terms: The team used a vision-LLM (a model that sees and writes) and trained the text part to output SVG code. They “render” the code (turn it into an image) to compare it to the original.
How they measured success
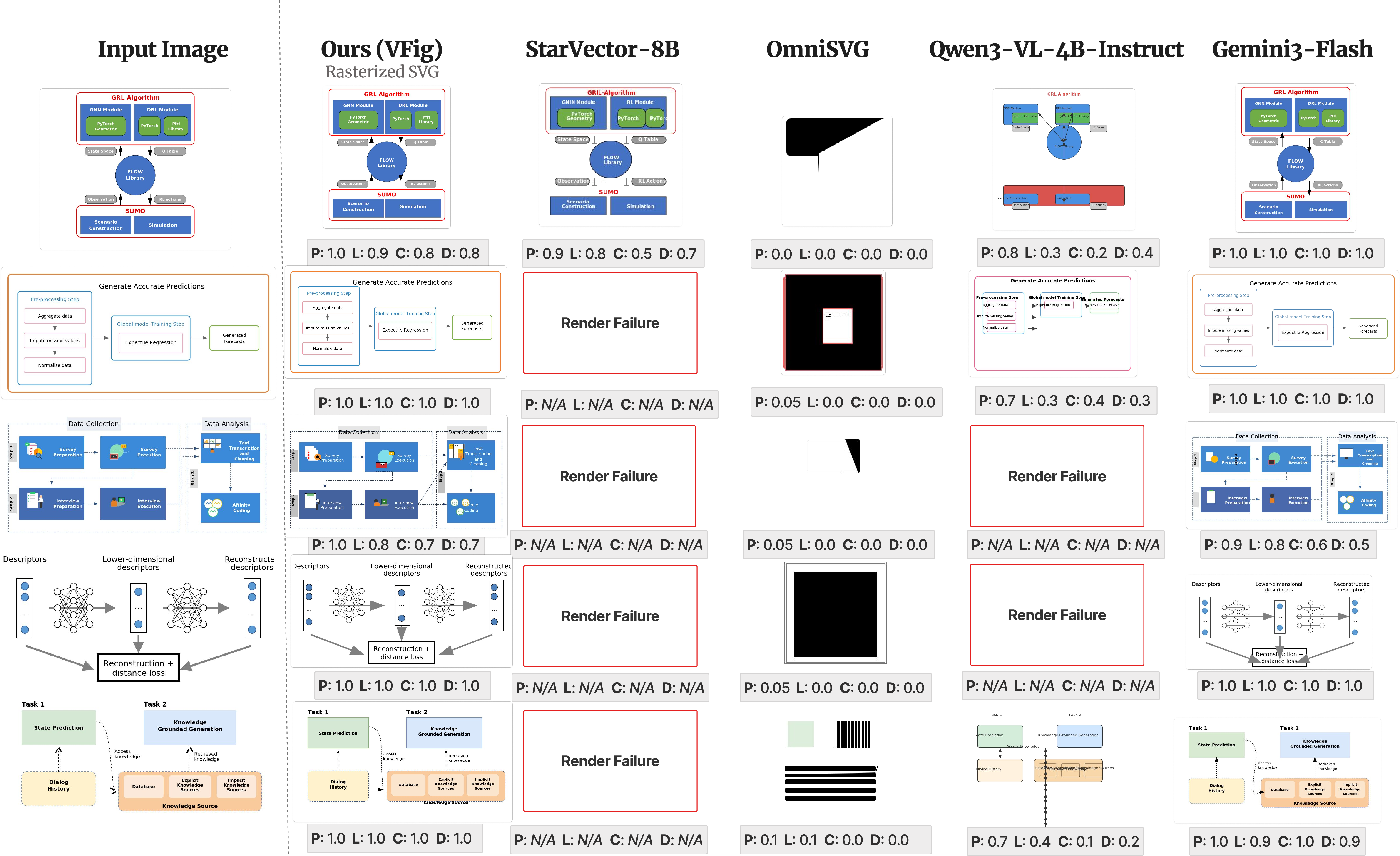
They built VFig-Bench, a test suite that checks quality at different levels:
- Pixel-level: Do the images look similar overall?
- Structure-level: Are the parts and connections correct (e.g., shapes and arrows match)?
- Human-like judgment: A smart AI judge (like Gemini/GPT) scores overall structure and details.
They also checked:
- SVG cleanliness: Does the code use simple shapes (good for editing) instead of huge messy paths?
- Render rate: Does the produced SVG actually work when you try to display it?
What did they discover?
Here are the main takeaways:
- VFig’s approach works very well on complex diagrams. Among open-source systems, it achieves the best balance of visual match, structural accuracy, clean SVG code, and reliable rendering.
- The “learn simple first, then complex” curriculum makes the AI more stable and better at composing full figures.
- Reinforcement learning with a structure-aware judge improves results further, especially on alignment, connectivity, and fine details.
- High-level, structure-focused feedback beats pure pixel matching. Two diagrams might look similar to the eye, but if arrows connect the wrong boxes, the structure-aware judge catches that—and optimizing for that leads to better, more useful SVGs.
- On their benchmark, VFig reaches a strong overall score (for example, a VLM-Judge score of about 0.829), performing on par with much larger commercial systems while being open-source.
Why this matters: Instead of just tracing outlines (which often yields tangled, hard-to-edit paths), VFig produces clean, editable shapes with organized structure—much closer to what a designer or researcher needs.
Why does this matter in the real world?
This research could:
- Save time: Quickly turn old or lost-diagram images into editable versions for updates or translations.
- Improve quality: Keep figures sharp at any size for papers, slides, and websites.
- Help collaboration: Clean, structured SVGs are easier for people and software tools to modify.
- Support education and accessibility: Teachers and students can reuse and adapt complex diagrams without redrawing them.
- Boost design tools: Future apps could include “import any diagram image and convert to SVG” with high accuracy.
In short, VFig shows that with the right data, training strategy, and evaluation, AI can reconstruct complex, professional diagrams as clean code—making scientific communication easier, faster, and more flexible.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to guide concrete follow‑up research.
Data and ground-truth fidelity
- Ground-truth SVGs for “real-world” figures are VLM-generated, not original authoring files; quantify and reduce inaccuracies or hallucinated structure introduced by the Gemini-based describe→generate pipeline.
- Training/evaluation images are rendered from those synthetic SVGs (not the original raster figures), sidestepping real-world artifacts (compression, anti-aliasing, scanning noise). Evaluate on truly in-the-wild rasters and measure robustness to noise and resolution changes.
- The dataset excludes plots, tables, natural images, and math-heavy figures; investigate methods and benchmarks for these common scientific components (e.g., chart parsers, LaTeX/math OCR, hybrid raster embedding) and quantify performance on them.
- Heuristic code filtering favors primitive-based SVGs and prunes path-heavy content; study generalization to legitimate path-dominated diagrams (curved arrows, free-form shapes, decorative elements) and whether the heuristics bias the learned representation.
- Coverage of multilingual text (non-English, RTL scripts), special characters, and domain-specific symbols is unreported; build multilingual subsets and evaluate text fidelity across languages and scripts.
- Advanced SVG features (filters, gradients, clip-paths, markers, patterns, transforms, complex text layout) are not characterized; enumerate feature coverage and test rendering/production under varied SVG engines.
- Font handling is programmatically controlled in synthetic data but under-specified for real figures; evaluate robustness to missing fonts, font substitutions, and typographic variability.
Modeling and training
- The vision encoder and multimodal projector are frozen during fine-tuning; quantify the gains (and costs) of unfreezing them or partially fine-tuning visual components for better layout/text recognition.
- Long-horizon generation is addressed primarily by filtering (sequence-length control) rather than modeling; explore planning-based, hierarchical, or segment-by-segment generation, and chunked decoding for very long SVGs (>8K tokens).
- Decoding is unconstrained; investigate grammar-constrained decoding, structural parsers, or constrained beam search to reduce syntax errors and boost render success without relying solely on RL.
- The RL reward depends on a closed-source VLM judge (Gemini); assess reward hacking and judge overfitting by (i) swapping judges (open-source reward models), (ii) cross-judge generalization, and (iii) larger-scale human evaluation.
- RL sample efficiency and stability are not explored beyond GRPO with n=8 rollouts; compare alternative policy optimization schemes (PPO/DPO, best-of-N, rejection sampling, self-critique/repair loops) and sampling budgets.
- No iterative repair or self-correction loop is used for syntax/layout errors; evaluate render→diagnose→edit cycles or tool-augmented decoding that patches local errors post-hoc.
- Text handling lacks explicit OCR or string-level supervision; add character/word-level metrics (edit distance, exact-match) and study OCR-assisted pipelines for higher text fidelity.
- Handling multi-panel figures is not explicitly modeled (e.g., panel detection, per-panel grouping, consistent alignment); design panel-aware generation and measurements for cross-panel consistency.
- Embedded raster support (<image> tags) is absent; extend the method to mixed raster–vector figures and define criteria for when to vectorize vs embed.
Evaluation and metrics
- Reliance on proprietary VLM judges (Gemini, GPT) threatens reproducibility and long-term stability; release or adopt open-source surrogates and report agreement with human raters at scale, including inter-annotator agreement.
- Human validation is limited (n=100) with moderate correlation for layout (r=0.63); expand human studies, report inter-rater reliability, and analyze failure modes by category (layout, connectivity, text).
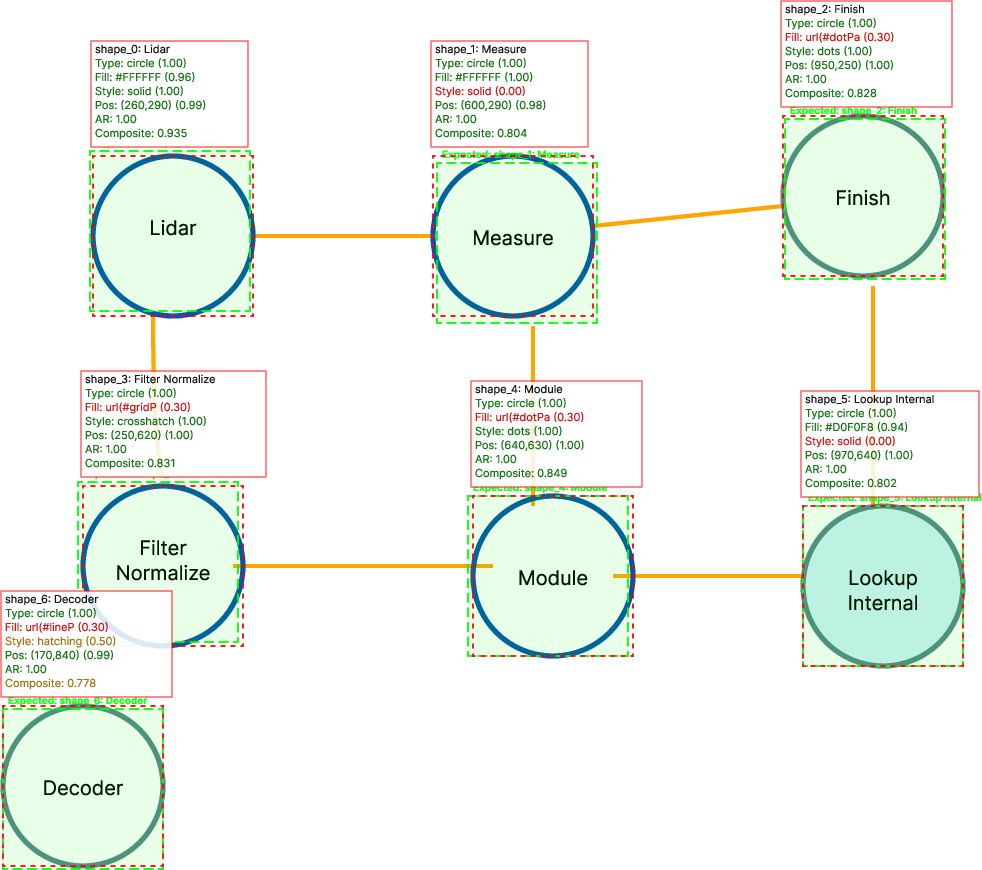
- “SVG cleanliness” (primitive ratio) is a coarse proxy for editability; introduce metrics for semantic hierarchy and editability such as:
- correctness of <g> grouping and nesting,
- z-order/layering accuracy,
- reuse via defs/symbols,
- attribute-level fidelity (stroke, markers, dash patterns).
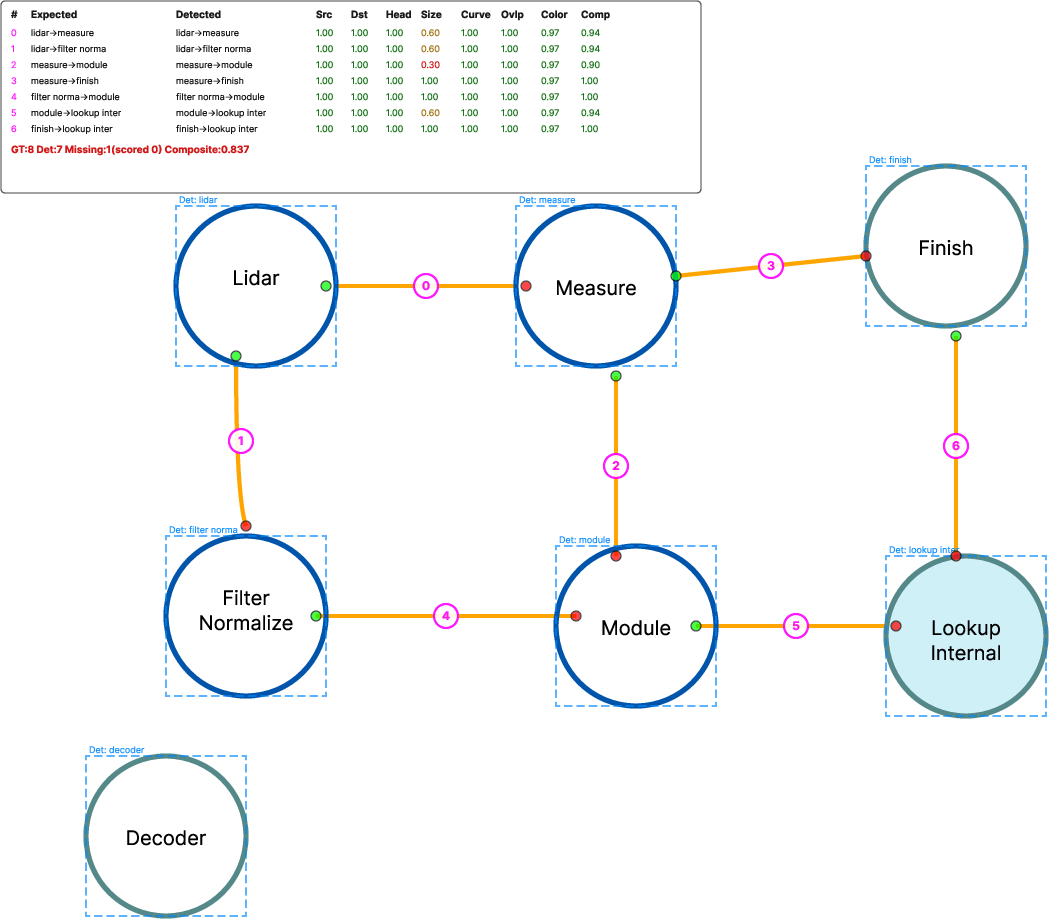
- Structural evaluation with rule-based matching is only available for synthetic diagrams; devise scalable structure-matching for real figures (e.g., detect boxes/arrows/text from the predicted SVG and align them to reference via geometry/text matching).
- Render success is measured with CairoSVG only; assess cross-renderer robustness (browser engines like Blink/WebKit/Gecko, Inkscape, rsvg-convert) and quantify discrepancies.
- Potential evaluation bias: the dataset and RL rewards use Gemini, which is also a judge; measure how results change when judges and data-generation backbones are orthogonal, and when judges are blinded to style cues.
Scope, generalization, and fairness of comparisons
- Generalization to unseen styles/domains (industry diagrams, education, design systems) and out-of-distribution layouts is not quantified; curate OOD test sets and stress-test style robustness.
- Comparisons penalize classical tracers on “cleanliness” though they optimize a different objective; provide blended evaluations that separately report (i) pixel similarity, (ii) structural correctness, and (iii) editability to avoid conflating goals.
- Backbone/scale ablations are limited; explore larger/smaller backbones, joint visual–text adaptation, and data scaling laws to quantify returns from model and data size.
Practicality and safety
- Inference latency, memory footprint, and throughput are not reported; profile end-to-end performance and provide speed–quality trade-offs for practical deployment.
- Security considerations are absent; define policies to sanitize generated SVG (e.g., disallow scripts/external links), and test against SVG-borne XSS or resource abuse.
- Integration in editing workflows is not assessed; evaluate the usability of generated SVGs in major vector editors (Inkscape, Illustrator, Figma) and measure time-to-edit or minimal-edit distance to target.
Directions for future methods
- Combine VLMs with differentiable rendering for precise geometric refinement of primitives (e.g., gradient-based snapping/alignment).
- Incorporate explicit planning or chain-of-thought for hierarchical and modular generation (e.g., scaffold layout → place panels → fill primitives).
- Develop hybrid pipelines for excluded subdomains:
- charts/plots via chart-specific parsers and plotting libraries,
- equations via LaTeX reconstruction and SVG text paths,
- natural-image insets via selective raster embedding.
- Learn when to vectorize vs raster-embed content, optimizing for editability, file size, and visual fidelity under mixed-content figures.
Glossary
- Actor–rollout–reference configuration: An RL training setup that uses separate actor, rollout, and reference policies, typically with a KL constraint to keep the learned policy close to a baseline. Example: "actorârolloutâreference configuration"
- Atomic primitives: The smallest, semantically meaningful SVG elements (e.g., rect, circle, line) that compose diagrams. Example: "learn atomic primitives"
- Bézier curves: Parametric curves commonly used to model smooth shapes in vector graphics and tracing. Example: "Bézier curves"
- CairoSVG: A library for rendering and converting SVGs to raster images used for evaluation and feedback. Example: "using CairoSVG"
- CLIP: A vision-LLM that produces image embeddings used for similarity-based evaluation. Example: "CLIP"
- Coarse-to-fine evaluation protocol: An assessment scheme that evaluates outputs at multiple granularities from low-level pixels to high-level structure. Example: "coarse-to-fine evaluation protocol"
- Coarse-to-fine training curriculum: A training strategy that starts on simpler cases and progressively moves to more complex ones to stabilize learning. Example: "coarse-to-fine training curriculum"
- Compositional reasoning: The capability to understand and generate structured diagrams composed of multiple interrelated parts. Example: "compositional reasoning"
- Compositional stability: Consistency in producing coherent, well-structured multi-component diagrams across examples. Example: "compositional stability"
- Cosine similarities: A vector similarity metric used to compare image embeddings for evaluating visual similarity. Example: "cosine similarities"
- DeepSVG: A hierarchical generative model for SVG command sequences used in prior work on vector graphics. Example: "DeepSVG"
- Differentiable rasterization: Rendering vector graphics to pixels in a way that supports gradients for optimization. Example: "Differentiable rasterization"
- Differentiable rendering: A rendering process that allows gradients to flow from raster losses back to vector parameters. Example: "differentiable rendering"
- DiffVG: A differentiable vector graphics renderer used for learning vector representations. Example: "DiffVG"
- DINO: A self-supervised vision model whose embeddings are used to measure image-level similarity. Example: "DINO"
- Entropy bonus: An RL regularizer that encourages exploration by increasing policy entropy. Example: "entropy bonus"
- GPT-5.2: A proprietary LLM used as a baseline and as a judge for evaluation. Example: "GPT-5.2"
- Group Relative Policy Optimization (GRPO): A policy-gradient method that computes advantages via group-wise comparisons without a separate reward model. Example: "Group Relative Policy Optimization (GRPO)"
- Im2Vec: A method that synthesizes vector graphics from images, often leveraging differentiable rendering. Example: "Im2Vec"
- KL regularization: Penalizing divergence from a reference policy during RL to maintain stability. Example: "KL regularization"
- Latent-variable model: A generative model that introduces hidden variables to capture underlying structure in data. Example: "latent-variable model"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method for large models. Example: "LoRA-based parameter-efficient fine-tuning"
- LPIPS: Learned Perceptual Image Patch Similarity, a perceptual metric for image comparison. Example: "LPIPS"
- Molmo2-Diagram: A diagram-focused subset/dataset used for training and evaluation. Example: "Molmo2-Diagram"
- Multimodal projector: A module that maps visual features into the LLM space for joint processing. Example: "multimodal projector"
- OmniSVG: A unified multimodal framework for tokenizing and generating SVG commands and coordinates. Example: "OmniSVG"
- Pearson correlation: A statistical measure of linear correlation used to validate alignment with human judgments. Example: "Pearson correlation"
- Policy drift: The tendency of a learned policy to deviate from a reference policy, often controlled by KL penalties. Example: "policy drift"
- Potrace: A classical raster-to-vector tracing algorithm that converts bitmaps into smooth paths. Example: "Potrace"
- Rendering-aware: Incorporating rendered-output feedback into training or reward design. Example: "rendering-aware"
- Reward hacking: Exploiting weaknesses in the reward function to achieve high scores without truly solving the task. Example: "reward hacking"
- Rubric-based VLM judge: A vision-LLM used to evaluate outputs along predefined rubric dimensions (e.g., presence, layout). Example: "rubric-based VLM judge"
- Rule-based evaluation: An assessment method using hand-crafted rules to match predicted and ground-truth structures. Example: "rule-based evaluation score"
- Semantic primitives: Meaningful, editable SVG elements (e.g., rect, circle, line) as opposed to free-form paths. Example: "semantic primitives"
- SigLIP: A model producing image embeddings used alongside CLIP and DINO for similarity measurements. Example: "SigLIP"
- SSIM: Structural Similarity Index Measure, a pixel-level metric for image similarity. Example: "SSIM"
- StarVector: A multimodal LLM approach focused on structured, semantic SVG generation. Example: "StarVector"
- Supervised fine-tuning (SFT): Training a pre-trained model on labeled examples to learn task-specific behavior. Example: "supervised fine-tuning (SFT)"
- SVG Cleanliness: A metric measuring the proportion of semantic primitives/connectors among geometric elements. Example: "SVG Cleanliness"
- SVG-Diagrams: A dataset emphasizing structured diagrams with text and discrete primitives. Example: "SVG-Diagrams"
- SVG-VAE: A variational autoencoder model for SVGs that decodes sequences of vector commands. Example: "SVG-VAE"
- Token explosion: Excessively long token sequences (e.g., from verbose paths) that hinder model processing. Example: "token explosion"
- Token-level likelihood: The objective optimized during language-model training that focuses on predicting next tokens. Example: "token-level likelihood"
- Tokenizer: The component that segments text/code into discrete tokens for model input. Example: "a VLM's tokenizer"
- Topological edge cases: Challenging structural situations involving connectivity and layout (e.g., unusual graph configurations). Example: "topological edge cases"
- Vectorization: Converting raster images into vector graphics representations. Example: "vectorization"
- VFig-Bench: A benchmark suite for evaluating figure-to-SVG generation with multi-granularity metrics. Example: "VFig-Bench"
- Vision–LLMs (VLMs): Models that jointly process visual and textual inputs for tasks like code generation from images. Example: "VisionâLLMs"
- VisualSim: An embedding-based visual similarity metric averaging DINO, CLIP, and SigLIP cosine similarities. Example: "VisualSim"
- VLM backbone: The underlying vision-LLM architecture used as the base for fine-tuning. Example: "VLM backbone"
- VLM-Judge: An aggregate score from VLM-based evaluators measuring semantic/structural correctness. Example: "VLM-Judge score"
- VTracer: A tracing-based raster-to-vector tool generating path-heavy vector outputs. Example: "VTracer"
- W3C-standard format: Refers to SVG being standardized by the World Wide Web Consortium, ensuring broad compatibility. Example: "W3C-standard format"
Practical Applications
Immediate Applications
Below are concrete, deployable ways to use VFig’s figure-to-SVG conversion, training recipe, and evaluation tools today.
- Sector(s): Publishing, Academia, Software/Design
- What you can do: Restore editable source for figures lost to PNG/JPEG by converting them into clean, semantic SVG primitives (rect, circle, line, text, groups).
- How to deploy now: Integrate VFig into editorial workflows (journal production, preprint curation) via an Inkscape/Illustrator/Figma plugin or a command-line batch tool; add a “Convert to SVG” action in CMS/knowledge bases (e.g., Confluence, SharePoint).
- Dependencies/assumptions: Best for diagram-centric figures (not photos/equations); requires GPU-backed inference for volume; ensure SVG sanitization for security.
- Sector(s): Education, Knowledge Management
- What you can do: Localize or update teaching diagrams by editing generated SVG text and shapes; scale figures to any size without pixelation.
- How to deploy now: LMS addons for Canvas/Moodle; a PowerPoint/Keynote plugin that converts pasted images to SVG; Notion/Obsidian extension for vectorizing embedded diagrams.
- Dependencies/assumptions: Font substitution may change appearance; multilingual labels supported if fonts are available; complex handwriting or dense math excluded by recommended filtering.
- Sector(s): Software Engineering, DevTools
- What you can do: Convert architecture diagrams from docs into editable vector graphics; optionally post-process SVG to graph formats (Mermaid, PlantUML, Graphviz DOT) using rule-based mapping.
- How to deploy now: GitHub Action that scans repository assets or READMEs, converts figures to SVG, and opens PRs; VS Code extension for “Vectorize diagram” in docs.
- Dependencies/assumptions: Accurate arrow connectivity and grouping depend on diagram clarity; robust mapping to non-SVG formats requires simple shape/link conventions.
- Sector(s): Enterprise Ops, Manufacturing, Finance, Energy
- What you can do: Modernize SOPs and process flows (org charts, BPMN-style diagrams, network diagrams) by recovering editable vectors from legacy PDFs/images for faster revisions and compliance updates.
- How to deploy now: Batch pipeline on document stores (S3/SharePoint) with routing to reviewers; plug into content migration projects (e.g., to new style guides).
- Dependencies/assumptions: Specialized symbols (e.g., P&ID, ISO icons) may need custom post-processing; privacy-sensitive deployments should run on-prem.
- Sector(s): Accessibility & Compliance (Public Sector, Higher Ed)
- What you can do: Improve accessibility by converting figures to semantic SVG that can be navigated by assistive technologies and scaled for low-vision users.
- How to deploy now: Add a “vectorize & tag” stage to PDF/UA or Section 508 remediation workflows; auto-generate alt-structure from SVG groups and labels.
- Dependencies/assumptions: Screen-reader benefit depends on preserving meaningful grouping/text; QA with human-in-the-loop recommended.
- Sector(s): Product Design (UI/UX), Media
- What you can do: Reverse engineer wireframes/diagrams into editable vectors for rapid iteration; clean up screenshots of whiteboard sketches or low-res assets.
- How to deploy now: Figma/Sketch plugins that import raster diagrams as SVG layers with groups and text; design system tooling that normalizes stroke/color styles.
- Dependencies/assumptions: Works best on clean diagrams; heavy texture or photo backgrounds should be filtered out.
- Sector(s): Security/Legal, Records Management
- What you can do: Enable precise redaction or brand/style harmonization by editing text and shapes directly in the SVG (instead of fuzzy bitmap edits).
- How to deploy now: Add VFig pre-processing before redaction/branding tools; implement policy checks (e.g., prohibited terms) on SVG text layers.
- Dependencies/assumptions: Enforce SVG sanitization to prevent script injection; align fonts and colors with corporate style tokens.
- Sector(s): ML/AI Tooling, Evaluation
- What you can do: Use VFig-Bench as a CI/QA suite to evaluate figure-to-SVG tools with structure-aware metrics; adopt the rubric (presence/layout/connectivity/details) for human-aligned scoring.
- How to deploy now: Add benchmark runs in CI; deploy a lightweight VLM-judge proxy for internal QA or sample-based audits.
- Dependencies/assumptions: Closed-source judges (e.g., Gemini/GPT) may require API usage; consider open-source alternatives for on-prem evaluation.
- Sector(s): ML Engineering
- What you can do: Apply the coarse-to-fine SFT curriculum and rendering-aware RL setup to other code-as-visual-output tasks (HTML/CSS layout, chart code generation).
- How to deploy now: Reuse the two-stage SFT→RL recipe; swap rewards to a rubric matched to your domain (e.g., DOM structure, chart semantics).
- Dependencies/assumptions: Requires a reliable renderer and a rubric-aligned judge; guard against reward hacking with KL regularization as in the paper.
Long-Term Applications
The following opportunities likely require additional research, scaling, or productization beyond the current release.
- Sector(s): Healthcare, Government, Regulated Industries
- What you could build: Automatic conversion of clinical pathways, public health flowcharts, and emergency procedures into computable process models (e.g., BPM+, FHIRPath) from raster figures.
- Potential workflow: VFig → SVG primitives → semantic graph extraction → export to BPMN/HL7 standards → validation loop with SMEs.
- Dependencies/assumptions: High accuracy on domain-specific symbology; validated mapping from geometry to semantics; governance for safety-critical use.
- Sector(s): EDA/CAD, Energy/Utilities
- What you could build: From electrical/circuit or P&ID diagrams to structured netlists or plant models by interpreting shapes/connectivity in SVG.
- Potential workflow: VFig → SVG → symbol library matching → topology extraction → export to SPICE, IEC/ISO formats.
- Dependencies/assumptions: Extensive symbol libraries and normalization; rigorous connectivity validation; tolerance for crowded, small glyphs.
- Sector(s): Business Process & RPA
- What you could build: One-click conversion of scanned business process diagrams into executable workflows (e.g., BPMN, Robotic Process Automation scripts).
- Potential workflow: VFig → SVG → BPMN/PlantUML translation → conformance check → deployment to workflow engines.
- Dependencies/assumptions: Reliable semantic interpretation of gateways, lanes, events; human oversight for compliance-critical deployments.
- Sector(s): Education Technology
- What you could build: Interactive, adaptive diagrams that retain structural semantics for step-by-step exploration or automatic personalization (e.g., auto-simplify for novices).
- Potential workflow: Vectorize → attach metadata (prerequisites, difficulty) → render interactive layers in web apps.
- Dependencies/assumptions: Requires robust grouping and naming conventions; content authoring tools to attach pedagogy metadata.
- Sector(s): Search/Knowledge Graphs
- What you could build: Semantic diagram search over large corpora (e.g., “find all figures with 3-stage pipelines and residual connections”).
- Potential workflow: VFig → SVG → extract graph features (shapes, links, layout) → index for structured retrieval and graph queries.
- Dependencies/assumptions: High-quality extraction of relationships; scalable indexing; privacy constraints for proprietary corpora.
- Sector(s): Web & App Development
- What you could build: Cross-format translation pipelines (raster diagram → semantic SVG → HTML/CSS/Canvas components or React/Figma components).
- Potential workflow: Vectorize → map primitives to UI components → attach constraints (flex/grid) → export code.
- Dependencies/assumptions: Requires stable alignment between SVG groups and UI component boundaries; renderer differences across browsers.
- Sector(s): Policy & Records, Open Government
- What you could build: Large-scale digitization and accessibility upgrades for archives (policy documents, standards, emergency plans), enforcing vector-based accessibility and updateability.
- Potential workflow: Batch vectorization → human QA → publish as accessible SVG/PDF-UA with structured tagging.
- Dependencies/assumptions: Procurement of on-prem solutions; strict data retention rules; standardized QA processes.
- Sector(s): Design Systems & Brand Management
- What you could build: Automated harmonization of legacy diagrams to brand guidelines (colors, fonts, strokes) through semantic restyling of generated SVG.
- Potential workflow: Vectorize → apply style tokens → auto-fix alignment/spacing via programmatic rules.
- Dependencies/assumptions: High SVG cleanliness and grouping to enable reliable style transformations; robust font availability.
- Sector(s): General Productivity/Daily Life
- What you could build: Mobile/desktop apps that vectorize whiteboard or notebook sketches into tidy diagrams; auto-generate editable study notes.
- Potential workflow: Capture → vectorize → suggest clean layouts/styles → export to slides or note-taking apps.
- Dependencies/assumptions: Performance on noisy photos must improve; handling of handwriting/math remains limited.
- Sector(s): ML Research
- What you could build: Generalized “render-then-judge” RL frameworks for tasks where outputs have visual semantics (charts, GUIs, plots), using structure-aware VLMs as reward models.
- Potential workflow: Domain renderer + VLM-based rubric → GRPO with KL control → deployable models for visual code synthesis.
- Dependencies/assumptions: Stable open-source judges for reproducibility; domain-specific rubric engineering; compute for RL sampling.
Notes on feasibility across applications:
- Model scope: The method is optimized for diagram-centric figures; natural images, heavy textures, and dense math are out of scope unless separately handled or filtered.
- Sequence limits: Extremely complex diagrams can exceed token budgets; may require chunking or future long-context backbones.
- Rendering parity: Differences between CairoSVG and browser renderers can affect appearance; testing across targets (web, print) is advised.
- Privacy/security: SVGs can embed scripts; sanitize outputs and support on-prem inference for sensitive documents.
- Licensing/availability: Open-source VFig weights and dataset availability will determine ease of adoption; judge reliance on proprietary APIs (for RL/QA) may need open alternatives for long-term sustainability.
Collections
Sign up for free to add this paper to one or more collections.

