- The paper shows that constrained decoding in LLM reflection imposes an alignment tax, reducing accuracy from 50% to 38%.
- It employs a 5-class taxonomy and finite-state constrained decoding to attribute root errors, focusing on early-stage failures.
- The study reveals that rigid schema constraints lead to structure snowballing, trapping models in formatting errors despite superficial corrections.
From Hallucination to Structure Snowballing: The Alignment Tax of Constrained Decoding in LLM Reflection
Introduction and Core Problem
This work systematically interrogates the limits of intrinsic self-correction in autoregressive LLMs, focusing on multi-hop reasoning tasks. Building on the Reflexion framework, which operationalizes agentic trial-and-error via language-based self-feedback, the paper investigates the recurrent phenomenon of “hallucination snowballing,” where early generation errors are recursively justified across reflections, leading to entrenched incorrect reasoning. Prior work posits that structured (typed, schema-controlled) reflection mitigates such error cascades. Most implementations, however, depend on external critics or symbolic tools, introducing extrinsic supervision and undermining agent autonomy.
The central research question here is whether imposing structure—enforcing an explicit taxonomy of reasoning errors during reflection purely through decoding-time constraints—can independently break the hallucination chain, thereby improving self-correction with no auxiliary models or training data. The Qwen3-8B model anchors experimentation, with OUTLINES-style finite-state constrained decoding enabling taxonomy-aligned reflections.
Methodology: Taxonomy, Attribution, and the Constrained Decoding Mechanism
The study operationalizes self-correction with an explicit 5-class taxonomy: retrieval_focus, bridge_failure, hallucination, inference_error, and formatting_mismatch. An “upstream-first” attribution principle ensures only the earliest-sequence failure is annotated, targeting the root error rather than downstream symptoms—a design motivated by trace-based error propagation analyses and the BIG-Bench Mistake dataset paradigm.
Central to the approach is logic-guided constrained decoding: the OUTLINES library masks decoding distributions to admit only outputs conforming to a predefined Pydantic schema, guaranteeing 100% syntactic alignment at the FSM level. The architecture comprises three agents: Actor (initial answer), Evaluator (binary reward vs. gold), and Reflector (structured error attribution via constrained decoding). Episodic memory accumulates structured reflections, closing the agentic feedback loop.
Critically, this approach obviates the need for external critics or additional training, enabling the analysis of “alignment tax” and computational overheads as a function of imposed reflectivity structure.
Experimental Protocol and Data Curation
HotpotQA’s distractor setting provides a rigorous multi-hop evaluation substrate, but dataset curation is essential due to shortcut exploitation by high-accuracy LLMs. An LLM-as-a-judge framework (with Qwen3-8B in both Actor and Evaluator roles) augments standard EM/F1 matching, filtering out brittle, non-semantic failures.
Evaluation proceeds on two pools: Pool A contains cases solved after several trials (AT as primary metric), while Pool B comprises persistent failures in the Reflexion baseline (Success Rate as primary metric). Controlled, low-temperature sampling and taxonomy-strict attribution are applied throughout.
Results: Quantitative and Qualitative Analysis
Imposing structural constraints via logic-guided decoding induces a net accuracy drop from 50.0% to 38.0%, attributable to an “alignment tax.” The transition analysis reveals 23 degraded cases (Correct→Wrong) when moving to structured constraints; a subset (11 cases) improves (Wrong→Correct), evidencing that structure can break certain local minima related to coherence-inducing hallucinations.
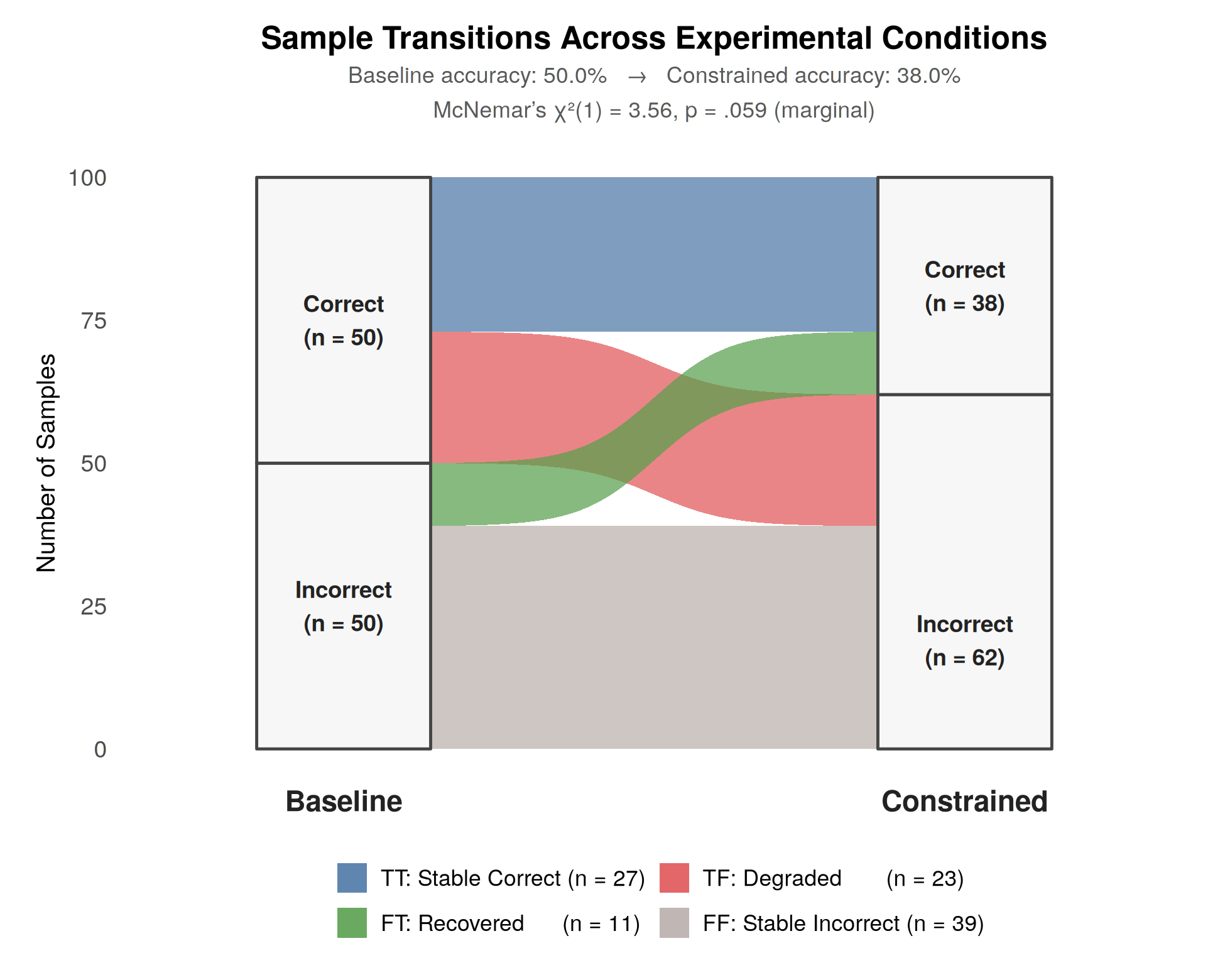
Figure 1: Alluvial diagram of status transitions between free-text and constrained reflection settings, highlighting the degradation and recovery patterns.
Token consumption analyses reveal significantly higher resource usage in degraded cases (average 4,005.5 tokens vs. 2,850 in stable success cases), empirically confirming that strict syntax adherence diverts model capacity from semantic reasoning to surface alignment. This effect is most pronounced in the “TF” transition group.
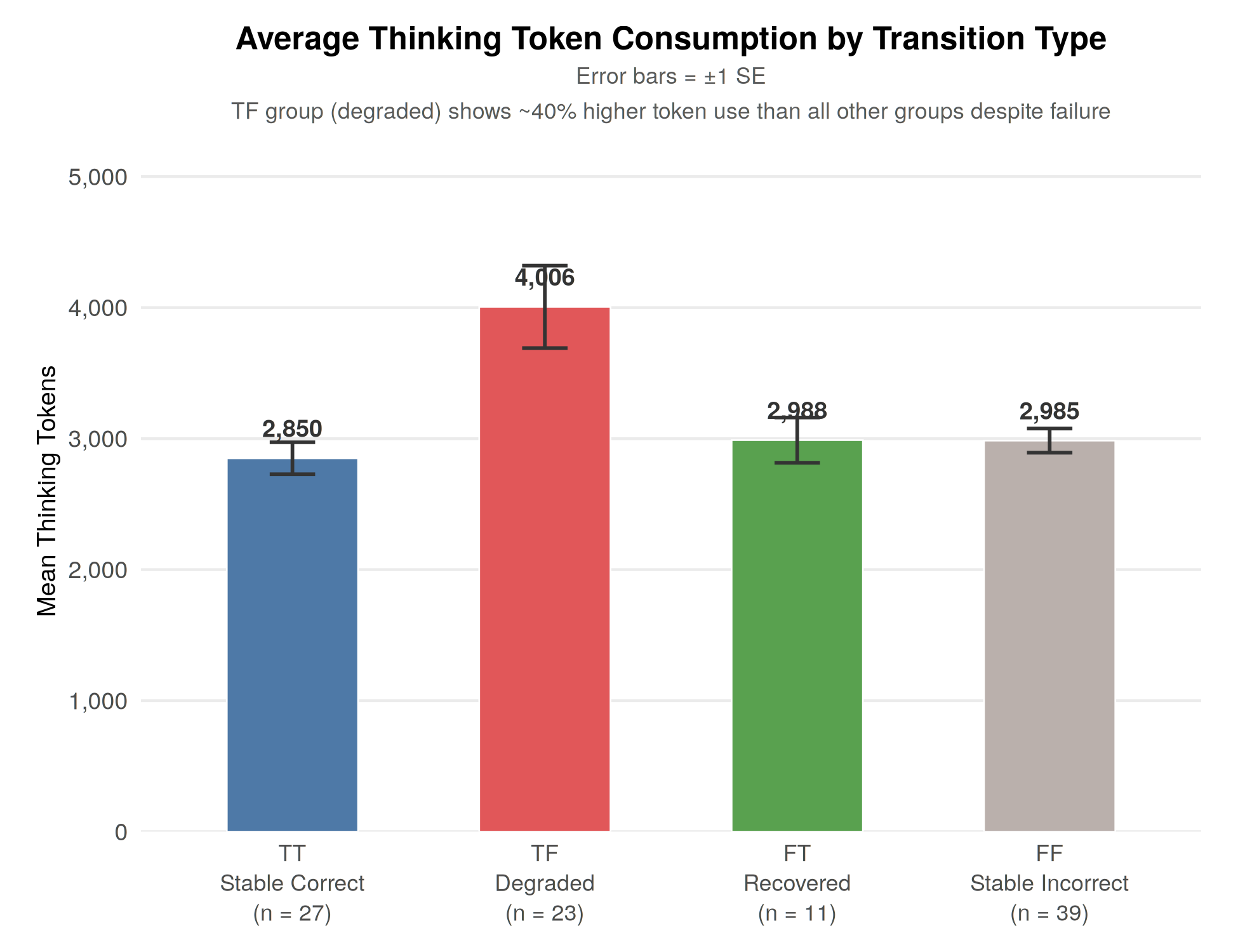
Figure 2: Bar chart of average token consumption stratified by transition group, quantifying the alignment tax imposed by rigid schema constraints.
Error trajectory plotting demonstrates that 96% of structured reflections default to FORMATTING_MISMATCH, trapping a majority of samples in repeated death loops focused on surface compliance, with minimal identification of retrieval or inference-level errors. This validates the “Error Depth Hypothesis”: taxonomy pressure induces shallow error patching, masking deeper cognitive failures.
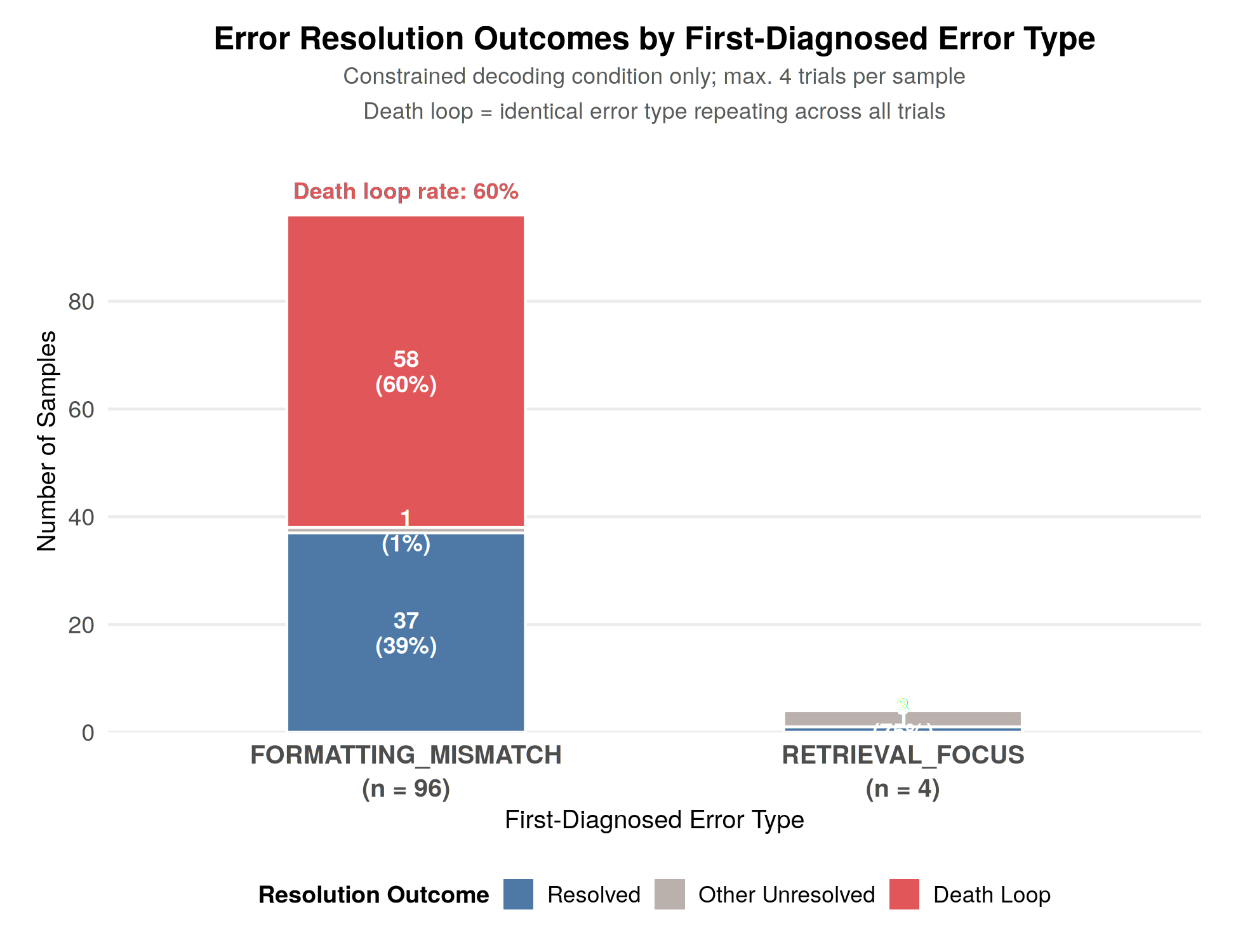
Figure 3: Distribution of error type attributions under constrained decoding, showing overwhelming dominance of formatting issues.
Qualitative case studies further delineate failure dynamics. For shallow alignment errors (e.g., omission of a required string in output format), forced constraints enable effective correction—structured rules directly guide the Actor past string-matching pitfalls. Conversely, when initial failures are logical or retrieval-based, structure snowballing occurs: the model persists in surface-format advice, unable to redirect attention to deeper faults without semantic flexibility.
Theoretical and Practical Implications
This investigation demonstrates that structure imposition at the decoding layer, without auxiliary critics or additional training, is insufficient for robust intrinsic error correction in current (8B-range) models. Instead, it creates an “alignment tax”: the model’s attention is saturated by syntactic constraints, increasing token consumption, while surface-level compliance is prioritized over genuine reasoning flaw detection. The phenomenon of structure snowballing is the structural analogue of hallucination snowballing; it emerges when rigid taxonomies trap the model in non-semantic error loops.
These findings challenge the prevailing assumption that structuring self-reflection is universally beneficial in autonomous agent architectures. They highlight the necessity of either scaling model capacity (to enable simultaneous syntactic and semantic reflection) or integrating dynamic fallback mechanisms—such as intermittent relaxation of schema constraints or incorporation of search/backtracking approaches (e.g., Tree of Thoughts (Yao et al., 2023))—to escape formatting death loops.
Pragmatically, these results delimit the usefulness of constrained decoding for schema alignment in lightweight models, while reinforcing its value for evaluation scenarios where brittle string-matching dominates.
Limitations and Directions for Future Research
The study is fundamentally limited by its focus on the Qwen3-8B model class. Scaling laws remain untested: it is plausible that much larger models (70B+) possess sufficient latent capacity for simultaneous syntax and semantic error localization under rigid constraints. The use of static, string-match-sensitive datasets (e.g., HotpotQA) also accentuates formatting mismatch traps, potentially underestimating the prevalence of genuine semantic corrections.
For future work, dynamic benchmarks with execution-based or multi-faceted semantic evaluation are imperative. Integrating adaptive constraint mechanisms—where constraint application is context-sensitive or interruptible—could alleviate structure snowballing. Additionally, hybrid architectures coupling constrained decoding with lightweight external error-localization modules might restore the agent’s capacity for deep reflection without full reliance on large-scale critic models.
Conclusion
This study rigorously demonstrates that decoding-time enforcement of structured reflection, in the absence of specialized critics, does not guarantee improved self-correction in LLMs. Instead, it introduces a quantifiable alignment tax, engendering a new failure regime—structure snowballing—especially apparent in mid-sized models. The work reframes how structured feedback and agent autonomy should be balanced for effective intrinsic error correction, catalyzing further investigation into adaptive constraint strategies and model scaling effects for robust self-reasoning.

